 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProof of Reasoning for Privacy Enhanced Federated Blockchain Learning at the Edge
Jan 12, 2026Consensus mechanisms are the core of any blockchain system. However, the majority of these mechanisms do not target federated learning directly nor do they aid in the aggregation step. This paper introduces Proof of Reasoning (PoR), a novel consensus mechanism specifically designed for federated learning using blockchain, aimed at preserving data privacy, defending against malicious attacks, and enhancing the validation of participating networks. Unlike generic blockchain consensus mechanisms commonly found in the literature, PoR integrates three distinct processes tailored for federated learning. Firstly, a masked autoencoder (MAE) is trained to generate an encoder that functions as a feature map and obfuscates input data, rendering it resistant to human reconstruction and model inversion attacks. Secondly, a downstream classifier is trained at the edge, receiving input from the trained encoder. The downstream network's weights, a single encoded datapoint, the network's output and the ground truth are then added to a block for federated aggregation. Lastly, this data facilitates the aggregation of all participating networks, enabling more complex and verifiable aggregation methods than previously possible. This three-stage process results in more robust networks with significantly reduced computational complexity, maintaining high accuracy by training only the downstream classifier at the edge. PoR scales to large IoT networks with low latency and storage growth, and adapts to evolving data, regulations, and network conditions.
Dietary Assessment with Multimodal ChatGPT: A Systematic Analysis
Dec 14, 2023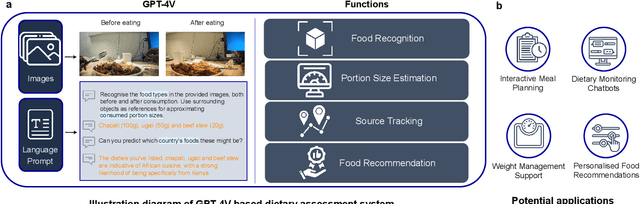

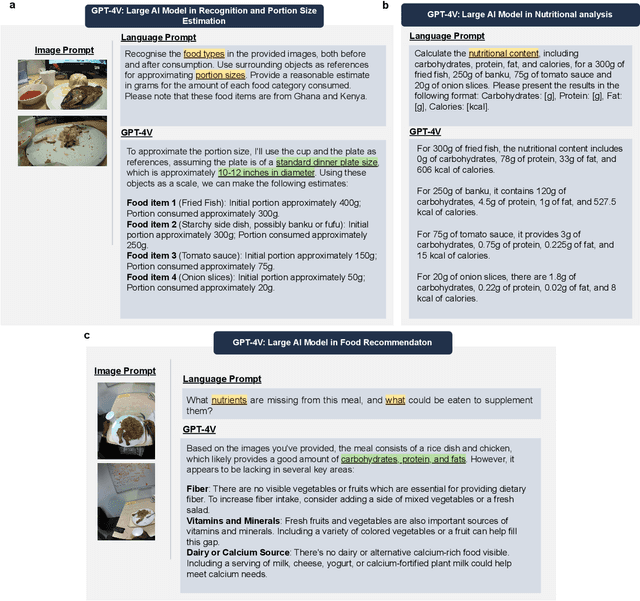

Conventional approaches to dietary assessment are primarily grounded in self-reporting methods or structured interviews conducted under the supervision of dietitians. These methods, however, are often subjective, potentially inaccurate, and time-intensive. Although artificial intelligence (AI)-based solutions have been devised to automate the dietary assessment process, these prior AI methodologies encounter challenges in their ability to generalize across a diverse range of food types, dietary behaviors, and cultural contexts. This results in AI applications in the dietary field that possess a narrow specialization and limited accuracy. Recently, the emergence of multimodal foundation models such as GPT-4V powering the latest ChatGPT has exhibited transformative potential across a wide range of tasks (e.g., Scene understanding and image captioning) in numerous research domains. These models have demonstrated remarkable generalist intelligence and accuracy, capable of processing various data modalities. In this study, we explore the application of multimodal ChatGPT within the realm of dietary assessment. Our findings reveal that GPT-4V excels in food detection under challenging conditions with accuracy up to 87.5% without any fine-tuning or adaptation using food-specific datasets. By guiding the model with specific language prompts (e.g., African cuisine), it shifts from recognizing common staples like rice and bread to accurately identifying regional dishes like banku and ugali. Another GPT-4V's standout feature is its contextual awareness. GPT-4V can leverage surrounding objects as scale references to deduce the portion sizes of food items, further enhancing its accuracy in translating food weight into nutritional content. This alignment with the USDA National Nutrient Database underscores GPT-4V's potential to advance nutritional science and dietary assessment techniques.
VisionFM: a Multi-Modal Multi-Task Vision Foundation Model for Generalist Ophthalmic Artificial Intelligence
Oct 08, 2023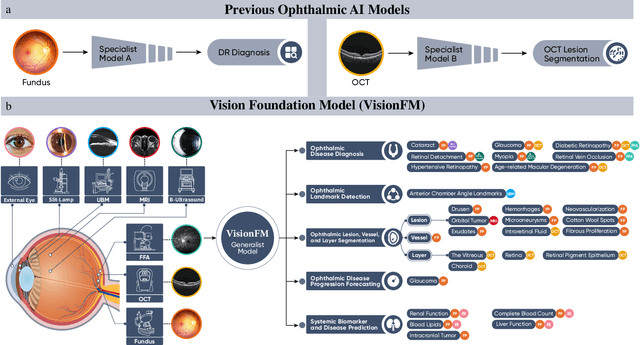
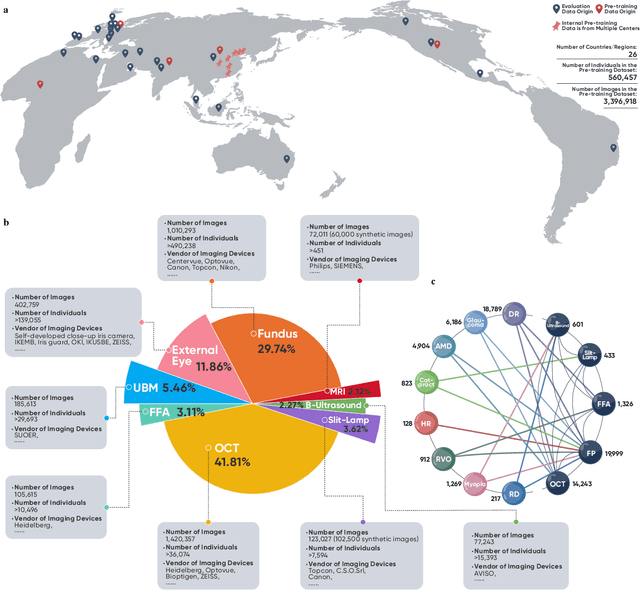

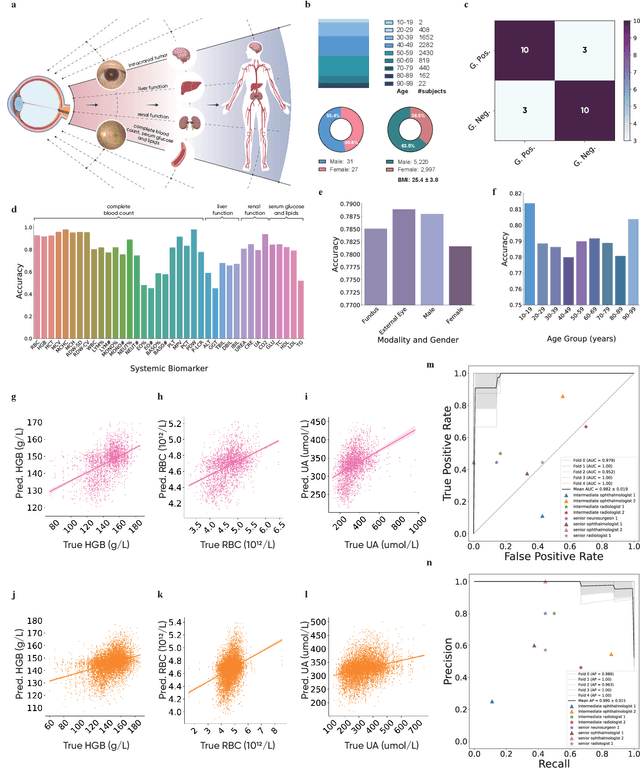
We present VisionFM, a foundation model pre-trained with 3.4 million ophthalmic images from 560,457 individuals, covering a broad range of ophthalmic diseases, modalities, imaging devices, and demography. After pre-training, VisionFM provides a foundation to foster multiple ophthalmic artificial intelligence (AI) applications, such as disease screening and diagnosis, disease prognosis, subclassification of disease phenotype, and systemic biomarker and disease prediction, with each application enhanced with expert-level intelligence and accuracy. The generalist intelligence of VisionFM outperformed ophthalmologists with basic and intermediate levels in jointly diagnosing 12 common ophthalmic diseases. Evaluated on a new large-scale ophthalmic disease diagnosis benchmark database, as well as a new large-scale segmentation and detection benchmark database, VisionFM outperformed strong baseline deep neural networks. The ophthalmic image representations learned by VisionFM exhibited noteworthy explainability, and demonstrated strong generalizability to new ophthalmic modalities, disease spectrum, and imaging devices. As a foundation model, VisionFM has a large capacity to learn from diverse ophthalmic imaging data and disparate datasets. To be commensurate with this capacity, in addition to the real data used for pre-training, we also generated and leveraged synthetic ophthalmic imaging data. Experimental results revealed that synthetic data that passed visual Turing tests, can also enhance the representation learning capability of VisionFM, leading to substantial performance gains on downstream ophthalmic AI tasks. Beyond the ophthalmic AI applications developed, validated, and demonstrated in this work, substantial further applications can be achieved in an efficient and cost-effective manner using VisionFM as the foundation.
IoT Federated Blockchain Learning at the Edge
Apr 06, 2023IoT devices are sorely underutilized in the medical field, especially within machine learning for medicine, yet they offer unrivaled benefits. IoT devices are low-cost, energy-efficient, small and intelligent devices. In this paper, we propose a distributed federated learning framework for IoT devices, more specifically for IoMT (Internet of Medical Things), using blockchain to allow for a decentralized scheme improving privacy and efficiency over a centralized system; this allows us to move from the cloud-based architectures, that are prevalent, to the edge. The system is designed for three paradigms: 1) Training neural networks on IoT devices to allow for collaborative training of a shared model whilst decoupling the learning from the dataset to ensure privacy. Training is performed in an online manner simultaneously amongst all participants, allowing for the training of actual data that may not have been present in a dataset collected in the traditional way and dynamically adapt the system whilst it is being trained. 2) Training of an IoMT system in a fully private manner such as to mitigate the issue with confidentiality of medical data and to build robust, and potentially bespoke, models where not much, if any, data exists. 3) Distribution of the actual network training, something federated learning itself does not do, to allow hospitals, for example, to utilize their spare computing resources to train network models.
Large AI Models in Health Informatics: Applications, Challenges, and the Future
Mar 21, 2023



Large AI models, or foundation models, are models recently emerging with massive scales both parameter-wise and data-wise, the magnitudes of which often reach beyond billions. Once pretrained, large AI models demonstrate impressive performance in various downstream tasks. A concrete example is the recent debut of ChatGPT, whose capability has compelled people's imagination about the far-reaching influence that large AI models can have and their potential to transform different domains of our life. In health informatics, the advent of large AI models has brought new paradigms for the design of methodologies. The scale of multimodality data in the biomedical and health domain has been ever-expanding especially since the community embraced the era of deep learning, which provides the ground to develop, validate, and advance large AI models for breakthroughs in health-related areas. This article presents an up-to-date comprehensive review of large AI models, from background to their applications. We identify seven key sectors that large AI models are applicable and might have substantial influence, including 1) molecular biology and drug discovery; 2) medical diagnosis and decision-making; 3) medical imaging and vision; 4) medical informatics; 5) medical education; 6) public health; and 7) medical robotics. We examine their challenges in health informatics, followed by a critical discussion about potential future directions and pitfalls of large AI models in transforming the field of health informatics.
EVEN: An Event-Based Framework for Monocular Depth Estimation at Adverse Night Conditions
Feb 08, 2023



Accurate depth estimation under adverse night conditions has practical impact and applications, such as on autonomous driving and rescue robots. In this work, we studied monocular depth estimation at night time in which various adverse weather, light, and different road conditions exist, with data captured in both RGB and event modalities. Event camera can better capture intensity changes by virtue of its high dynamic range (HDR), which is particularly suitable to be applied at adverse night conditions in which the amount of light is limited in the scene. Although event data can retain visual perception that conventional RGB camera may fail to capture, the lack of texture and color information of event data hinders its applicability to accurately estimate depth alone. To tackle this problem, we propose an event-vision based framework that integrates low-light enhancement for the RGB source, and exploits the complementary merits of RGB and event data. A dataset that includes paired RGB and event streams, and ground truth depth maps has been constructed. Comprehensive experiments have been conducted, and the impact of different adverse weather combinations on the performance of framework has also been investigated. The results have shown that our proposed framework can better estimate monocular depth at adverse nights than six baselines.
MenuAI: Restaurant Food Recommendation System via a Transformer-based Deep Learning Model
Oct 15, 2022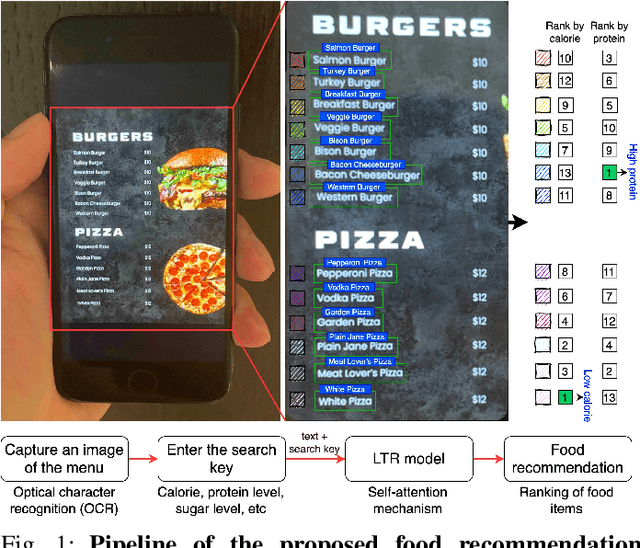
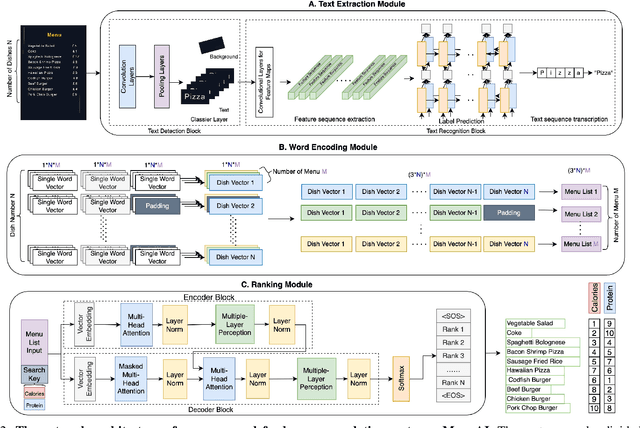
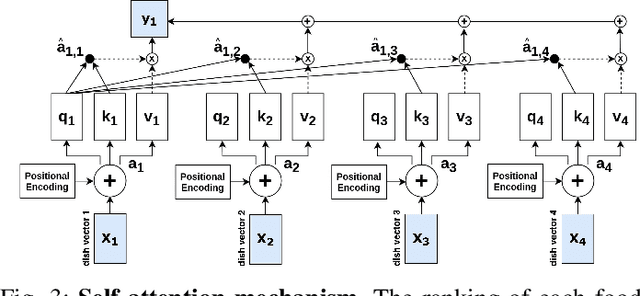
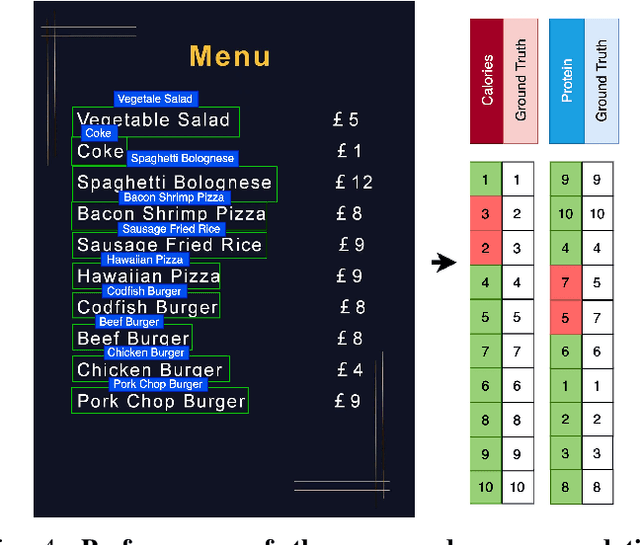
Food recommendation system has proven as an effective technology to provide guidance on dietary choices, and this is especially important for patients suffering from chronic diseases. Unlike other multimedia recommendations, such as books and movies, food recommendation task is highly relied on the context at the moment, since users' food preference can be highly dynamic over time. For example, individuals tend to eat more calories earlier in the day and eat a little less at dinner. However, there are still limited research works trying to incorporate both current context and nutritional knowledge for food recommendation. Thus, a novel restaurant food recommendation system is proposed in this paper to recommend food dishes to users according to their special nutritional needs. Our proposed system utilises Optical Character Recognition (OCR) technology and a transformer-based deep learning model, Learning to Rank (LTR) model, to conduct food recommendation. Given a single RGB image of the menu, the system is then able to rank the food dishes in terms of the input search key (e.g., calorie, protein level). Due to the property of the transformer, our system can also rank unseen food dishes. Comprehensive experiments are conducted to validate our methods on a self-constructed menu dataset, known as MenuRank dataset. The promising results, with accuracy ranging from 77.2% to 99.5%, have demonstrated the great potential of LTR model in addressing food recommendation problems.
Revisiting Self-Supervised Contrastive Learning for Facial Expression Recognition
Oct 08, 2022
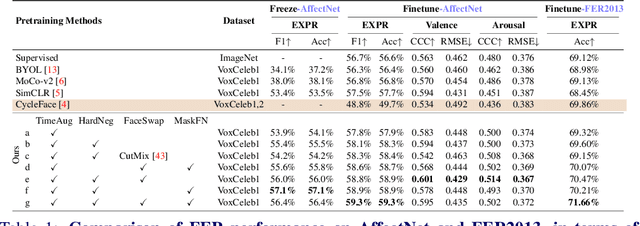


The success of most advanced facial expression recognition works relies heavily on large-scale annotated datasets. However, it poses great challenges in acquiring clean and consistent annotations for facial expression datasets. On the other hand, self-supervised contrastive learning has gained great popularity due to its simple yet effective instance discrimination training strategy, which can potentially circumvent the annotation issue. Nevertheless, there remain inherent disadvantages of instance-level discrimination, which are even more challenging when faced with complicated facial representations. In this paper, we revisit the use of self-supervised contrastive learning and explore three core strategies to enforce expression-specific representations and to minimize the interference from other facial attributes, such as identity and face styling. Experimental results show that our proposed method outperforms the current state-of-the-art self-supervised learning methods, in terms of both categorical and dimensional facial expression recognition tasks.
Clustering Egocentric Images in Passive Dietary Monitoring with Self-Supervised Learning
Aug 25, 2022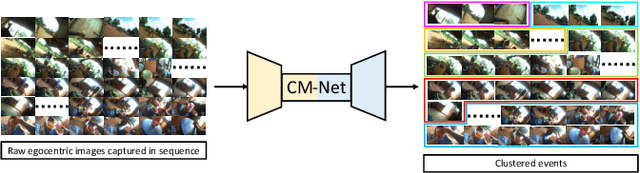
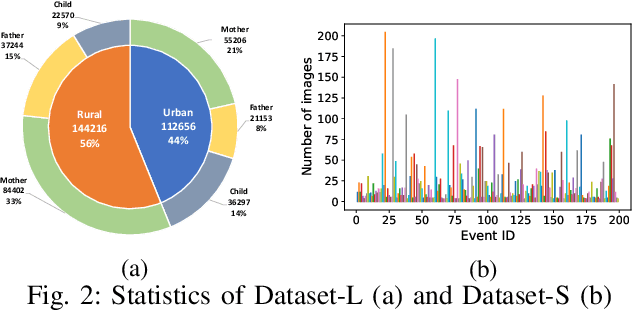
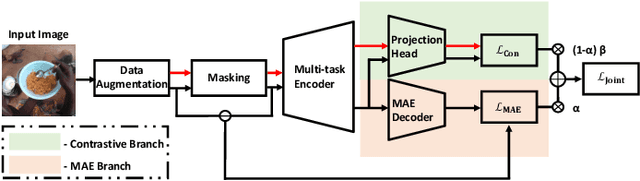
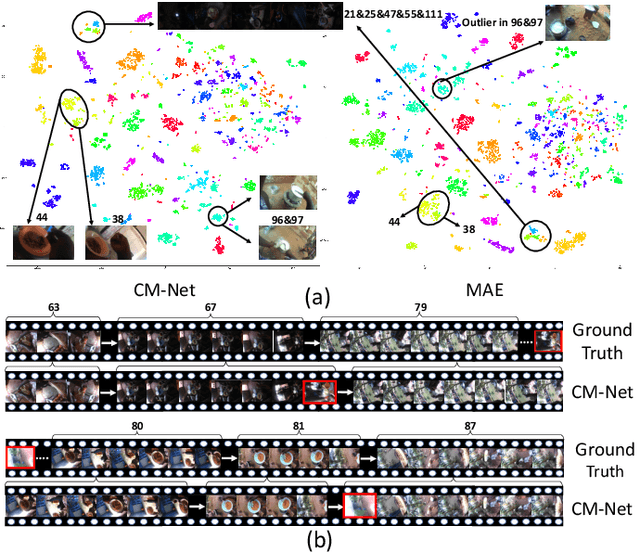
In our recent dietary assessment field studies on passive dietary monitoring in Ghana, we have collected over 250k in-the-wild images. The dataset is an ongoing effort to facilitate accurate measurement of individual food and nutrient intake in low and middle income countries with passive monitoring camera technologies. The current dataset involves 20 households (74 subjects) from both the rural and urban regions of Ghana, and two different types of wearable cameras were used in the studies. Once initiated, wearable cameras continuously capture subjects' activities, which yield massive amounts of data to be cleaned and annotated before analysis is conducted. To ease the data post-processing and annotation tasks, we propose a novel self-supervised learning framework to cluster the large volume of egocentric images into separate events. Each event consists of a sequence of temporally continuous and contextually similar images. By clustering images into separate events, annotators and dietitians can examine and analyze the data more efficiently and facilitate the subsequent dietary assessment processes. Validated on a held-out test set with ground truth labels, the proposed framework outperforms baselines in terms of clustering quality and classification accuracy.
Tackling Long-Tailed Category Distribution Under Domain Shifts
Jul 20, 2022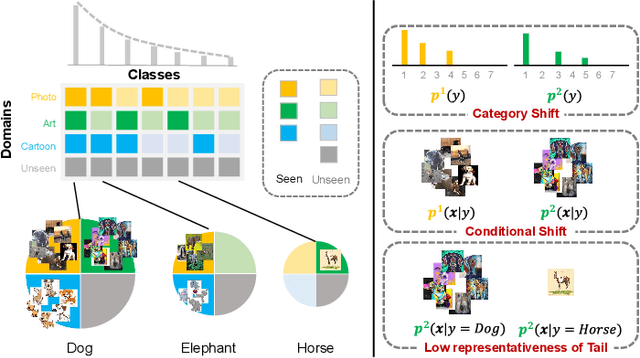

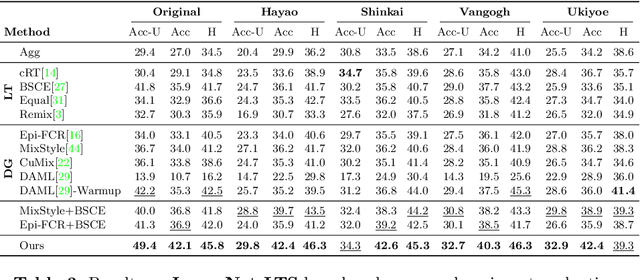
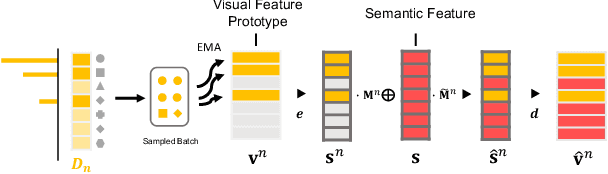
Machine learning models fail to perform well on real-world applications when 1) the category distribution P(Y) of the training dataset suffers from long-tailed distribution and 2) the test data is drawn from different conditional distributions P(X|Y). Existing approaches cannot handle the scenario where both issues exist, which however is common for real-world applications. In this study, we took a step forward and looked into the problem of long-tailed classification under domain shifts. We designed three novel core functional blocks including Distribution Calibrated Classification Loss, Visual-Semantic Mapping and Semantic-Similarity Guided Augmentation. Furthermore, we adopted a meta-learning framework which integrates these three blocks to improve domain generalization on unseen target domains. Two new datasets were proposed for this problem, named AWA2-LTS and ImageNet-LTS. We evaluated our method on the two datasets and extensive experimental results demonstrate that our proposed method can achieve superior performance over state-of-the-art long-tailed/domain generalization approaches and the combinations. Source codes and datasets can be found at our project page https://xiaogu.site/LTDS.