 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOAI: A methodology for evaluating the impact of indoor airflow in the transmission of COVID-19
Mar 31, 2021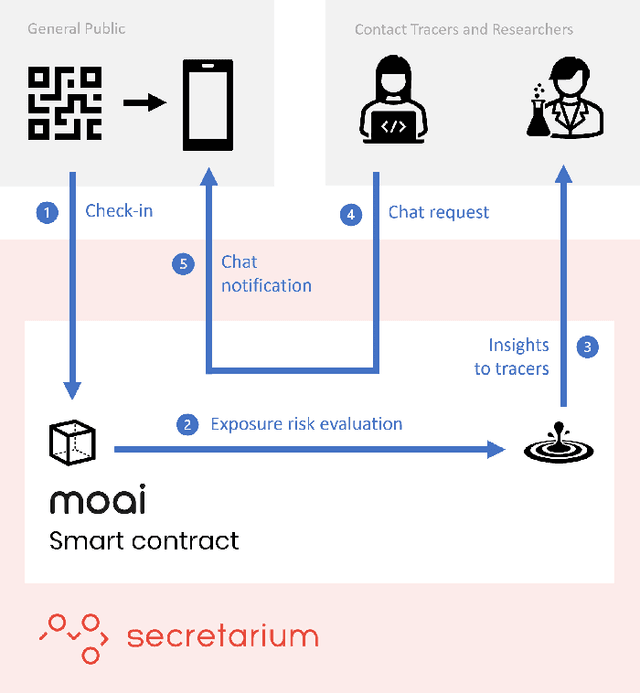
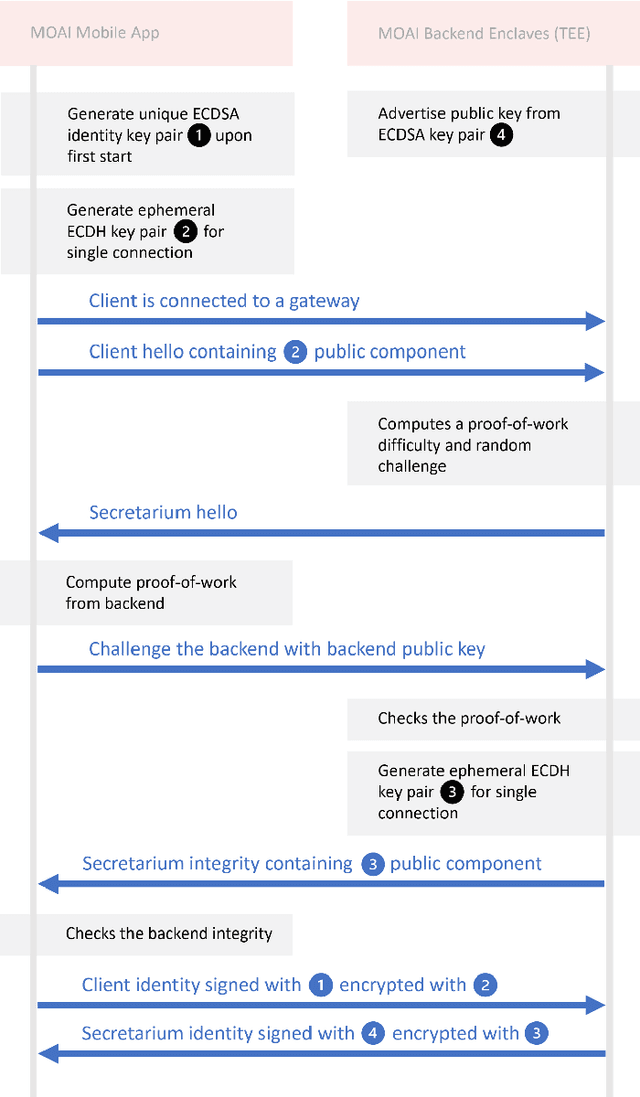
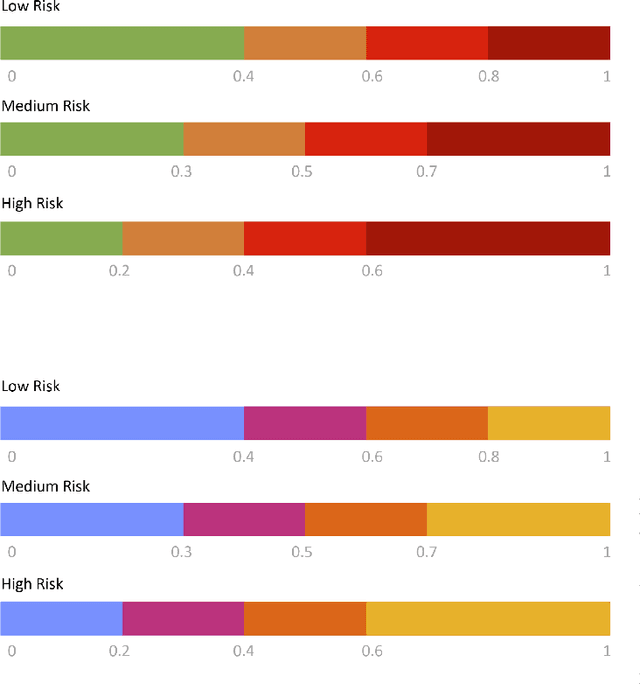
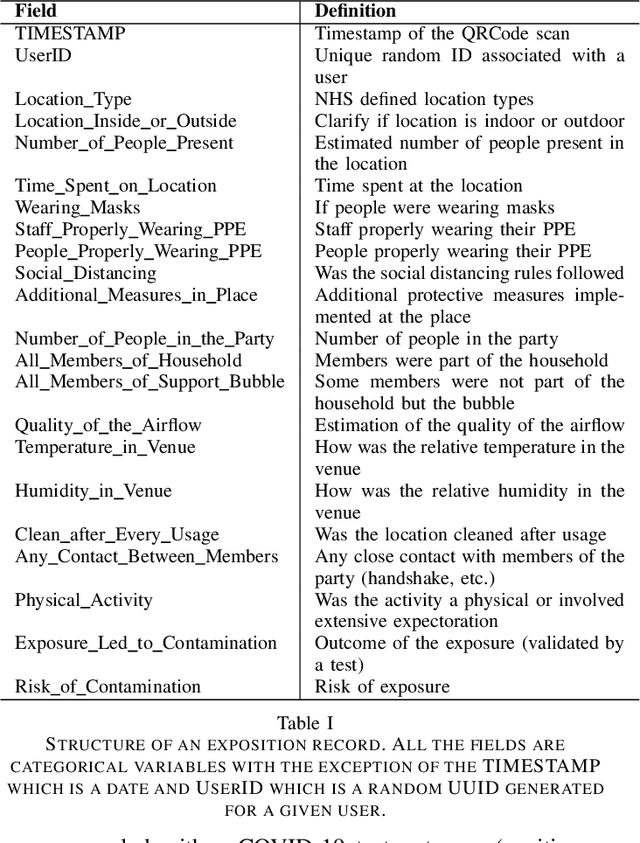
Epidemiology models play a key role in understanding and responding to the COVID-19 pandemic. In order to build those models, scientists need to understand contributing factors and their relative importance. A large strand of literature has identified the importance of airflow to mitigate droplets and far-field aerosol transmission risks. However, the specific factors contributing to higher or lower contamination in various settings have not been clearly defined and quantified. As part of the MOAI project (https://moaiapp.com), we are developing a privacy-preserving test and trace app to enable infection cluster investigators to get in touch with patients without having to know their identity. This approach allows involving users in the fight against the pandemic by contributing additional information in the form of anonymous research questionnaires. We first describe how the questionnaire was designed, and the synthetic data was generated based on a review we carried out on the latest available literature. We then present a model to evaluate the risk exposition of a user for a given setting. We finally propose a temporal addition to the model to evaluate the risk exposure over time for a given user.
Privacy Preservation in Federated Learning: Insights from the GDPR Perspective
Nov 13, 2020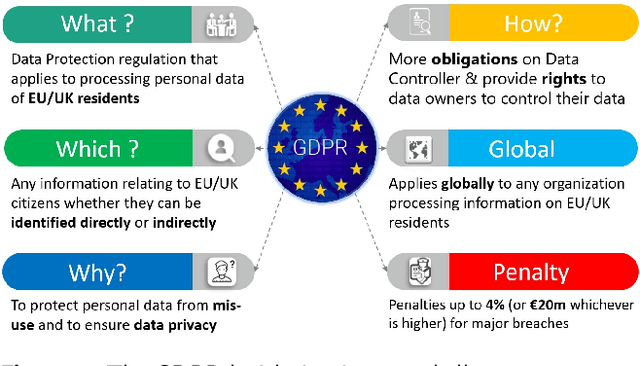

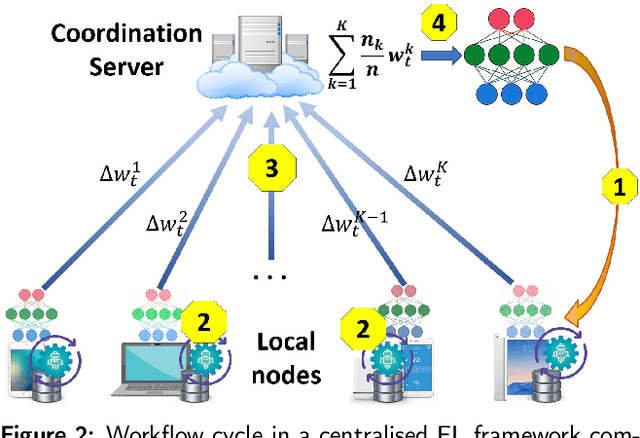
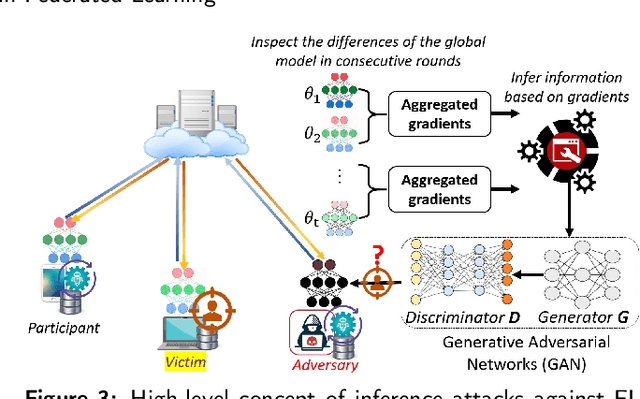
Along with the blooming of AI and Machine Learning-based applications and services, data privacy and security have become a critical challenge. Conventionally, data is collected and aggregated in a data centre on which machine learning models are trained. This centralised approach has induced severe privacy risks to personal data leakage, misuse, and abuse. Furthermore, in the era of the Internet of Things and big data in which data is essentially distributed, transferring a vast amount of data to a data centre for processing seems to be a cumbersome solution. This is not only because of the difficulties in transferring and sharing data across data sources but also the challenges on complying with rigorous data protection regulations and complicated administrative procedures such as the EU General Data Protection Regulation (GDPR). In this respect, Federated learning (FL) emerges as a prospective solution that facilitates distributed collaborative learning without disclosing original training data whilst naturally complying with the GDPR. Recent research has demonstrated that retaining data and computation on-device in FL is not sufficient enough for privacy-guarantee. This is because ML model parameters exchanged between parties in an FL system still conceal sensitive information, which can be exploited in some privacy attacks. Therefore, FL systems shall be empowered by efficient privacy-preserving techniques to comply with the GDPR. This article is dedicated to surveying on the state-of-the-art privacy-preserving techniques which can be employed in FL in a systematic fashion, as well as how these techniques mitigate data security and privacy risks. Furthermore, we provide insights into the challenges along with prospective approaches following the GDPR regulatory guidelines that an FL system shall implement to comply with the GDPR.
Self-Supervised Learning for Cardiac MR Image Segmentation by Anatomical Position Prediction
Jul 05, 2019
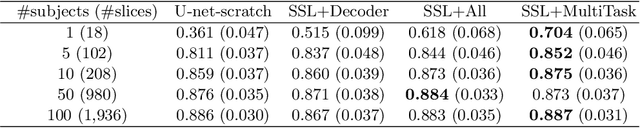

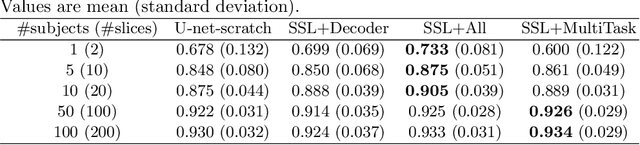
In the recent years, convolutional neural networks have transformed the field of medical image analysis due to their capacity to learn discriminative image features for a variety of classification and regression tasks. However, successfully learning these features requires a large amount of manually annotated data, which is expensive to acquire and limited by the available resources of expert image analysts. Therefore, unsupervised, weakly-supervised and self-supervised feature learning techniques receive a lot of attention, which aim to utilise the vast amount of available data, while at the same time avoid or substantially reduce the effort of manual annotation. In this paper, we propose a novel way for training a cardiac MR image segmentation network, in which features are learnt in a self-supervised manner by predicting anatomical positions. The anatomical positions serve as a supervisory signal and do not require extra manual annotation. We demonstrate that this seemingly simple task provides a strong signal for feature learning and with self-supervised learning, we achieve a high segmentation accuracy that is better than or comparable to a U-net trained from scratch, especially at a small data setting. When only five annotated subjects are available, the proposed method improves the mean Dice metric from 0.811 to 0.852 for short-axis image segmentation, compared to the baseline U-net.