 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Preservation in Federated Learning: Insights from the GDPR Perspective
Paper and Code
Nov 13, 2020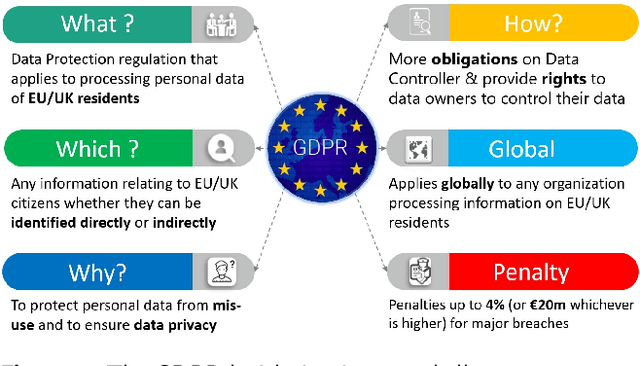

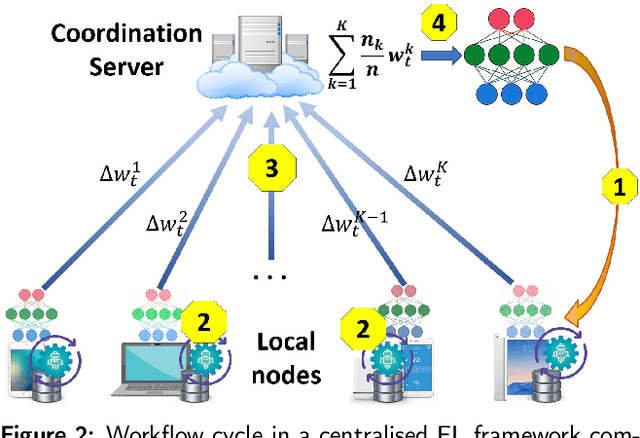
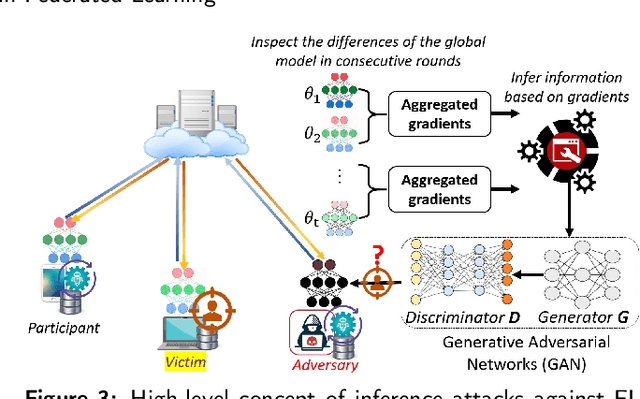
Along with the blooming of AI and Machine Learning-based applications and services, data privacy and security have become a critical challenge. Conventionally, data is collected and aggregated in a data centre on which machine learning models are trained. This centralised approach has induced severe privacy risks to personal data leakage, misuse, and abuse. Furthermore, in the era of the Internet of Things and big data in which data is essentially distributed, transferring a vast amount of data to a data centre for processing seems to be a cumbersome solution. This is not only because of the difficulties in transferring and sharing data across data sources but also the challenges on complying with rigorous data protection regulations and complicated administrative procedures such as the EU General Data Protection Regulation (GDPR). In this respect, Federated learning (FL) emerges as a prospective solution that facilitates distributed collaborative learning without disclosing original training data whilst naturally complying with the GDPR. Recent research has demonstrated that retaining data and computation on-device in FL is not sufficient enough for privacy-guarantee. This is because ML model parameters exchanged between parties in an FL system still conceal sensitive information, which can be exploited in some privacy attacks. Therefore, FL systems shall be empowered by efficient privacy-preserving techniques to comply with the GDPR. This article is dedicated to surveying on the state-of-the-art privacy-preserving techniques which can be employed in FL in a systematic fashion, as well as how these techniques mitigate data security and privacy risks. Furthermore, we provide insights into the challenges along with prospective approaches following the GDPR regulatory guidelines that an FL system shall implement to comply with the GDPR.