 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKolmogorov-Arnold Representation for Symplectic Learning: Advancing Hamiltonian Neural Networks
Aug 26, 2025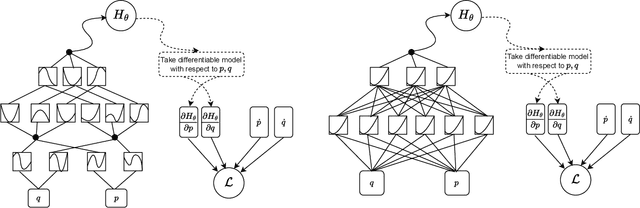
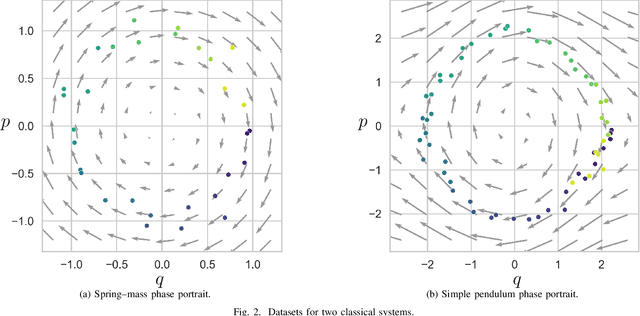
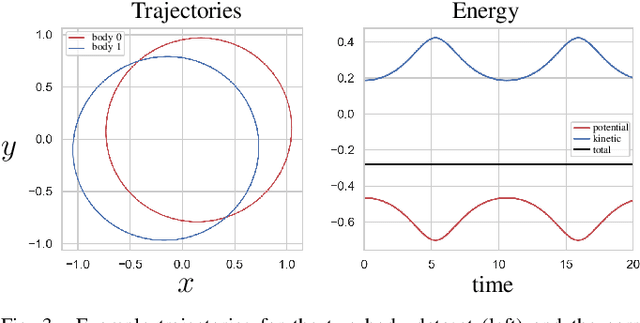
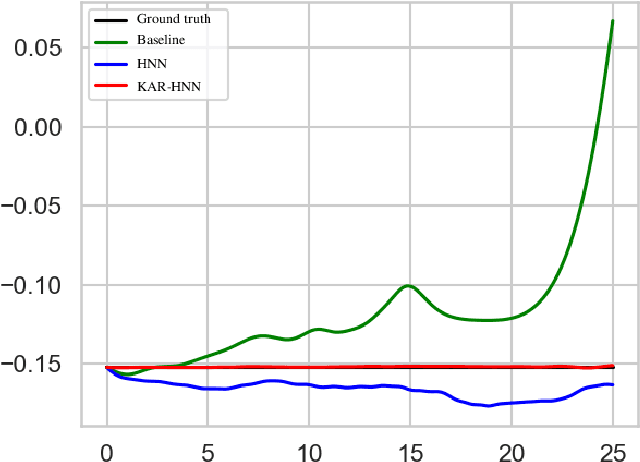
We propose a Kolmogorov-Arnold Representation-based Hamiltonian Neural Network (KAR-HNN) that replaces the Multilayer Perceptrons (MLPs) with univariate transformations. While Hamiltonian Neural Networks (HNNs) ensure energy conservation by learning Hamiltonian functions directly from data, existing implementations, often relying on MLPs, cause hypersensitivity to the hyperparameters while exploring complex energy landscapes. Our approach exploits the localized function approximations to better capture high-frequency and multi-scale dynamics, reducing energy drift and improving long-term predictive stability. The networks preserve the symplectic form of Hamiltonian systems, and thus maintain interpretability and physical consistency. After assessing KAR-HNN on four benchmark problems including spring-mass, simple pendulum, two- and three-body problem, we foresee its effectiveness for accurate and stable modeling of realistic physical processes often at high dimensions and with few known parameters.
Empirical Error Estimates for Graph Sparsification
Mar 11, 2025Graph sparsification is a well-established technique for accelerating graph-based learning algorithms, which uses edge sampling to approximate dense graphs with sparse ones. Because the sparsification error is random and unknown, users must contend with uncertainty about the reliability of downstream computations. Although it is possible for users to obtain conceptual guidance from theoretical error bounds in the literature, such results are typically impractical at a numerical level. Taking an alternative approach, we propose to address these issues from a data-driven perspective by computing empirical error estimates. The proposed error estimates are highly versatile, and we demonstrate this in four use cases: Laplacian matrix approximation, graph cut queries, graph-structured regression, and spectral clustering. Moreover, we provide two theoretical guarantees for the error estimates, and explain why the cost of computing them is manageable in comparison to the overall cost of a typical graph sparsification workflow.
Mining Discriminative Food Regions for Accurate Food Recognition
Jul 08, 2022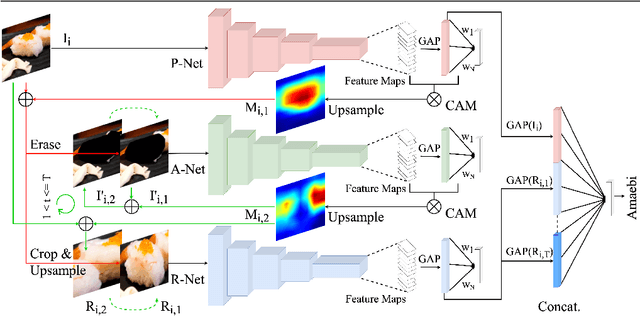
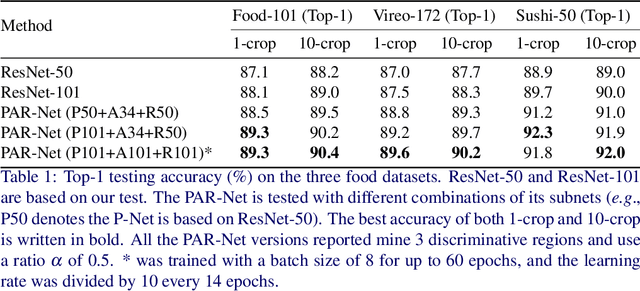

Automatic food recognition is the very first step towards passive dietary monitoring. In this paper, we address the problem of food recognition by mining discriminative food regions. Taking inspiration from Adversarial Erasing, a strategy that progressively discovers discriminative object regions for weakly supervised semantic segmentation, we propose a novel network architecture in which a primary network maintains the base accuracy of classifying an input image, an auxiliary network adversarially mines discriminative food regions, and a region network classifies the resulting mined regions. The global (the original input image) and the local (the mined regions) representations are then integrated for the final prediction. The proposed architecture denoted as PAR-Net is end-to-end trainable, and highlights discriminative regions in an online fashion. In addition, we introduce a new fine-grained food dataset named as Sushi-50, which consists of 50 different sushi categories. Extensive experiments have been conducted to evaluate the proposed approach. On three food datasets chosen (Food-101, Vireo-172, and Sushi-50), our approach performs consistently and achieves state-of-the-art results (top-1 testing accuracy of $90.4\%$, $90.2\%$, $92.0\%$, respectively) compared with other existing approaches. Dataset and code are available at https://github.com/Jianing-Qiu/PARNet
Privacy Preservation in Federated Learning: Insights from the GDPR Perspective
Nov 13, 2020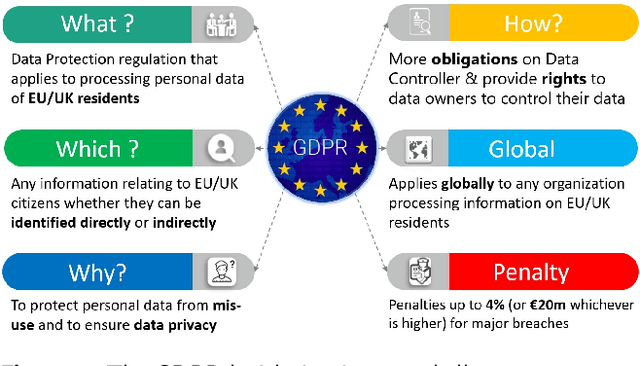

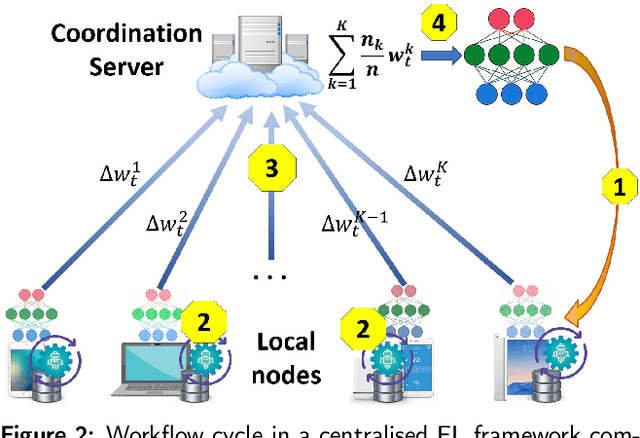
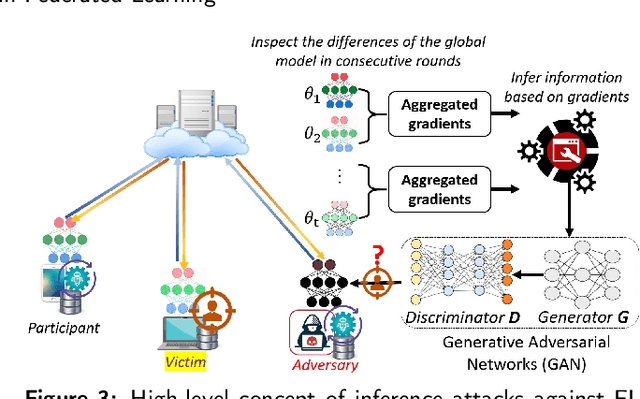
Along with the blooming of AI and Machine Learning-based applications and services, data privacy and security have become a critical challenge. Conventionally, data is collected and aggregated in a data centre on which machine learning models are trained. This centralised approach has induced severe privacy risks to personal data leakage, misuse, and abuse. Furthermore, in the era of the Internet of Things and big data in which data is essentially distributed, transferring a vast amount of data to a data centre for processing seems to be a cumbersome solution. This is not only because of the difficulties in transferring and sharing data across data sources but also the challenges on complying with rigorous data protection regulations and complicated administrative procedures such as the EU General Data Protection Regulation (GDPR). In this respect, Federated learning (FL) emerges as a prospective solution that facilitates distributed collaborative learning without disclosing original training data whilst naturally complying with the GDPR. Recent research has demonstrated that retaining data and computation on-device in FL is not sufficient enough for privacy-guarantee. This is because ML model parameters exchanged between parties in an FL system still conceal sensitive information, which can be exploited in some privacy attacks. Therefore, FL systems shall be empowered by efficient privacy-preserving techniques to comply with the GDPR. This article is dedicated to surveying on the state-of-the-art privacy-preserving techniques which can be employed in FL in a systematic fashion, as well as how these techniques mitigate data security and privacy risks. Furthermore, we provide insights into the challenges along with prospective approaches following the GDPR regulatory guidelines that an FL system shall implement to comply with the GDPR.