 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd4: End-to-end Denoising Diffusion for Diffusion-Based Inpainting Detection
Sep 16, 2025The powerful generative capabilities of diffusion models have significantly advanced the field of image synthesis, enhancing both full image generation and inpainting-based image editing. Despite their remarkable advancements, diffusion models also raise concerns about potential misuse for malicious purposes. However, existing approaches struggle to identify images generated by diffusion-based inpainting models, even when similar inpainted images are included in their training data. To address this challenge, we propose a novel detection method based on End-to-end denoising diffusion (End4). Specifically, End4 designs a denoising reconstruction model to improve the alignment degree between the latent spaces of the reconstruction and detection processes, thus reconstructing features that are more conducive to detection. Meanwhile, it leverages a Scale-aware Pyramid-like Fusion Module (SPFM) that refines local image features under the guidance of attention pyramid layers at different scales, enhancing feature discriminability. Additionally, to evaluate detection performance on inpainted images, we establish a comprehensive benchmark comprising images generated from five distinct masked regions. Extensive experiments demonstrate that our End4 effectively generalizes to unseen masking patterns and remains robust under various perturbations. Our code and dataset will be released soon.
AD-AVSR: Asymmetric Dual-stream Enhancement for Robust Audio-Visual Speech Recognition
Aug 11, 2025Audio-visual speech recognition (AVSR) combines audio-visual modalities to improve speech recognition, especially in noisy environments. However, most existing methods deploy the unidirectional enhancement or symmetric fusion manner, which limits their capability to capture heterogeneous and complementary correlations of audio-visual data-especially under asymmetric information conditions. To tackle these gaps, we introduce a new AVSR framework termed AD-AVSR based on bidirectional modality enhancement. Specifically, we first introduce the audio dual-stream encoding strategy to enrich audio representations from multiple perspectives and intentionally establish asymmetry to support subsequent cross-modal interactions. The enhancement process involves two key components, Audio-aware Visual Refinement Module for enhanced visual representations under audio guidance, and Cross-modal Noise Suppression Masking Module which refines audio representations using visual cues, collaboratively leading to the closed-loop and bidirectional information flow. To further enhance correlation robustness, we adopt a threshold-based selection mechanism to filter out irrelevant or weakly correlated audio-visual pairs. Extensive experimental results on the LRS2 and LRS3 datasets indicate that our AD-AVSR consistently surpasses SOTA methods in both performance and noise robustness, highlighting the effectiveness of our model design.
eMotions: A Large-Scale Dataset and Audio-Visual Fusion Network for Emotion Analysis in Short-form Videos
Aug 09, 2025Short-form videos (SVs) have become a vital part of our online routine for acquiring and sharing information. Their multimodal complexity poses new challenges for video analysis, highlighting the need for video emotion analysis (VEA) within the community. Given the limited availability of SVs emotion data, we introduce eMotions, a large-scale dataset consisting of 27,996 videos with full-scale annotations. To ensure quality and reduce subjective bias, we emphasize better personnel allocation and propose a multi-stage annotation procedure. Additionally, we provide the category-balanced and test-oriented variants through targeted sampling to meet diverse needs. While there have been significant studies on videos with clear emotional cues (e.g., facial expressions), analyzing emotions in SVs remains a challenging task. The challenge arises from the broader content diversity, which introduces more distinct semantic gaps and complicates the representations learning of emotion-related features. Furthermore, the prevalence of audio-visual co-expressions in SVs leads to the local biases and collective information gaps caused by the inconsistencies in emotional expressions. To tackle this, we propose AV-CANet, an end-to-end audio-visual fusion network that leverages video transformer to capture semantically relevant representations. We further introduce the Local-Global Fusion Module designed to progressively capture the correlations of audio-visual features. Besides, EP-CE Loss is constructed to globally steer optimizations with tripolar penalties. Extensive experiments across three eMotions-related datasets and four public VEA datasets demonstrate the effectiveness of our proposed AV-CANet, while providing broad insights for future research. Moreover, we conduct ablation studies to examine the critical components of our method. Dataset and code will be made available at Github.
HOLA: Enhancing Audio-visual Deepfake Detection via Hierarchical Contextual Aggregations and Efficient Pre-training
Jul 30, 2025Advances in Generative AI have made video-level deepfake detection increasingly challenging, exposing the limitations of current detection techniques. In this paper, we present HOLA, our solution to the Video-Level Deepfake Detection track of 2025 1M-Deepfakes Detection Challenge. Inspired by the success of large-scale pre-training in the general domain, we first scale audio-visual self-supervised pre-training in the multimodal video-level deepfake detection, which leverages our self-built dataset of 1.81M samples, thereby leading to a unified two-stage framework. To be specific, HOLA features an iterative-aware cross-modal learning module for selective audio-visual interactions, hierarchical contextual modeling with gated aggregations under the local-global perspective, and a pyramid-like refiner for scale-aware cross-grained semantic enhancements. Moreover, we propose the pseudo supervised singal injection strategy to further boost model performance. Extensive experiments across expert models and MLLMs impressivly demonstrate the effectiveness of our proposed HOLA. We also conduct a series of ablation studies to explore the crucial design factors of our introduced components. Remarkably, our HOLA ranks 1st, outperforming the second by 0.0476 AUC on the TestA set.
HKD4VLM: A Progressive Hybrid Knowledge Distillation Framework for Robust Multimodal Hallucination and Factuality Detection in VLMs
Jun 16, 2025Driven by the rapid progress in vision-language models (VLMs), the responsible behavior of large-scale multimodal models has become a prominent research area, particularly focusing on hallucination detection and factuality checking. In this paper, we present the solution for the two tracks of Responsible AI challenge. Inspirations from the general domain demonstrate that a smaller distilled VLM can often outperform a larger VLM that is directly tuned on downstream tasks, while achieving higher efficiency. We thus jointly tackle two tasks from the perspective of knowledge distillation and propose a progressive hybrid knowledge distillation framework termed HKD4VLM. Specifically, the overall framework can be decomposed into Pyramid-like Progressive Online Distillation and Ternary-Coupled Refinement Distillation, hierarchically moving from coarse-grained knowledge alignment to fine-grained refinement. Besides, we further introduce the mapping shift-enhanced inference and diverse augmentation strategies to enhance model performance and robustness. Extensive experimental results demonstrate the effectiveness of our HKD4VLM. Ablation studies provide insights into the critical design choices driving performance gains.
ViC-Bench: Benchmarking Visual-Interleaved Chain-of-Thought Capability in MLLMs with Free-Style Intermediate State Representations
May 20, 2025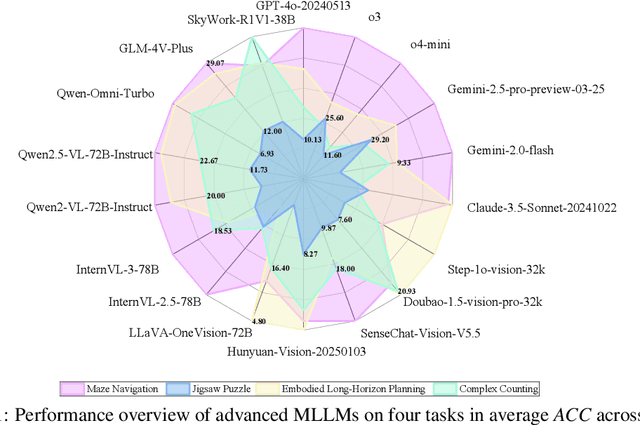

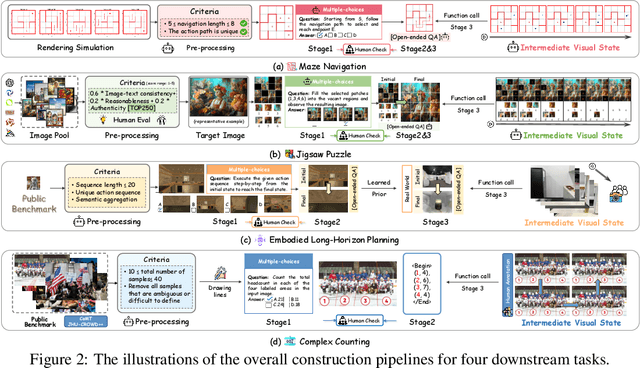
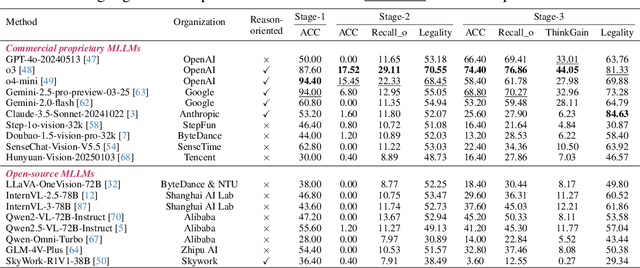
Visual-Interleaved Chain-of-Thought (VI-CoT) enables MLLMs to continually update their understanding and decisions based on step-wise intermediate visual states (IVS), much like a human would, which demonstrates impressive success in various tasks, thereby leading to emerged advancements in related benchmarks. Despite promising progress, current benchmarks provide models with relatively fixed IVS, rather than free-style IVS, whch might forcibly distort the original thinking trajectories, failing to evaluate their intrinsic reasoning capabilities. More importantly, existing benchmarks neglect to systematically explore the impact factors that IVS would impart to untamed reasoning performance. To tackle above gaps, we introduce a specialized benchmark termed ViC-Bench, consisting of four representive tasks: maze navigation, jigsaw puzzle, embodied long-horizon planning, and complex counting, where each task has dedicated free-style IVS generation pipeline supporting function calls. To systematically examine VI-CoT capability, we propose a thorough evaluation suite incorporating a progressive three-stage strategy with targeted new metrics. Besides, we establish Incremental Prompting Information Injection (IPII) strategy to ablatively explore the prompting factors for VI-CoT. We extensively conduct evaluations for 18 advanced MLLMs, revealing key insights into their VI-CoT capability. Our proposed benchmark is publicly open at Huggingface.
3A-YOLO: New Real-Time Object Detectors with Triple Discriminative Awareness and Coordinated Representations
Dec 10, 2024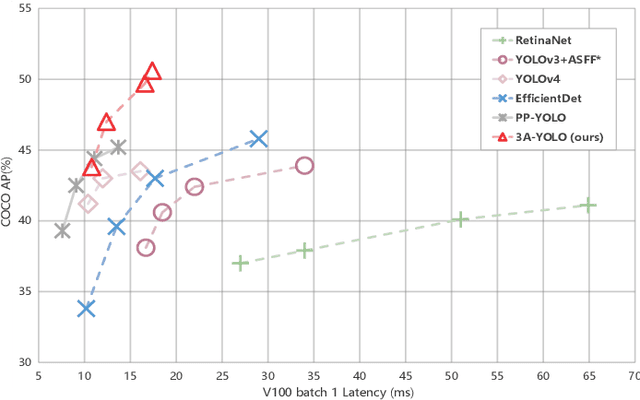
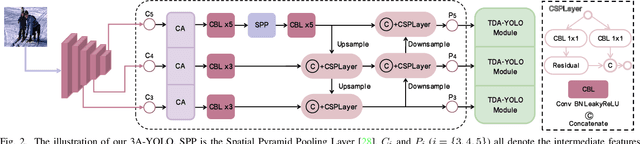
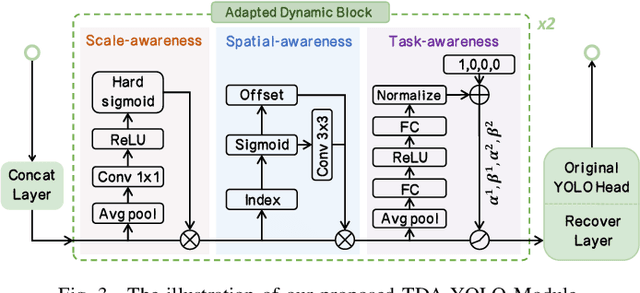
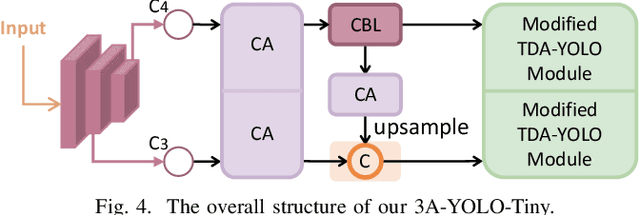
Recent research on real-time object detectors (e.g., YOLO series) has demonstrated the effectiveness of attention mechanisms for elevating model performance. Nevertheless, existing methods neglect to unifiedly deploy hierarchical attention mechanisms to construct a more discriminative YOLO head which is enriched with more useful intermediate features. To tackle this gap, this work aims to leverage multiple attention mechanisms to hierarchically enhance the triple discriminative awareness of the YOLO detection head and complementarily learn the coordinated intermediate representations, resulting in a new series detectors denoted 3A-YOLO. Specifically, we first propose a new head denoted TDA-YOLO Module, which unifiedly enhance the representations learning of scale-awareness, spatial-awareness, and task-awareness. Secondly, we steer the intermediate features to coordinately learn the inter-channel relationships and precise positional information. Finally, we perform neck network improvements followed by introducing various tricks to boost the adaptability of 3A-YOLO. Extensive experiments across COCO and VOC benchmarks indicate the effectiveness of our detectors.