 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Brain Tumor Segmentation Using Channel Attention and Transfer learning
Jan 19, 2025



Accurate and efficient segmentation of brain tumors is critical for diagnosis, treatment planning, and monitoring in clinical practice. In this study, we present an enhanced ResUNet architecture for automatic brain tumor segmentation, integrating an EfficientNetB0 encoder, a channel attention mechanism, and an Atrous Spatial Pyramid Pooling (ASPP) module. The EfficientNetB0 encoder leverages pre-trained features to improve feature extraction efficiency, while the channel attention mechanism enhances the model's focus on tumor-relevant features. ASPP enables multiscale contextual learning, crucial for handling tumors of varying sizes and shapes. The proposed model was evaluated on two benchmark datasets: TCGA LGG and BraTS 2020. Experimental results demonstrate that our method consistently outperforms the baseline ResUNet and its EfficientNet variant, achieving Dice coefficients of 0.903 and 0.851 and HD95 scores of 9.43 and 3.54 for whole tumor and tumor core regions on the BraTS 2020 dataset, respectively. compared with state-of-the-art methods, our approach shows competitive performance, particularly in whole tumor and tumor core segmentation. These results indicate that combining a powerful encoder with attention mechanisms and ASPP can significantly enhance brain tumor segmentation performance. The proposed approach holds promise for further optimization and application in other medical image segmentation tasks.
Breast Tumor Classification Using EfficientNet Deep Learning Model
Nov 26, 2024Precise breast cancer classification on histopathological images has the potential to greatly improve the diagnosis and patient outcome in oncology. The data imbalance problem largely stems from the inherent imbalance within medical image datasets, where certain tumor subtypes may appear much less frequently. This constitutes a considerable limitation in biased model predictions that can overlook critical but rare classes. In this work, we adopted EfficientNet, a state-of-the-art convolutional neural network (CNN) model that balances high accuracy with computational cost efficiency. To address data imbalance, we introduce an intensive data augmentation pipeline and cost-sensitive learning, improving representation and ensuring that the model does not overly favor majority classes. This approach provides the ability to learn effectively from rare tumor types, improving its robustness. Additionally, we fine-tuned the model using transfer learning, where weights in the beginning trained on a binary classification task were adopted to multi-class classification, improving the capability to detect complex patterns within the BreakHis dataset. Our results underscore significant improvements in the binary classification performance, achieving an exceptional recall increase for benign cases from 0.92 to 0.95, alongside an accuracy enhancement from 97.35 % to 98.23%. Our approach improved the performance of multi-class tasks from 91.27% with regular augmentation to 94.54% with intensive augmentation, reaching 95.04% with transfer learning. This framework demonstrated substantial gains in precision in the minority classes, such as Mucinous carcinoma and Papillary carcinoma, while maintaining high recall consistently across these critical subtypes, as further confirmed by confusion matrix analysis.
Improving precision of objective image/video quality metrics
Apr 26, 2021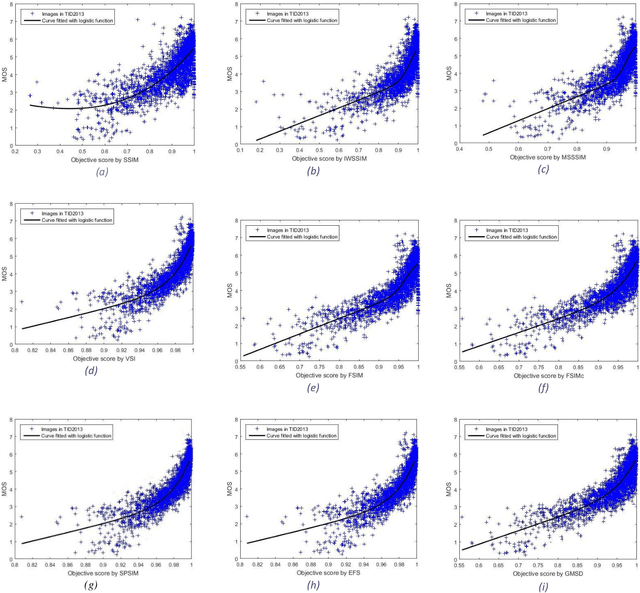
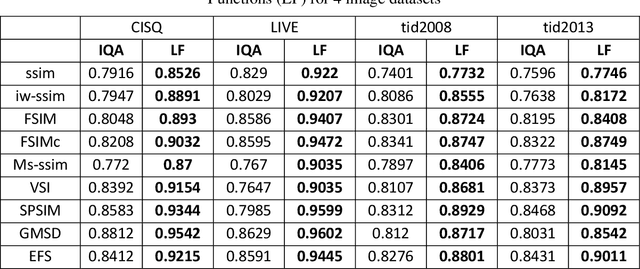
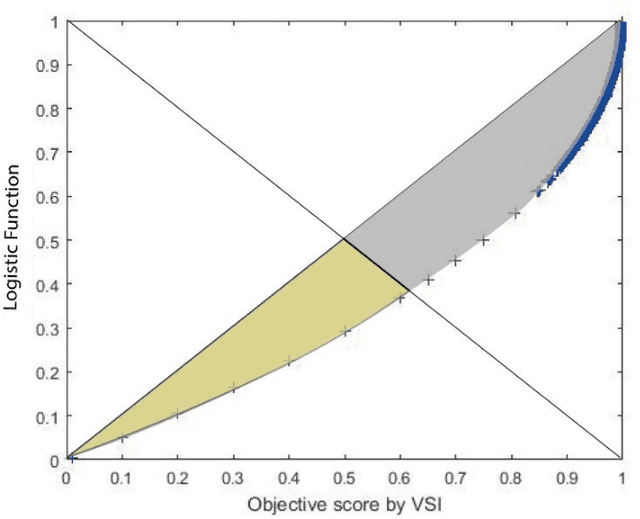
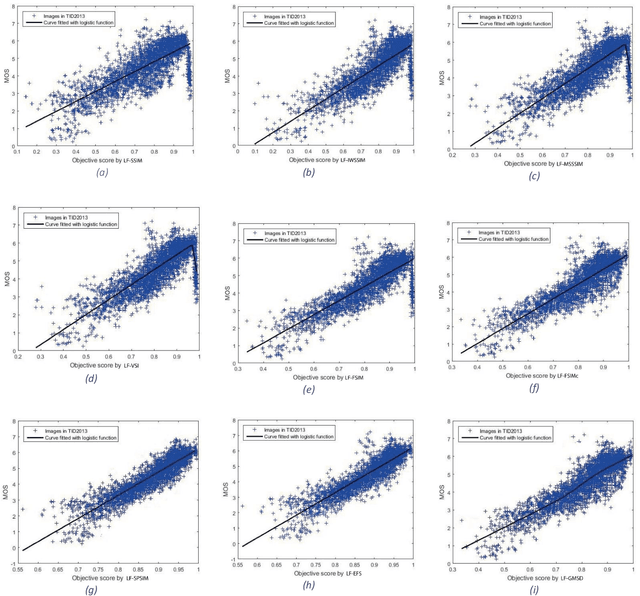
Although subjective tests are most accurate image/video quality assessment tools, they are extremely time demanding. In the past two decades, a variety of objective tools, such as SSIM, IW-SSIM, SPSIM, FSIM, etc., have been devised, that well correlate with the subjective tests results. However, the main problem with these methods is that, they do not discriminate the measured quality well enough, especially at high quality range. In this article we show how the accuracy/precision of these Image Quality Assessment (IQA) meters can be increased by mapping them into a Logistic Function (LF). The precisions are tested over a variety of image/video databases. Our experimental tests indicate while the used high-quality images can be discriminated by 23% resolution on the MOS subjective scores, discrimination resolution by the widely used IQAs are only 2%, but their mapped IQAs to Logistic Function at this quality range can be improved to 9.4%. Moreover, their precision at low to mid quality range can also be improved. At this quality range, while the discrimination resolution of MOS of the tested images is 23.2%, those of raw IQAs is nearly 8.9%, but their adapted logistic functions can lead to 17.7%, very close to that of MOS. Moreover, with the used image databases the Pearson correlation of MOS with the logistic function can be improved by 2%-20.2% as well.