 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative Control of Mobile Robots with Stackelberg Learning
Aug 03, 2020
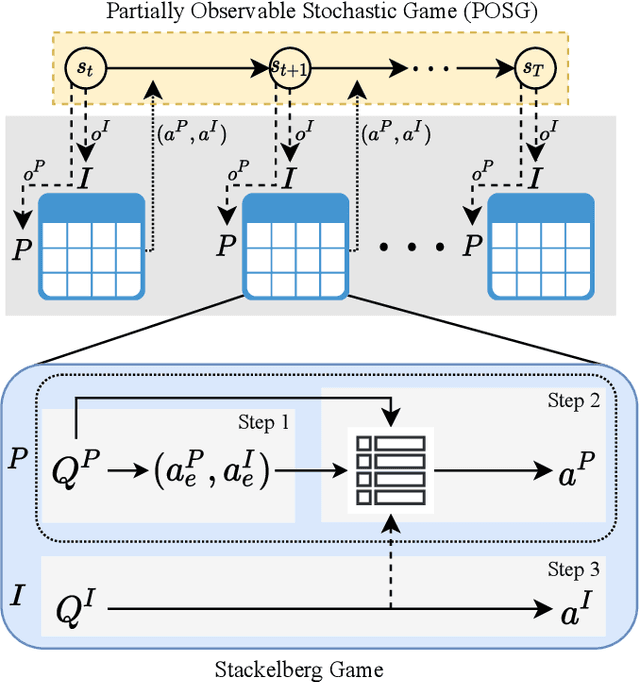

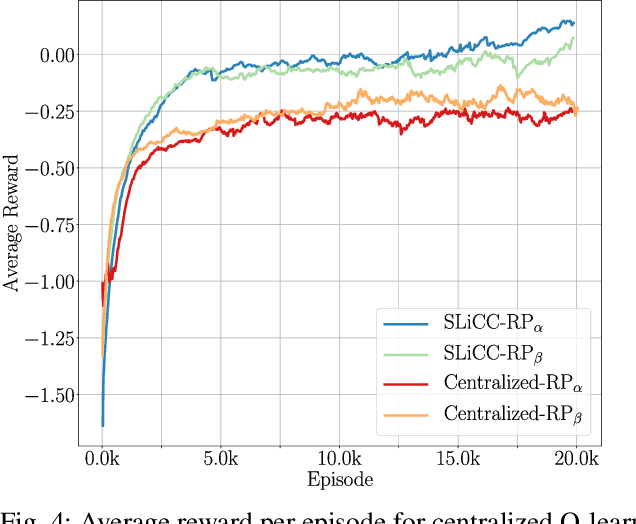
Multi-robot cooperation requires agents to make decisions that are consistent with the shared goal without disregarding action-specific preferences that might arise from asymmetry in capabilities and individual objectives. To accomplish this goal, we propose a method named SLiCC: Stackelberg Learning in Cooperative Control. SLiCC models the problem as a partially observable stochastic game composed of Stackelberg bimatrix games, and uses deep reinforcement learning to obtain the payoff matrices associated with these games. Appropriate cooperative actions are then selected with the derived Stackelberg equilibria. Using a bi-robot cooperative object transportation problem, we validate the performance of SLiCC against centralized multi-agent Q-learning and demonstrate that SLiCC achieves better combined utility.
* 8 pages, 7 figures
Distributed Reinforcement Learning for Cooperative Multi-Robot Object Manipulation
Mar 21, 2020
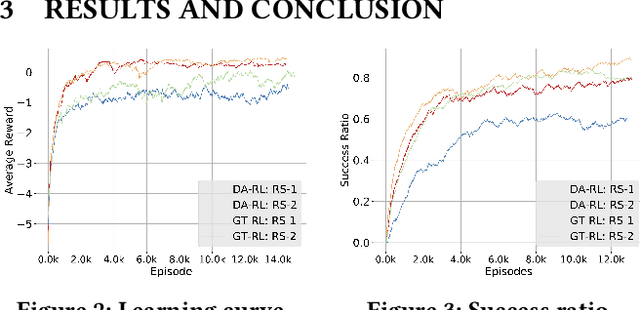
We consider solving a cooperative multi-robot object manipulation task using reinforcement learning (RL). We propose two distributed multi-agent RL approaches: distributed approximate RL (DA-RL), where each agent applies Q-learning with individual reward functions; and game-theoretic RL (GT-RL), where the agents update their Q-values based on the Nash equilibrium of a bimatrix Q-value game. We validate the proposed approaches in the setting of cooperative object manipulation with two simulated robot arms. Although we focus on a small system of two agents in this paper, both DA-RL and GT-RL apply to general multi-agent systems, and are expected to scale well to large systems.
* 3 pages, 3 figures
Inline Detection of Domain Generation Algorithms with Context-Sensitive Word Embeddings
Nov 21, 2018
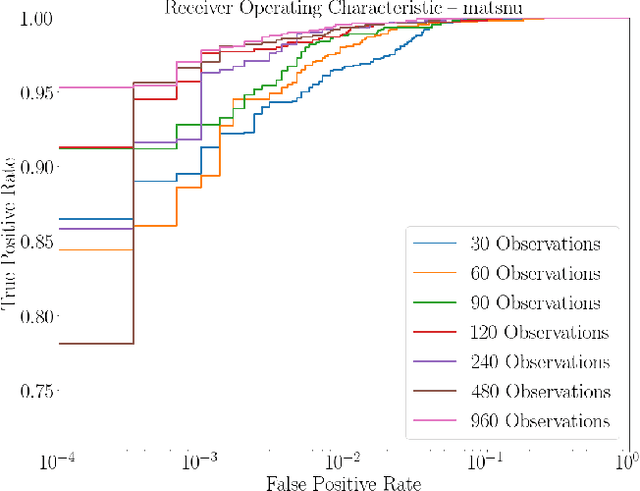
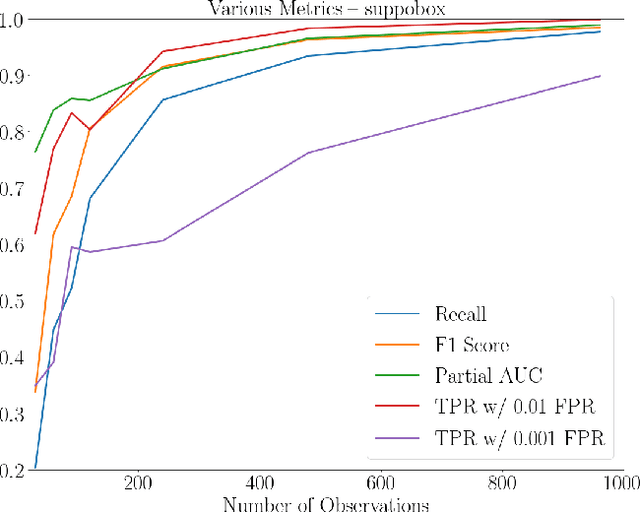

Domain generation algorithms (DGAs) are frequently employed by malware to generate domains used for connecting to command-and-control (C2) servers. Recent work in DGA detection leveraged deep learning architectures like convolutional neural networks (CNNs) and character-level long short-term memory networks (LSTMs) to classify domains. However, these classifiers perform poorly with wordlist-based DGA families, which generate domains by pseudorandomly concatenating dictionary words. We propose a novel approach that combines context-sensitive word embeddings with a simple fully-connected classifier to perform classification of domains based on word-level information. The word embeddings were pre-trained on a large unrelated corpus and left frozen during the training on domain data. The resulting small number of trainable parameters enabled extremely short training durations, while the transfer of language knowledge stored in the representations allowed for high-performing models with small training datasets. We show that this architecture reliably outperformed existing techniques on wordlist-based DGA families with just 30 DGA training examples and achieved state-of-the-art performance with around 100 DGA training examples, all while requiring an order of magnitude less time to train compared to current techniques. Of special note is the technique's performance on the matsnu DGA: the classifier attained a 89.5% detection rate with a 1:1,000 false positive rate (FPR) after training on only 30 examples of the DGA domains, and a 91.2% detection rate with a 1:10,000 FPR after 90 examples. Considering that some of these DGAs have wordlists of several hundred words, our results demonstrate that this technique does not rely on the classifier learning the DGA wordlists. Instead, the classifier is able to learn the semantic signatures of the wordlist-based DGA families.