 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn In-router Identification Scheme for Selective Discard of Video Packets
Apr 27, 2021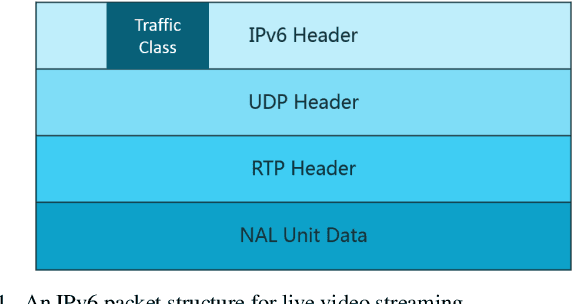

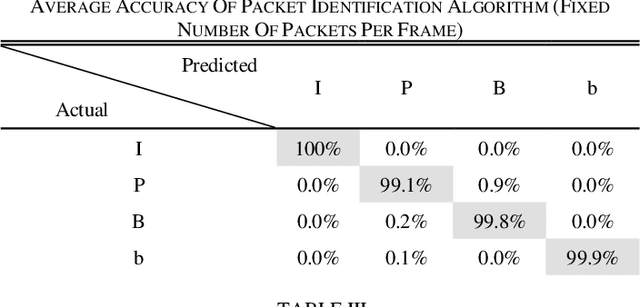
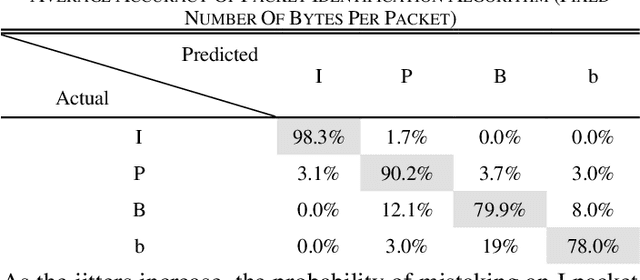
High quality (HQ) video services occupy large portions of the total bandwidth and are among the main causes of congestion at network bottlenecks. Since video is resilient to data loss, throwing away less important video packets can ease network congestion with minimal damage to video quality and free up bandwidth for other data flows. Frame type is one of the features that can be used to determine the importance of video packets, but this information is stored in the packet payload. Due to limited processing power of devices in high throughput/speed networks, data encryption and user credibility issues, it is costly for the network to find the frame type of each packet. Therefore, a fast and reliable standalone method to recognize video packet types at network level is desired. This paper proposes a method to model the structure of live video streams in a network node which results in determining the frame type of each packet. It enables the network nodes to mark and if need be to discard less important video packets ahead of congestion, and therefore preserve video quality and free up bandwidth for more important packet types. The method does not need to read the IP layer payload and uses only the packet header data for decisions. Experimental results indicate while dropping packets under packet type prediction degrades video quality with respect to its true type by 0.5-3 dB, it has 7-20 dB improvement over when packets are dropped randomly.
Improving precision of objective image/video quality metrics
Apr 26, 2021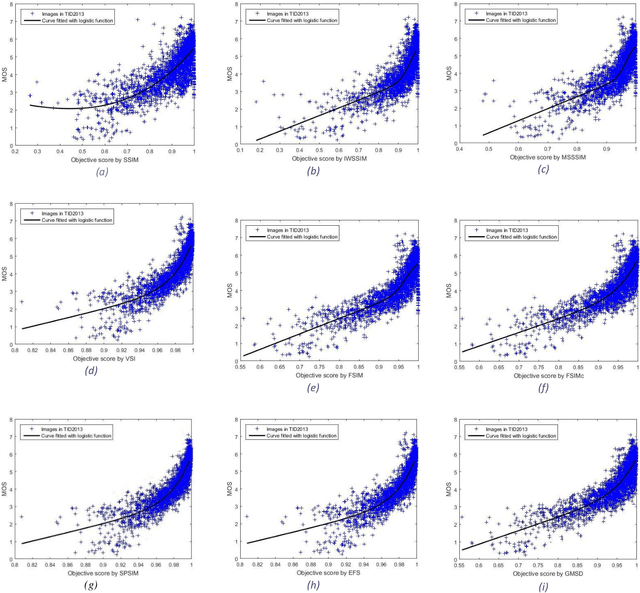
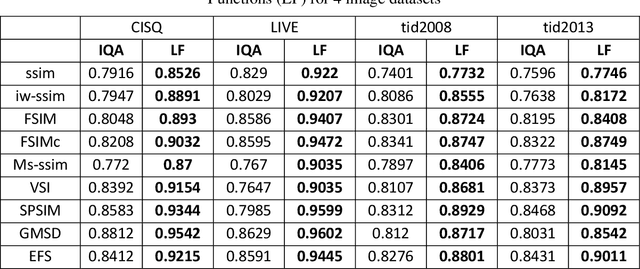
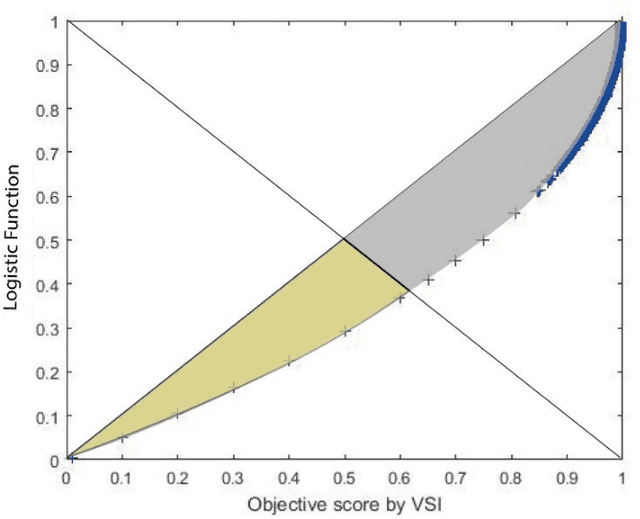
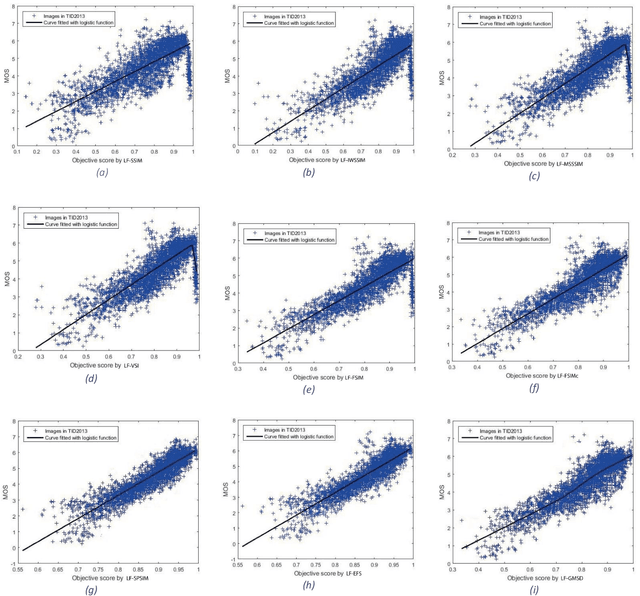
Although subjective tests are most accurate image/video quality assessment tools, they are extremely time demanding. In the past two decades, a variety of objective tools, such as SSIM, IW-SSIM, SPSIM, FSIM, etc., have been devised, that well correlate with the subjective tests results. However, the main problem with these methods is that, they do not discriminate the measured quality well enough, especially at high quality range. In this article we show how the accuracy/precision of these Image Quality Assessment (IQA) meters can be increased by mapping them into a Logistic Function (LF). The precisions are tested over a variety of image/video databases. Our experimental tests indicate while the used high-quality images can be discriminated by 23% resolution on the MOS subjective scores, discrimination resolution by the widely used IQAs are only 2%, but their mapped IQAs to Logistic Function at this quality range can be improved to 9.4%. Moreover, their precision at low to mid quality range can also be improved. At this quality range, while the discrimination resolution of MOS of the tested images is 23.2%, those of raw IQAs is nearly 8.9%, but their adapted logistic functions can lead to 17.7%, very close to that of MOS. Moreover, with the used image databases the Pearson correlation of MOS with the logistic function can be improved by 2%-20.2% as well.
Fast and Efficient Lenslet Image Compression
Jan 27, 2019

Light field imaging is characterized by capturing brightness, color, and directional information of light rays in a scene. This leads to image representations with huge amount of data that require efficient coding schemes. In this paper, lenslet images are rendered into sub-aperture images. These images are organized as a pseudo-sequence input for the HEVC video codec. To better exploit redundancy among the neighboring sub-aperture images and consequently decrease the distances between a sub-aperture image and its references used for prediction, sub-aperture images are divided into four smaller groups that are scanned in a serpentine order. The most central sub-aperture image, which has the highest similarity to all the other images, is used as the initial reference image for each of the four regions. Furthermore, a structure is defined that selects spatially adjacent sub-aperture images as prediction references with the highest similarity to the current image. In this way, encoding efficiency increases, and furthermore it leads to a higher similarity among the co-located Coding Three Units (CTUs). The similarities among the co-located CTUs are exploited to predict Coding Unit depths.Moreover, independent encoding of each group division enables parallel processing, that along with the proposed coding unit depth prediction decrease the encoding execution time by almost 80% on average. Simulation results show that Rate-Distortion performance of the proposed method has higher compression gain than the other state-of-the-art lenslet compression methods with lower computational complexity.