 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSER Evals: In-domain and Out-of-domain Benchmarking for Speech Emotion Recognition
Aug 14, 2024



Speech emotion recognition (SER) has made significant strides with the advent of powerful self-supervised learning (SSL) models. However, the generalization of these models to diverse languages and emotional expressions remains a challenge. We propose a large-scale benchmark to evaluate the robustness and adaptability of state-of-the-art SER models in both in-domain and out-of-domain settings. Our benchmark includes a diverse set of multilingual datasets, focusing on less commonly used corpora to assess generalization to new data. We employ logit adjustment to account for varying class distributions and establish a single dataset cluster for systematic evaluation. Surprisingly, we find that the Whisper model, primarily designed for automatic speech recognition, outperforms dedicated SSL models in cross-lingual SER. Our results highlight the need for more robust and generalizable SER models, and our benchmark serves as a valuable resource to drive future research in this direction.
Towards Generalizable SER: Soft Labeling and Data Augmentation for Modeling Temporal Emotion Shifts in Large-Scale Multilingual Speech
Nov 15, 2023Recognizing emotions in spoken communication is crucial for advanced human-machine interaction. Current emotion detection methodologies often display biases when applied cross-corpus. To address this, our study amalgamates 16 diverse datasets, resulting in 375 hours of data across languages like English, Chinese, and Japanese. We propose a soft labeling system to capture gradational emotional intensities. Using the Whisper encoder and data augmentation methods inspired by contrastive learning, our method emphasizes the temporal dynamics of emotions. Our validation on four multilingual datasets demonstrates notable zero-shot generalization. We publish our open source model weights and initial promising results after fine-tuning on Hume-Prosody.
MU-MIMO Grouping For Real-time Applications
Jul 26, 2021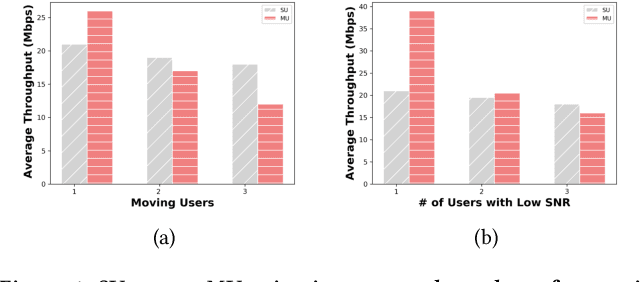
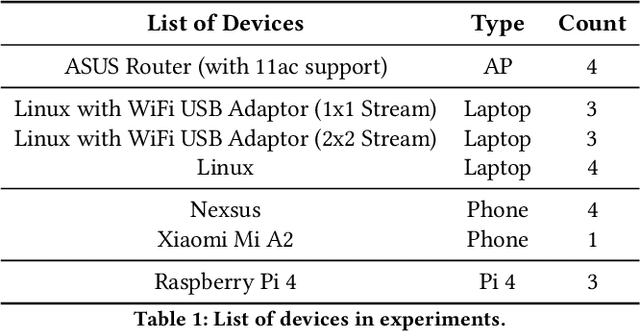
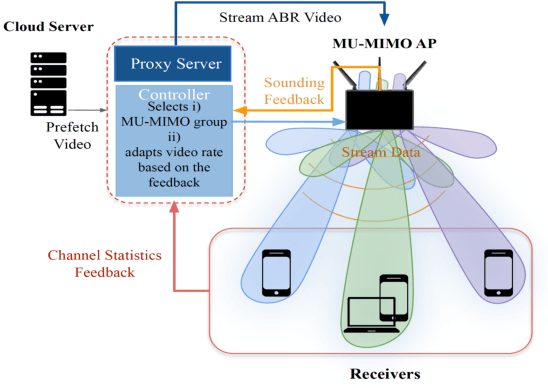
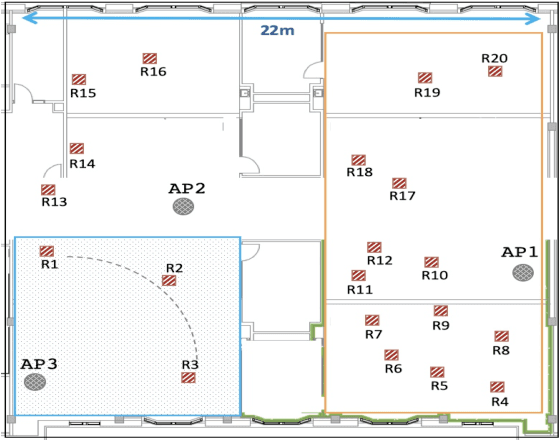
Over the last decade, the bandwidth expansion and MU-MIMO spectral efficiency have promised to increase data throughput by allowing concurrent communication between one Access Point and multiple users. However, we are still a long way from enjoying such MU-MIMO MAC protocol improvements for bandwidth hungry applications such as video streaming in practical WiFi network settings due to heterogeneous channel conditions and devices, unreliable transmissions, and lack of useful feedback exchange among the lower and upper layers' requirements. This paper introduces MuViS, a novel dual-phase optimization framework that proposes a Quality of Experience (QoE) aware MU-MIMO optimization for multi-user video streaming over IEEE 802.11ac. MuViS first employs reinforcement learning to optimize the MU-MIMO user group and mode selection for users based on their PHY/MAC layer characteristics. The video bitrate is then optimized based on the user's mode (Multi-User (MU) or Single-User (SU)). We present our design and its evaluation on smartphones and laptops using 802.11ac WiFi. Our experimental results in various indoor environments and configurations show a scalable framework that can support a large number of users with streaming at high video rates and satisfying QoE requirements.
Unboxing MAC Protocol Design Optimization Using Deep Learning
Feb 06, 2020



Evolving amendments of 802.11 standards feature a large set of physical and MAC layer control parameters to support the increasing communication objectives spanning application requirements and network dynamics. The significant growth and penetration of various devices come along with a tremendous increase in the number of applications supporting various domains and services which will impose a never-before-seen burden on wireless networks. The challenge however, is that each scenario requires a different wireless protocol functionality and parameter setting to optimally determine how to tune these functionalities and parameters to adapt to varying network scenarios. The traditional trial-error approach of manual tuning of parameters is not just becoming difficult to repeat but also sub-optimal for different networking scenarios. In this paper, we describe how we can leverage a deep reinforcement learning framework to be trained to learn the relation between different parameters in the physical and MAC layer and show that how our learning-based approach could help us in getting insights about protocol design optimization task.
MAC Protocol Design Optimization Using Deep Learning
Feb 06, 2020



Deep learning (DL)-based solutions have recently been developed for communication protocol design. Such learning-based solutions can avoid manual efforts to tune individual protocol parameters. While these solutions look promising, they are hard to interpret due to the black-box nature of the ML techniques. To this end, we propose a novel DRL-based framework to systematically design and evaluate networking protocols. While other proposed ML-based methods mainly focus on tuning individual protocol parameters (e.g., adjusting contention window), our main contribution is to decouple a protocol into a set of parametric modules, each representing a main protocol functionality and is used as DRL input to better understand the generated protocols design optimization and analyze them in a systematic fashion. As a case study, we introduce and evaluate DeepMAC a framework in which a MAC protocol is decoupled into a set of blocks across popular flavors of 802.11 WLANs (e.g., 802.11a/b/g/n/ac). We are interested to see what blocks are selected by DeepMAC across different networking scenarios and whether DeepMAC is able to adapt to network dynamics.
CONVINCE: Collaborative Cross-Camera Video Analytics at the Edge
Feb 05, 2020



Today, video cameras are deployed in dense for monitoring physical places e.g., city, industrial, or agricultural sites. In the current systems, each camera node sends its feed to a cloud server individually. However, this approach suffers from several hurdles including higher computation cost, large bandwidth requirement for analyzing the enormous data, and privacy concerns. In dense deployment, video nodes typically demonstrate a significant spatio-temporal correlation. To overcome these obstacles in current approaches, this paper introduces CONVINCE, a new approach to look at the network cameras as a collective entity that enables collaborative video analytics pipeline among cameras. CONVINCE aims at 1) reducing the computation cost and bandwidth requirements by leveraging spatio-temporal correlations among cameras in eliminating redundant frames intelligently, and ii) improving vision algorithms' accuracy by enabling collaborative knowledge sharing among relevant cameras. Our results demonstrate that CONVINCE achieves an object identification accuracy of $\sim$91\%, by transmitting only about $\sim$25\% of all the recorded frames.