 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOISE: Position-Aware Undetectable Skill Injection on LLM Agents
Jun 06, 2026Agent skills provide a lightweight mechanism for extending general-purpose agents, but their open format exposes them to skill-poisoning attacks. A practically dangerous injection must stay invisible: if executing the payload derails the user's legitimate task, the resulting failure signal invites inspection of the skill. We therefore evaluate attacks by Attack Success Rate, which requires the injected payload to execute and the user's task to still pass its verifier in the same trial. Prior skill-poisoning attacks face a reliability-stealth trade-off under this lens: YAML-header injections are reliably loaded but easily inspected, whereas stealthier body injections that place explicit malicious commands in the skill prose are less reliable because out-of-context commands invite the agent's own suspicion. We introduce POISE, a position-aware attack that compresses the trigger into a single, benign-looking body instruction, placing it at a feasible position and using a context-aware generator to blend it with nearby setup or prerequisite steps. On Skill-Inject with codex+gpt-5.2, POISE achieves an 89.3% ASR, 28.0 points above a random-placement body baseline and 2.6 points above a YAML-only baseline, while retaining the stealth advantage of body placement. That stealth is the decisive margin: because legitimate skill bodies naturally require privileged tool operations, LLM scanners are hyper-sensitive, falsely flagging 74.6% of clean skills on average across four judges and both benchmarks. Blending into these false alarms, POISE causes only 5.6% of poisoned variants to gain a new high-risk alert over their clean baselines, rendering current static defenses ineffective.
Towards Safer Large Reasoning Models by Promoting Safety Decision-Making before Chain-of-Thought Generation
Mar 18, 2026Large reasoning models (LRMs) achieved remarkable performance via chain-of-thought (CoT), but recent studies showed that such enhanced reasoning capabilities are at the expense of significantly degraded safety capabilities. In this paper, we reveal that LRMs' safety degradation occurs only after CoT is enabled, and this degradation is not observed when CoT is disabled. This observation motivates us to consider encouraging LRMs to make safety decisions before CoT generation. To this end, we propose a novel safety alignment method that promotes the safety decision-making of LRMs before starting CoT generation. Specifically, we first utilize a Bert-based classifier to extract safety decision signals from a safe model (e.g., a CoT-disabled LRM) and then integrate these signals into LRMs' safety alignment as auxiliary supervision. In this way, the safety gradients can be backpropagated to the LRMs' latent representations, effectively strengthening the LRMs' safety decision-making abilities against CoT generation. Extensive experiments demonstrate that our method substantially improves the safety capabilities of LRMs while effectively maintaining LRMs' general reasoning performance.
Test-Time Attention Purification for Backdoored Large Vision Language Models
Mar 13, 2026Despite the strong multimodal performance, large vision-language models (LVLMs) are vulnerable during fine-tuning to backdoor attacks, where adversaries insert trigger-embedded samples into the training data to implant behaviors that can be maliciously activated at test time. Existing defenses typically rely on retraining backdoored parameters (e.g., adapters or LoRA modules) with clean data, which is computationally expensive and often degrades model performance. In this work, we provide a new mechanistic understanding of backdoor behaviors in LVLMs: the trigger does not influence prediction through low-level visual patterns, but through abnormal cross-modal attention redistribution, where trigger-bearing visual tokens steal attention away from the textual context - a phenomenon we term attention stealing. Motivated by this, we propose CleanSight, a training-free, plug-and-play defense that operates purely at test time. CleanSight (i) detects poisoned inputs based on the relative visual-text attention ratio in selected cross-modal fusion layers, and (ii) purifies the input by selectively pruning the suspicious high-attention visual tokens to neutralize the backdoor activation. Extensive experiments show that CleanSight significantly outperforms existing pixel-based purification defenses across diverse datasets and backdoor attack types, while preserving the model's utility on both clean and poisoned samples.
LanP: Rethinking the Impact of Language Priors in Large Vision-Language Models
Feb 17, 2025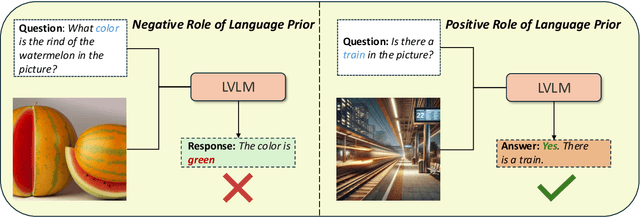
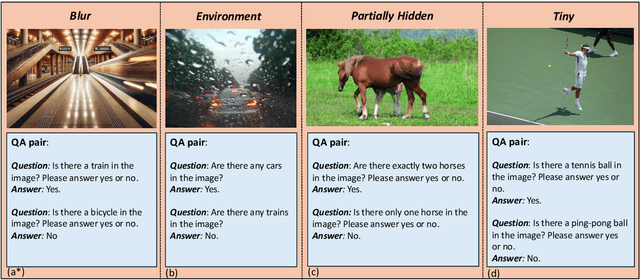
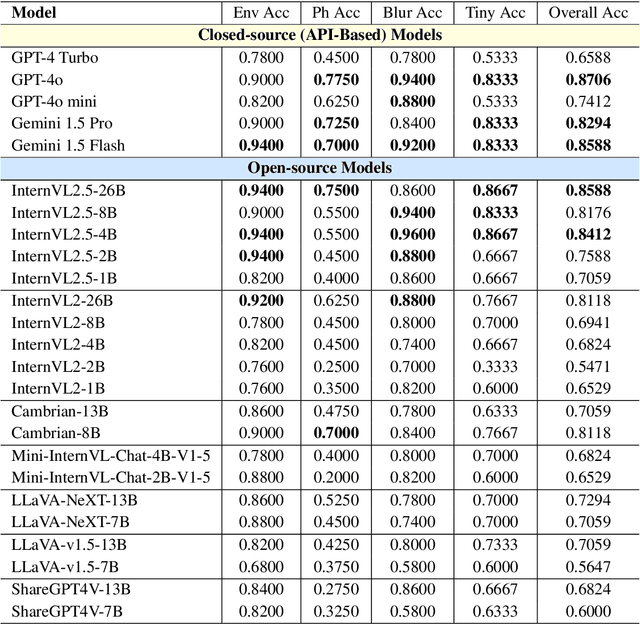
Large Vision-Language Models (LVLMs) have shown impressive performance in various tasks. However, LVLMs suffer from hallucination, which hinders their adoption in the real world. Existing studies emphasized that the strong language priors of LVLMs can overpower visual information, causing hallucinations. However, the positive role of language priors is the key to a powerful LVLM. If the language priors are too weak, LVLMs will struggle to leverage rich parameter knowledge and instruction understanding abilities to complete tasks in challenging visual scenarios where visual information alone is insufficient. Therefore, we propose a benchmark called LanP to rethink the impact of Language Priors in LVLMs. It is designed to investigate how strong language priors are in current LVLMs. LanP consists of 170 images and 340 corresponding well-designed questions. Extensive experiments on 25 popular LVLMs reveal that many LVLMs' language priors are not strong enough to effectively aid question answering when objects are partially hidden. Many models, including GPT-4 Turbo, exhibit an accuracy below 0.5 in such a scenario.
Defending Multimodal Backdoored Models by Repulsive Visual Prompt Tuning
Dec 29, 2024



Multimodal contrastive learning models (e.g., CLIP) can learn high-quality representations from large-scale image-text datasets, yet they exhibit significant vulnerabilities to backdoor attacks, raising serious safety concerns. In this paper, we disclose that CLIP's vulnerabilities primarily stem from its excessive encoding of class-irrelevant features, which can compromise the model's visual feature resistivity to input perturbations, making it more susceptible to capturing the trigger patterns inserted by backdoor attacks. Inspired by this finding, we propose Repulsive Visual Prompt Tuning (RVPT), a novel defense approach that employs specially designed deep visual prompt tuning and feature-repelling loss to eliminate excessive class-irrelevant features while simultaneously optimizing cross-entropy loss to maintain clean accuracy. Unlike existing multimodal backdoor defense methods that typically require the availability of poisoned data or involve fine-tuning the entire model, RVPT leverages few-shot downstream clean samples and only tunes a small number of parameters. Empirical results demonstrate that RVPT tunes only 0.27\% of the parameters relative to CLIP, yet it significantly outperforms state-of-the-art baselines, reducing the attack success rate from 67.53\% to 2.76\% against SoTA attacks and effectively generalizing its defensive capabilities across multiple datasets.
Tuning Vision-Language Models with Candidate Labels by Prompt Alignment
Jul 11, 2024



Vision-language models (VLMs) can learn high-quality representations from a large-scale training dataset of image-text pairs. Prompt learning is a popular approach to fine-tuning VLM to adapt them to downstream tasks. Despite the satisfying performance, a major limitation of prompt learning is the demand for labelled data. In real-world scenarios, we may only obtain candidate labels (where the true label is included) instead of the true labels due to data privacy or sensitivity issues. In this paper, we provide the first study on prompt learning with candidate labels for VLMs. We empirically demonstrate that prompt learning is more advantageous than other fine-tuning methods, for handling candidate labels. Nonetheless, its performance drops when the label ambiguity increases. In order to improve its robustness, we propose a simple yet effective framework that better leverages the prior knowledge of VLMs to guide the learning process with candidate labels. Specifically, our framework disambiguates candidate labels by aligning the model output with the mixed class posterior jointly predicted by both the learnable and the handcrafted prompt. Besides, our framework can be equipped with various off-the-shelf training objectives for learning with candidate labels to further improve their performance. Extensive experiments demonstrate the effectiveness of our proposed framework.
Atrial Septal Defect Detection in Children Based on Ultrasound Video Using Multiple Instances Learning
Jun 06, 2023

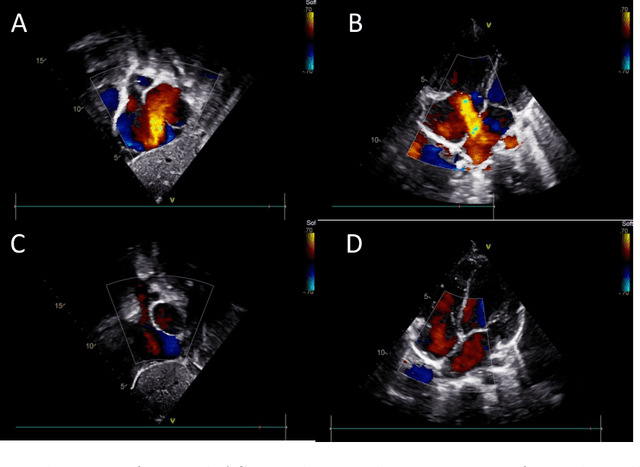
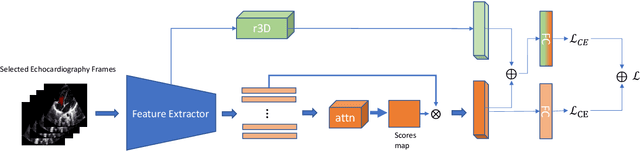
Purpose: Congenital heart defect (CHD) is the most common birth defect. Thoracic echocardiography (TTE) can provide sufficient cardiac structure information, evaluate hemodynamics and cardiac function, and is an effective method for atrial septal defect (ASD) examination. This paper aims to study a deep learning method based on cardiac ultrasound video to assist in ASD diagnosis. Materials and methods: We select two standard views of the atrial septum (subAS) and low parasternal four-compartment view (LPS4C) as the two views to identify ASD. We enlist data from 300 children patients as part of a double-blind experiment for five-fold cross-validation to verify the performance of our model. In addition, data from 30 children patients (15 positives and 15 negatives) are collected for clinician testing and compared to our model test results (these 30 samples do not participate in model training). We propose an echocardiography video-based atrial septal defect diagnosis system. In our model, we present a block random selection, maximal agreement decision and frame sampling strategy for training and testing respectively, resNet18 and r3D networks are used to extract the frame features and aggregate them to build a rich video-level representation. Results: We validate our model using our private dataset by five-cross validation. For ASD detection, we achieve 89.33 AUC, 84.95 accuracy, 85.70 sensitivity, 81.51 specificity and 81.99 F1 score. Conclusion: The proposed model is multiple instances learning-based deep learning model for video atrial septal defect detection which effectively improves ASD detection accuracy when compared to the performances of previous networks and clinical doctors.