 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Agentic Evolution is the Path to Evolving LLMs
Jan 30, 2026As Large Language Models (LLMs) move from curated training sets into open-ended real-world environments, a fundamental limitation emerges: static training cannot keep pace with continual deployment environment change. Scaling training-time and inference-time compute improves static capability but does not close this train-deploy gap. We argue that addressing this limitation requires a new scaling axis-evolution. Existing deployment-time adaptation methods, whether parametric fine-tuning or heuristic memory accumulation, lack the strategic agency needed to diagnose failures and produce durable improvements. Our position is that agentic evolution represents the inevitable future of LLM adaptation, elevating evolution itself from a fixed pipeline to an autonomous evolver agent. We instantiate this vision in a general framework, A-Evolve, which treats deployment-time improvement as a deliberate, goal-directed optimization process over persistent system state. We further propose the evolution-scaling hypothesis: the capacity for adaptation scales with the compute allocated to evolution, positioning agentic evolution as a scalable path toward sustained, open-ended adaptation in the real world.
Kolmogorov-Arnold Representation for Symplectic Learning: Advancing Hamiltonian Neural Networks
Aug 26, 2025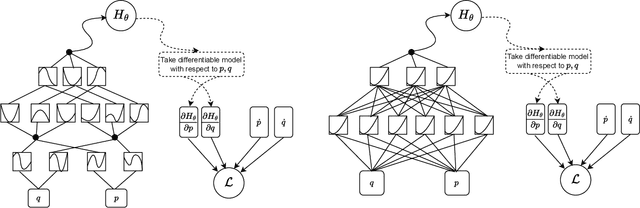
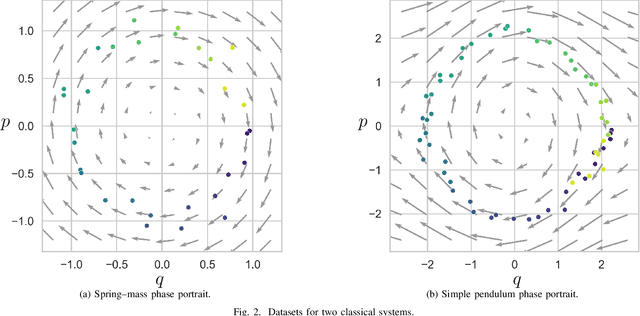
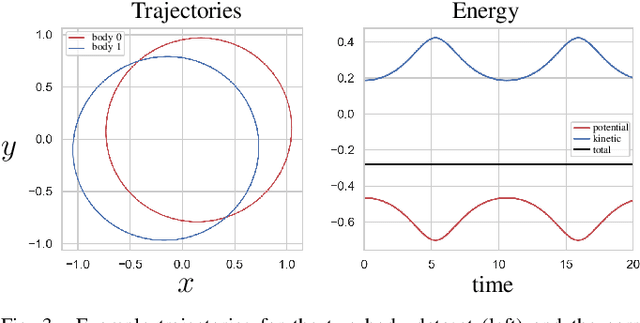
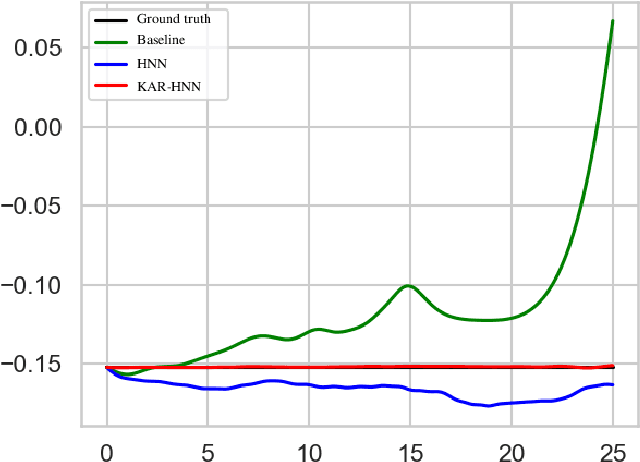
We propose a Kolmogorov-Arnold Representation-based Hamiltonian Neural Network (KAR-HNN) that replaces the Multilayer Perceptrons (MLPs) with univariate transformations. While Hamiltonian Neural Networks (HNNs) ensure energy conservation by learning Hamiltonian functions directly from data, existing implementations, often relying on MLPs, cause hypersensitivity to the hyperparameters while exploring complex energy landscapes. Our approach exploits the localized function approximations to better capture high-frequency and multi-scale dynamics, reducing energy drift and improving long-term predictive stability. The networks preserve the symplectic form of Hamiltonian systems, and thus maintain interpretability and physical consistency. After assessing KAR-HNN on four benchmark problems including spring-mass, simple pendulum, two- and three-body problem, we foresee its effectiveness for accurate and stable modeling of realistic physical processes often at high dimensions and with few known parameters.
Image Corruption-Inspired Membership Inference Attacks against Large Vision-Language Models
Jun 14, 2025Large vision-language models (LVLMs) have demonstrated outstanding performance in many downstream tasks. However, LVLMs are trained on large-scale datasets, which can pose privacy risks if training images contain sensitive information. Therefore, it is important to detect whether an image is used to train the LVLM. Recent studies have investigated membership inference attacks (MIAs) against LVLMs, including detecting image-text pairs and single-modality content. In this work, we focus on detecting whether a target image is used to train the target LVLM. We design simple yet effective Image Corruption-Inspired Membership Inference Attacks (ICIMIA) against LLVLMs, which are inspired by LVLM's different sensitivity to image corruption for member and non-member images. We first perform an MIA method under the white-box setting, where we can obtain the embeddings of the image through the vision part of the target LVLM. The attacks are based on the embedding similarity between the image and its corrupted version. We further explore a more practical scenario where we have no knowledge about target LVLMs and we can only query the target LVLMs with an image and a question. We then conduct the attack by utilizing the output text embeddings' similarity. Experiments on existing datasets validate the effectiveness of our proposed attack methods under those two different settings.
Bridging Source and Target Domains via Link Prediction for Unsupervised Domain Adaptation on Graphs
May 29, 2025Graph neural networks (GNNs) have shown great ability for node classification on graphs. However, the success of GNNs relies on abundant labeled data, while obtaining high-quality labels is costly and challenging, especially for newly emerging domains. Hence, unsupervised domain adaptation (UDA), which trains a classifier on the labeled source graph and adapts it to the unlabeled target graph, is attracting increasing attention. Various approaches have been proposed to alleviate the distribution shift between the source and target graphs to facilitate the classifier adaptation. However, most of them simply adopt existing UDA techniques developed for independent and identically distributed data to gain domain-invariant node embeddings for graphs, which do not fully consider the graph structure and message-passing mechanism of GNNs during the adaptation and will fail when label distribution shift exists among domains. In this paper, we proposed a novel framework that adopts link prediction to connect nodes between source and target graphs, which can facilitate message-passing between the source and target graphs and augment the target nodes to have ``in-distribution'' neighborhoods with the source domain. This strategy modified the target graph on the input level to reduce its deviation from the source domain in the embedding space and is insensitive to disproportional label distributions across domains. To prevent the loss of discriminative information in the target graph, we further design a novel identity-preserving learning objective, which guides the learning of the edge insertion module together with reconstruction and adaptation losses. Experimental results on real-world datasets demonstrate the effectiveness of our framework.
LanP: Rethinking the Impact of Language Priors in Large Vision-Language Models
Feb 17, 2025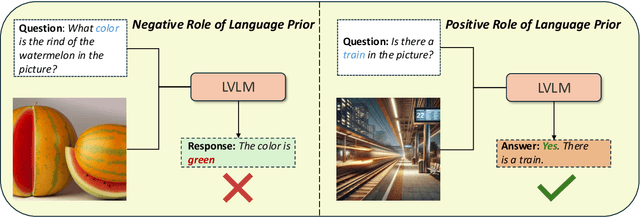
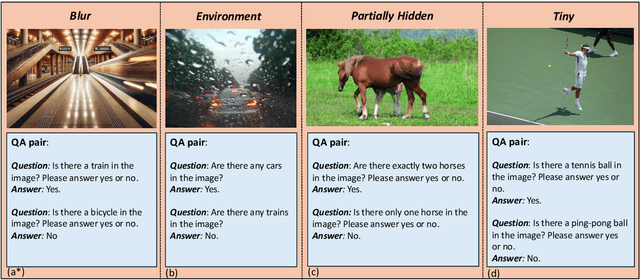
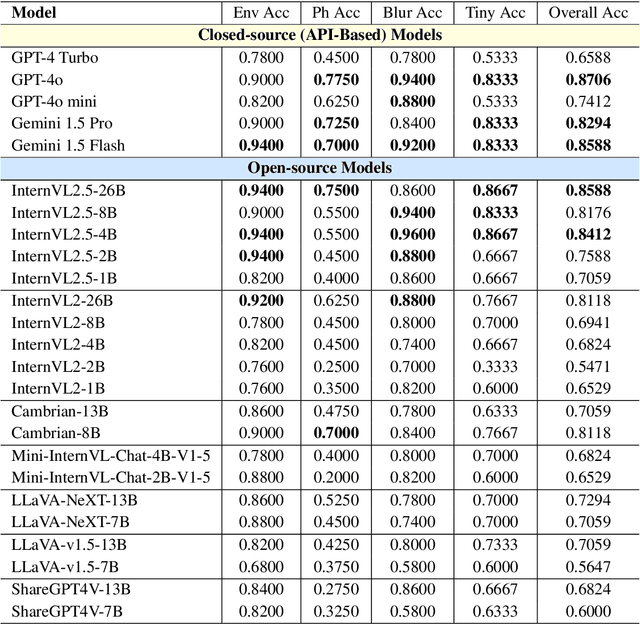
Large Vision-Language Models (LVLMs) have shown impressive performance in various tasks. However, LVLMs suffer from hallucination, which hinders their adoption in the real world. Existing studies emphasized that the strong language priors of LVLMs can overpower visual information, causing hallucinations. However, the positive role of language priors is the key to a powerful LVLM. If the language priors are too weak, LVLMs will struggle to leverage rich parameter knowledge and instruction understanding abilities to complete tasks in challenging visual scenarios where visual information alone is insufficient. Therefore, we propose a benchmark called LanP to rethink the impact of Language Priors in LVLMs. It is designed to investigate how strong language priors are in current LVLMs. LanP consists of 170 images and 340 corresponding well-designed questions. Extensive experiments on 25 popular LVLMs reveal that many LVLMs' language priors are not strong enough to effectively aid question answering when objects are partially hidden. Many models, including GPT-4 Turbo, exhibit an accuracy below 0.5 in such a scenario.
A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness
Nov 04, 2024Large language models (LLM) have demonstrated emergent abilities in text generation, question answering, and reasoning, facilitating various tasks and domains. Despite their proficiency in various tasks, LLMs like LaPM 540B and Llama-3.1 405B face limitations due to large parameter sizes and computational demands, often requiring cloud API use which raises privacy concerns, limits real-time applications on edge devices, and increases fine-tuning costs. Additionally, LLMs often underperform in specialized domains such as healthcare and law due to insufficient domain-specific knowledge, necessitating specialized models. Therefore, Small Language Models (SLMs) are increasingly favored for their low inference latency, cost-effectiveness, efficient development, and easy customization and adaptability. These models are particularly well-suited for resource-limited environments and domain knowledge acquisition, addressing LLMs' challenges and proving ideal for applications that require localized data handling for privacy, minimal inference latency for efficiency, and domain knowledge acquisition through lightweight fine-tuning. The rising demand for SLMs has spurred extensive research and development. However, a comprehensive survey investigating issues related to the definition, acquisition, application, enhancement, and reliability of SLM remains lacking, prompting us to conduct a detailed survey on these topics. The definition of SLMs varies widely, thus to standardize, we propose defining SLMs by their capability to perform specialized tasks and suitability for resource-constrained settings, setting boundaries based on the minimal size for emergent abilities and the maximum size sustainable under resource constraints. For other aspects, we provide a taxonomy of relevant models/methods and develop general frameworks for each category to enhance and utilize SLMs effectively.
Decoding Time Series with LLMs: A Multi-Agent Framework for Cross-Domain Annotation
Oct 22, 2024



Time series data is ubiquitous across various domains, including manufacturing, finance, and healthcare. High-quality annotations are essential for effectively understanding time series and facilitating downstream tasks; however, obtaining such annotations is challenging, particularly in mission-critical domains. In this paper, we propose TESSA, a multi-agent system designed to automatically generate both general and domain-specific annotations for time series data. TESSA introduces two agents: a general annotation agent and a domain-specific annotation agent. The general agent captures common patterns and knowledge across multiple source domains, leveraging both time-series-wise and text-wise features to generate general annotations. Meanwhile, the domain-specific agent utilizes limited annotations from the target domain to learn domain-specific terminology and generate targeted annotations. Extensive experiments on multiple synthetic and real-world datasets demonstrate that TESSA effectively generates high-quality annotations, outperforming existing methods.
Does your LLM truly unlearn? An embarrassingly simple approach to recover unlearned knowledge
Oct 21, 2024



Large language models (LLMs) have shown remarkable proficiency in generating text, benefiting from extensive training on vast textual corpora. However, LLMs may also acquire unwanted behaviors from the diverse and sensitive nature of their training data, which can include copyrighted and private content. Machine unlearning has been introduced as a viable solution to remove the influence of such problematic content without the need for costly and time-consuming retraining. This process aims to erase specific knowledge from LLMs while preserving as much model utility as possible. Despite the effectiveness of current unlearning methods, little attention has been given to whether existing unlearning methods for LLMs truly achieve forgetting or merely hide the knowledge, which current unlearning benchmarks fail to detect. This paper reveals that applying quantization to models that have undergone unlearning can restore the "forgotten" information. To thoroughly evaluate this phenomenon, we conduct comprehensive experiments using various quantization techniques across multiple precision levels. We find that for unlearning methods with utility constraints, the unlearned model retains an average of 21\% of the intended forgotten knowledge in full precision, which significantly increases to 83\% after 4-bit quantization. Based on our empirical findings, we provide a theoretical explanation for the observed phenomenon and propose a quantization-robust unlearning strategy to mitigate this intricate issue...
Trojan Prompt Attacks on Graph Neural Networks
Oct 17, 2024



Graph Prompt Learning (GPL) has been introduced as a promising approach that uses prompts to adapt pre-trained GNN models to specific downstream tasks without requiring fine-tuning of the entire model. Despite the advantages of GPL, little attention has been given to its vulnerability to backdoor attacks, where an adversary can manipulate the model's behavior by embedding hidden triggers. Existing graph backdoor attacks rely on modifying model parameters during training, but this approach is impractical in GPL as GNN encoder parameters are frozen after pre-training. Moreover, downstream users may fine-tune their own task models on clean datasets, further complicating the attack. In this paper, we propose TGPA, a backdoor attack framework designed specifically for GPL. TGPA injects backdoors into graph prompts without modifying pre-trained GNN encoders and ensures high attack success rates and clean accuracy. To address the challenge of model fine-tuning by users, we introduce a finetuning-resistant poisoning approach that maintains the effectiveness of the backdoor even after downstream model adjustments. Extensive experiments on multiple datasets under various settings demonstrate the effectiveness of TGPA in compromising GPL models with fixed GNN encoders.
Divide-Verify-Refine: Aligning LLM Responses with Complex Instructions
Oct 16, 2024Recent studies show that LLMs, particularly open-source models, struggle to follow complex instructions with multiple constraints. Despite the importance, methods to improve LLMs' adherence to such constraints remain unexplored, and current research focuses on evaluating this ability rather than developing solutions. While a few studies enhance constraint adherence through model tuning, this approach is computationally expensive and heavily reliant on training data quality. An alternative is to leverage LLMs' self-correction capabilities, allowing them to adjust responses to better meet specified constraints. However, this self-correction ability of LLMs is limited by the feedback quality, as LLMs cannot autonomously generate reliable feedback or detect errors. Moreover, the self-refinement process heavily depends on few-shot examples that illustrate how to modify responses to meet constraints. As constraints in complex instructions are diverse and vary widely, manually crafting few-shot examples for each constraint type can be labor-intensive and sub-optimal. To deal with these two challenges, we propose the Divide-Verify-Refine (DVR) framework with three steps: (1) Divide complex instructions into single constraints and prepare appropriate tools; (2) Verify: To address the feedback quality problem, these tools will rigorously verify responses and provide reliable feedback; (3) Refine: To address the constraint diversity challenge, we design a refinement repository that collects successful refinement processes and uses them as few-shot demonstrations for future cases, allowing LLMs to learn from the past experience during inference. Additionally, we develop a new dataset of complex instructions, each containing 1-6 constraints. Experiments show that the framework significantly improves performance, doubling LLama3.1-8B's constraint adherence on instructions with 6 constraints.