 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn In-router Identification Scheme for Selective Discard of Video Packets
Apr 27, 2021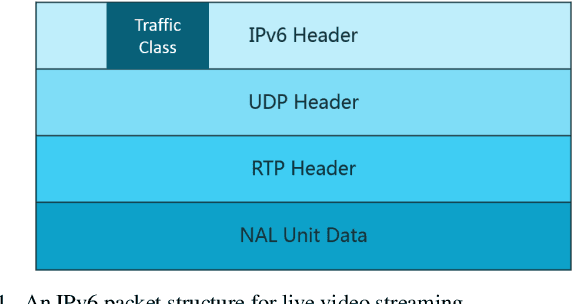

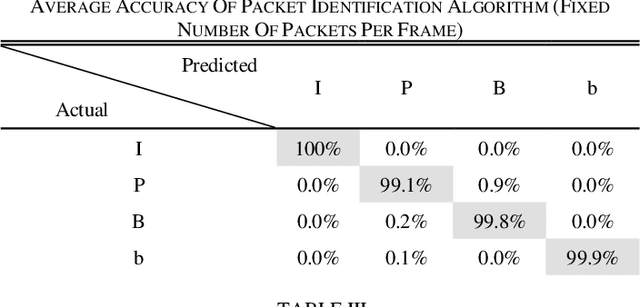
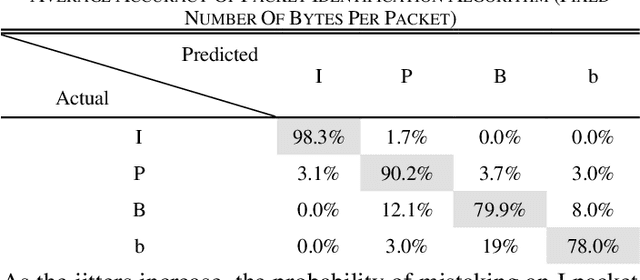
High quality (HQ) video services occupy large portions of the total bandwidth and are among the main causes of congestion at network bottlenecks. Since video is resilient to data loss, throwing away less important video packets can ease network congestion with minimal damage to video quality and free up bandwidth for other data flows. Frame type is one of the features that can be used to determine the importance of video packets, but this information is stored in the packet payload. Due to limited processing power of devices in high throughput/speed networks, data encryption and user credibility issues, it is costly for the network to find the frame type of each packet. Therefore, a fast and reliable standalone method to recognize video packet types at network level is desired. This paper proposes a method to model the structure of live video streams in a network node which results in determining the frame type of each packet. It enables the network nodes to mark and if need be to discard less important video packets ahead of congestion, and therefore preserve video quality and free up bandwidth for more important packet types. The method does not need to read the IP layer payload and uses only the packet header data for decisions. Experimental results indicate while dropping packets under packet type prediction degrades video quality with respect to its true type by 0.5-3 dB, it has 7-20 dB improvement over when packets are dropped randomly.