 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemHiTok: A Unified Image Tokenizer via Semantic-Guided Hierarchical Codebook for Multimodal Understanding and Generation
Mar 09, 2025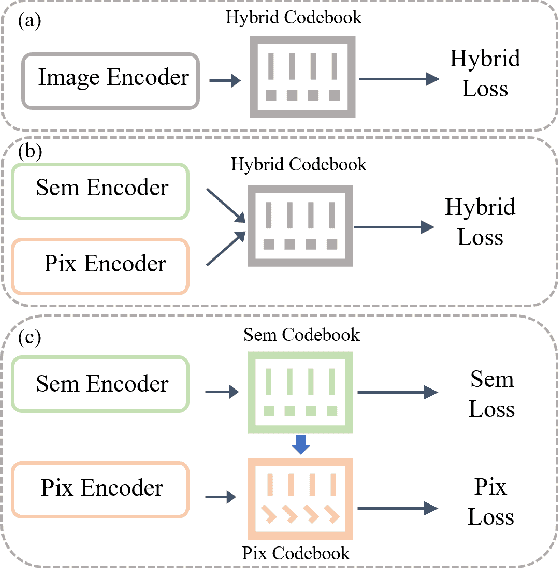
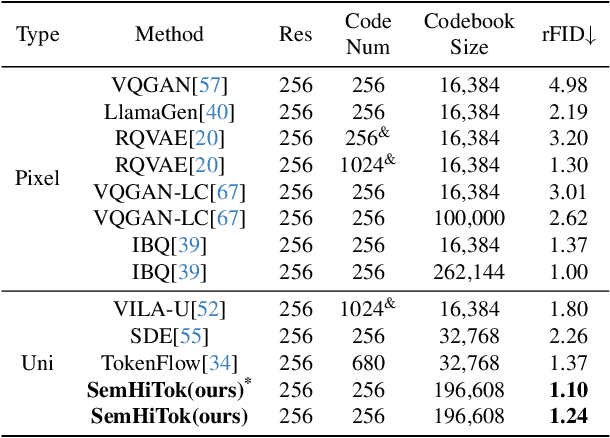
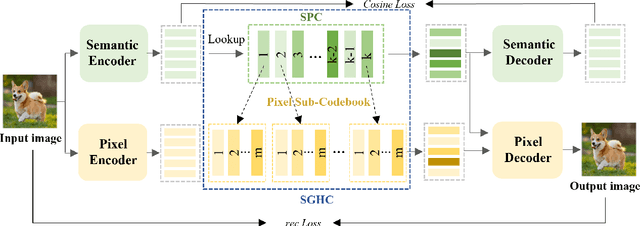
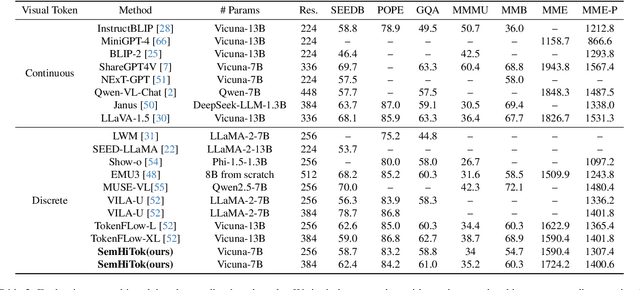
We present SemHiTok, a unified image Tokenizer via Semantic-Guided Hierarchical codebook that provides consistent discrete feature representations for multimodal understanding and generation tasks. Recently, unified multimodal large models (MLLMs) for understanding and generation have sparked exploration within research community. Previous works attempt to train a unified image tokenizer by combining loss functions for semantic feature reconstruction and pixel reconstruction. However, due to the differing levels of features prioritized by multimodal understanding and generation tasks, joint training methods face significant challenges in achieving a good trade-off. SemHiTok addresses this challenge through Semantic-Guided Hierarchical codebook which builds texture sub-codebooks on pre-trained semantic codebook. This design decouples the training of semantic reconstruction and pixel reconstruction and equips the tokenizer with low-level texture feature extraction capability without degradation of high-level semantic feature extraction ability. Our experiments demonstrate that SemHiTok achieves state-of-the-art rFID score at 256X256resolution compared to other unified tokenizers, and exhibits competitive performance on multimodal understanding and generation tasks.