 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-DQA: Blindly Evaluating Dehazed Images from Global and Local Perspectives Using CLIP
Feb 03, 2025Blind dehazed image quality assessment (BDQA), which aims to accurately predict the visual quality of dehazed images without any reference information, is essential for the evaluation, comparison, and optimization of image dehazing algorithms. Existing learning-based BDQA methods have achieved remarkable success, while the small scale of DQA datasets limits their performance. To address this issue, in this paper, we propose to adapt Contrastive Language-Image Pre-Training (CLIP), pre-trained on large-scale image-text pairs, to the BDQA task. Specifically, inspired by the fact that the human visual system understands images based on hierarchical features, we take global and local information of the dehazed image as the input of CLIP. To accurately map the input hierarchical information of dehazed images into the quality score, we tune both the vision branch and language branch of CLIP with prompt learning. Experimental results on two authentic DQA datasets demonstrate that our proposed approach, named CLIP-DQA, achieves more accurate quality predictions over existing BDQA methods. The code is available at https://github.com/JunFu1995/CLIP-DQA.
Online Alternate Generator against Adversarial Attacks
Sep 17, 2020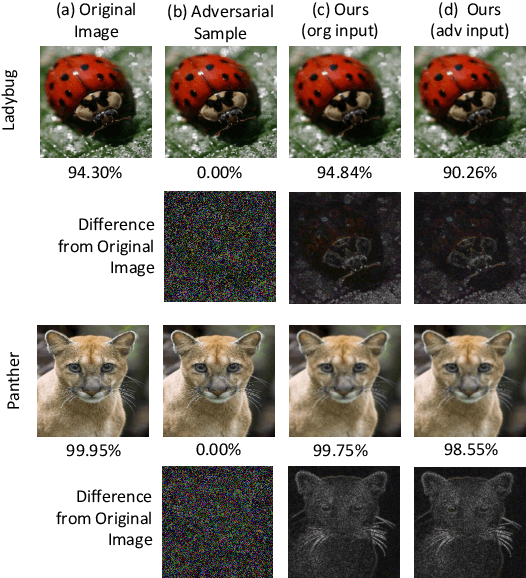

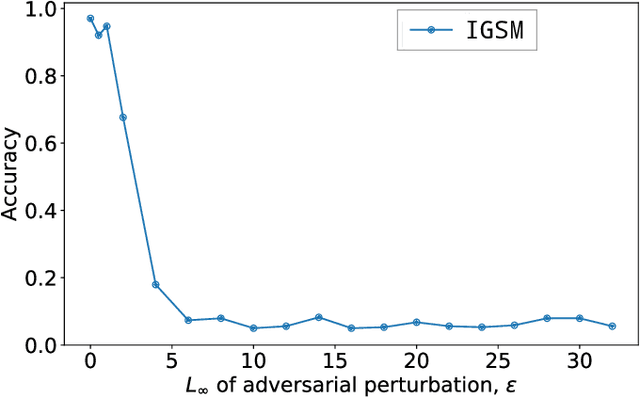
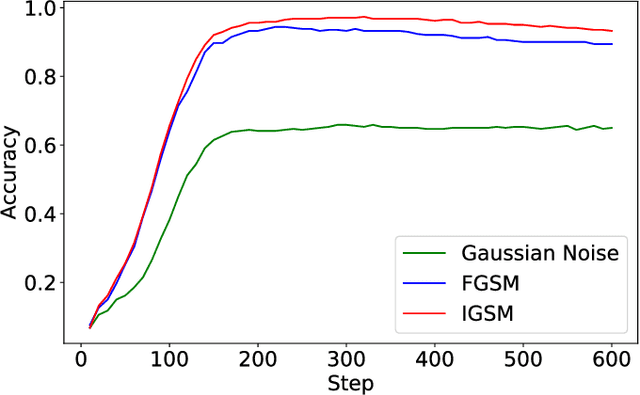
The field of computer vision has witnessed phenomenal progress in recent years partially due to the development of deep convolutional neural networks. However, deep learning models are notoriously sensitive to adversarial examples which are synthesized by adding quasi-perceptible noises on real images. Some existing defense methods require to re-train attacked target networks and augment the train set via known adversarial attacks, which is inefficient and might be unpromising with unknown attack types. To overcome the above issues, we propose a portable defense method, online alternate generator, which does not need to access or modify the parameters of the target networks. The proposed method works by online synthesizing another image from scratch for an input image, instead of removing or destroying adversarial noises. To avoid pretrained parameters exploited by attackers, we alternately update the generator and the synthesized image at the inference stage. Experimental results demonstrate that the proposed defensive scheme and method outperforms a series of state-of-the-art defending models against gray-box adversarial attacks.
Semantic Relationships Guided Representation Learning for Facial Action Unit Recognition
Apr 22, 2019
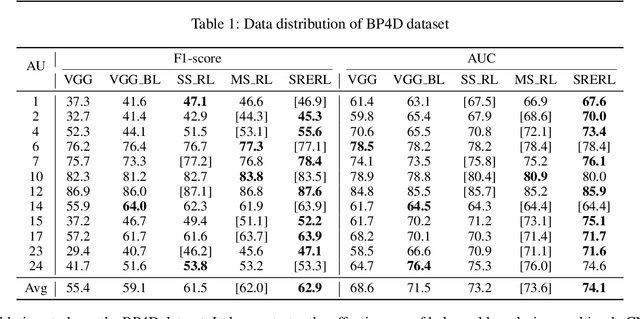


Facial action unit (AU) recognition is a crucial task for facial expressions analysis and has attracted extensive attention in the field of artificial intelligence and computer vision. Existing works have either focused on designing or learning complex regional feature representations, or delved into various types of AU relationship modeling. Albeit with varying degrees of progress, it is still arduous for existing methods to handle complex situations. In this paper, we investigate how to integrate the semantic relationship propagation between AUs in a deep neural network framework to enhance the feature representation of facial regions, and propose an AU semantic relationship embedded representation learning (SRERL) framework. Specifically, by analyzing the symbiosis and mutual exclusion of AUs in various facial expressions, we organize the facial AUs in the form of structured knowledge-graph and integrate a Gated Graph Neural Network (GGNN) in a multi-scale CNN framework to propagate node information through the graph for generating enhanced AU representation. As the learned feature involves both the appearance characteristics and the AU relationship reasoning, the proposed model is more robust and can cope with more challenging cases, e.g., illumination change and partial occlusion. Extensive experiments on the two public benchmarks demonstrate that our method outperforms the previous work and achieves state of the art performance.