 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional neural networks for valid and efficient causal inference
Jan 27, 2023Convolutional neural networks (CNN) have been successful in machine learning applications. Their success relies on their ability to consider space invariant local features. We consider the use of CNN to fit nuisance models in semiparametric estimation of the average causal effect of a treatment. In this setting, nuisance models are functions of pre-treatment covariates that need to be controlled for. In an application where we want to estimate the effect of early retirement on a health outcome, we propose to use CNN to control for time-structured covariates. Thus, CNN is used when fitting nuisance models explaining the treatment and the outcome. These fits are then combined into an augmented inverse probability weighting estimator yielding efficient and uniformly valid inference. Theoretically, we contribute by providing rates of convergence for CNN equipped with the rectified linear unit activation function and compare it to an existing result for feedforward neural networks. We also show when those rates guarantee uniformly valid inference. A Monte Carlo study is provided where the performance of the proposed estimator is evaluated and compared with other strategies. Finally, we give results on a study of the effect of early retirement on hospitalization using data covering the whole Swedish population.
An In-router Identification Scheme for Selective Discard of Video Packets
Apr 27, 2021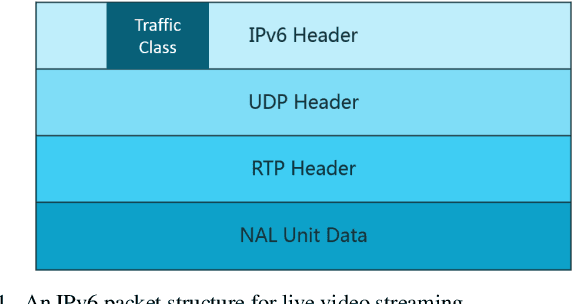

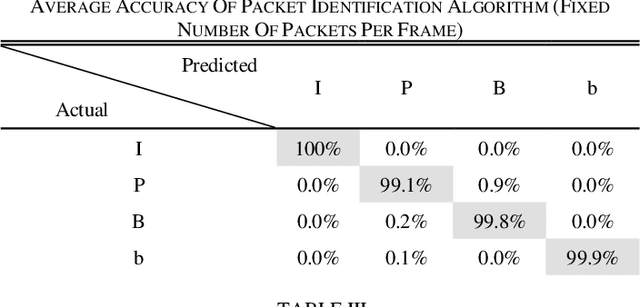
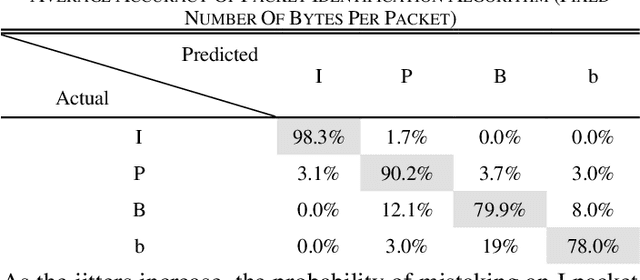
High quality (HQ) video services occupy large portions of the total bandwidth and are among the main causes of congestion at network bottlenecks. Since video is resilient to data loss, throwing away less important video packets can ease network congestion with minimal damage to video quality and free up bandwidth for other data flows. Frame type is one of the features that can be used to determine the importance of video packets, but this information is stored in the packet payload. Due to limited processing power of devices in high throughput/speed networks, data encryption and user credibility issues, it is costly for the network to find the frame type of each packet. Therefore, a fast and reliable standalone method to recognize video packet types at network level is desired. This paper proposes a method to model the structure of live video streams in a network node which results in determining the frame type of each packet. It enables the network nodes to mark and if need be to discard less important video packets ahead of congestion, and therefore preserve video quality and free up bandwidth for more important packet types. The method does not need to read the IP layer payload and uses only the packet header data for decisions. Experimental results indicate while dropping packets under packet type prediction degrades video quality with respect to its true type by 0.5-3 dB, it has 7-20 dB improvement over when packets are dropped randomly.