 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Object Hallucinations in Vision-Language Models through Region-Aware Attention Recalibration
May 24, 2026The generation of factually incorrect objects, commonly known as object hallucination, remains a persistent challenge in Large Vision-Language Models (LVLMs). Current approaches to address this issue - ranging from expensive data-driven fine-tuning and high-latency contrastive decoding to rigid attention head truncation - frequently compromise either computational efficiency or the continuity of the model's feature space. To overcome these limitations, we introduce a novel, training-free inference strategy that operates as a region-aware adaptive weighting mechanism to dynamically correct semantic drift without relying on abrupt heuristic truncations. By computing an outlier-resistant statistical midpoint across various attention heads, we establish a stable anchor for reliable visual representations. We then utilize the inter-head disagreement mapped across regions to dynamically determine intervention budgets, gently suppressing hallucination-inducing attention paths through a continuous penalty modulation. This recalibration process effectively rectifies visual-semantic misalignments while fully preserving generative fluency and language priors. Comprehensive evaluations on standard multimodal benchmarks, including CHAIR, POPE, and MME, reveal that our strategy substantially curtails both instance- and sentence-level hallucinations. The results demonstrate state-of-the-art performance against contemporary baselines, confirming our method's efficiency and algorithmic robustness. Our code will be public.
Cooperative Control of Mobile Robots with Stackelberg Learning
Aug 03, 2020
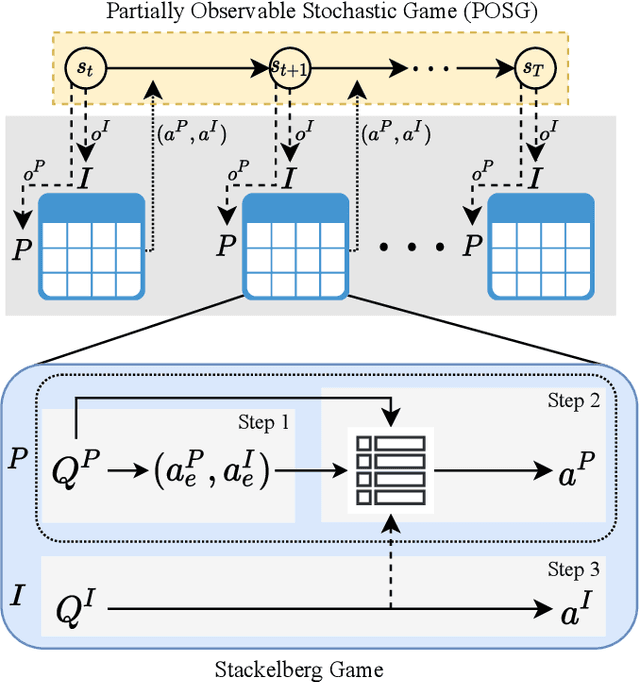

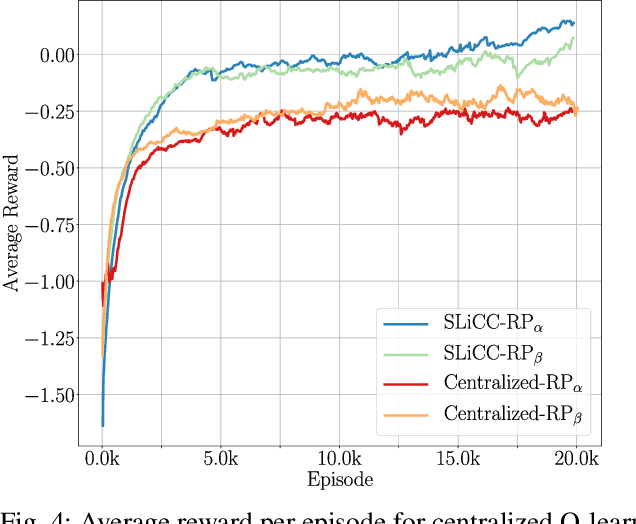
Multi-robot cooperation requires agents to make decisions that are consistent with the shared goal without disregarding action-specific preferences that might arise from asymmetry in capabilities and individual objectives. To accomplish this goal, we propose a method named SLiCC: Stackelberg Learning in Cooperative Control. SLiCC models the problem as a partially observable stochastic game composed of Stackelberg bimatrix games, and uses deep reinforcement learning to obtain the payoff matrices associated with these games. Appropriate cooperative actions are then selected with the derived Stackelberg equilibria. Using a bi-robot cooperative object transportation problem, we validate the performance of SLiCC against centralized multi-agent Q-learning and demonstrate that SLiCC achieves better combined utility.
* 8 pages, 7 figures
Distributed Reinforcement Learning for Cooperative Multi-Robot Object Manipulation
Mar 21, 2020
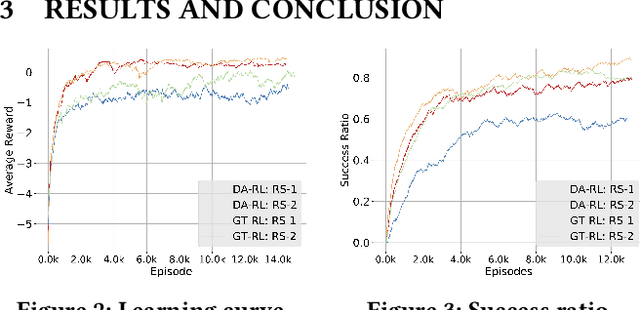
We consider solving a cooperative multi-robot object manipulation task using reinforcement learning (RL). We propose two distributed multi-agent RL approaches: distributed approximate RL (DA-RL), where each agent applies Q-learning with individual reward functions; and game-theoretic RL (GT-RL), where the agents update their Q-values based on the Nash equilibrium of a bimatrix Q-value game. We validate the proposed approaches in the setting of cooperative object manipulation with two simulated robot arms. Although we focus on a small system of two agents in this paper, both DA-RL and GT-RL apply to general multi-agent systems, and are expected to scale well to large systems.
* 3 pages, 3 figures
Towards Scalable Koopman Operator Learning: Convergence Rates and A Distributed Learning Algorithm
Sep 30, 2019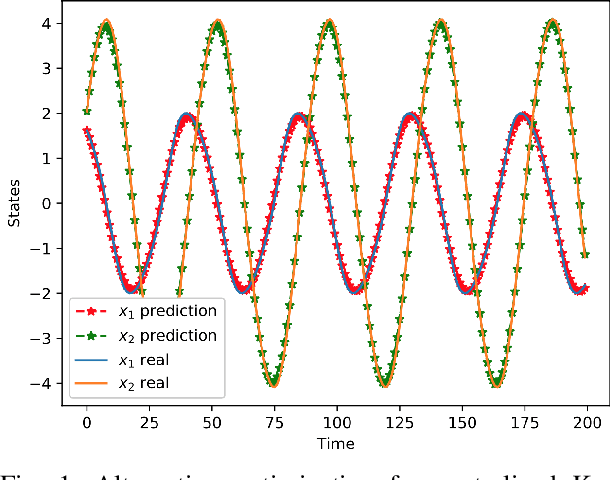
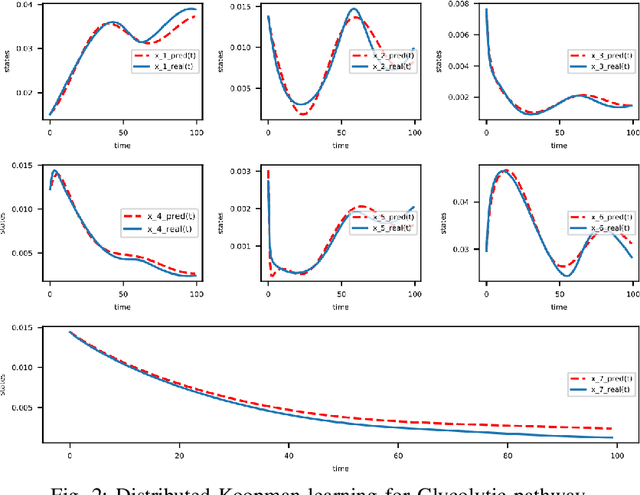
In this paper, we propose an alternating optimization algorithm to the nonconvex Koopman operator learning problem for nonlinear dynamic systems. We show that the proposed algorithm will converge to a critical point with rate $O(1/T)$ or $O(\frac{1}{\log T})$ under some mild assumptions. To handle the high dimensional nonlinear dynamical systems, we present the first-ever distributed Koopman operator learning algorithm. We show that the distributed Koopman operator learning has the same convergence properties as a centralized Koopman operator learning problem, in the absence of optimal tracker, so long as the basis functions satisfy a set of state-based decomposition conditions. Experiments are provided to complement our theoretical results.