 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Conditional Computation: Retrieval-Augmented Genomic Foundation Models with Gengram
Jan 29, 2026Current genomic foundation models (GFMs) rely on extensive neural computation to implicitly approximate conserved biological motifs from single-nucleotide inputs. We propose Gengram, a conditional memory module that introduces an explicit and highly efficient lookup primitive for multi-base motifs via a genomic-specific hashing scheme, establishing genomic "syntax". Integrated into the backbone of state-of-the-art GFMs, Gengram achieves substantial gains (up to 14%) across several functional genomics tasks. The module demonstrates robust architectural generalization, while further inspection of Gengram's latent space reveals the emergence of meaningful representations that align closely with fundamental biological knowledge. By establishing structured motif memory as a modeling primitive, Gengram simultaneously boosts empirical performance and mechanistic interpretability, providing a scalable and biology-aligned pathway for the next generation of GFMs. The code is available at https://github.com/zhejianglab/Genos, and the model checkpoint is available at https://huggingface.co/ZhejiangLab/Gengram.
DASP: Self-supervised Nighttime Monocular Depth Estimation with Domain Adaptation of Spatiotemporal Priors
Dec 16, 2025Self-supervised monocular depth estimation has achieved notable success under daytime conditions. However, its performance deteriorates markedly at night due to low visibility and varying illumination, e.g., insufficient light causes textureless areas, and moving objects bring blurry regions. To this end, we propose a self-supervised framework named DASP that leverages spatiotemporal priors for nighttime depth estimation. Specifically, DASP consists of an adversarial branch for extracting spatiotemporal priors and a self-supervised branch for learning. In the adversarial branch, we first design an adversarial network where the discriminator is composed of four devised spatiotemporal priors learning blocks (SPLB) to exploit the daytime priors. In particular, the SPLB contains a spatial-based temporal learning module (STLM) that uses orthogonal differencing to extract motion-related variations along the time axis and an axial spatial learning module (ASLM) that adopts local asymmetric convolutions with global axial attention to capture the multiscale structural information. By combining STLM and ASLM, our model can acquire sufficient spatiotemporal features to restore textureless areas and estimate the blurry regions caused by dynamic objects. In the self-supervised branch, we propose a 3D consistency projection loss to bilaterally project the target frame and source frame into a shared 3D space, and calculate the 3D discrepancy between the two projected frames as a loss to optimize the 3D structural consistency and daytime priors. Extensive experiments on the Oxford RobotCar and nuScenes datasets demonstrate that our approach achieves state-of-the-art performance for nighttime depth estimation. Ablation studies further validate the effectiveness of each component.
Multi-Agent Systems for Robotic Autonomy with LLMs
May 09, 2025Since the advent of Large Language Models (LLMs), various research based on such models have maintained significant academic attention and impact, especially in AI and robotics. In this paper, we propose a multi-agent framework with LLMs to construct an integrated system for robotic task analysis, mechanical design, and path generation. The framework includes three core agents: Task Analyst, Robot Designer, and Reinforcement Learning Designer. Outputs are formatted as multimodal results, such as code files or technical reports, for stronger understandability and usability. To evaluate generalizability comparatively, we conducted experiments with models from both GPT and DeepSeek. Results demonstrate that the proposed system can design feasible robots with control strategies when appropriate task inputs are provided, exhibiting substantial potential for enhancing the efficiency and accessibility of robotic system development in research and industrial applications.
A Clinician-Friendly Platform for Ophthalmic Image Analysis Without Technical Barriers
Apr 22, 2025Artificial intelligence (AI) shows remarkable potential in medical imaging diagnostics, but current models typically require retraining when deployed across different clinical centers, limiting their widespread adoption. We introduce GlobeReady, a clinician-friendly AI platform that enables ocular disease diagnosis without retraining/fine-tuning or technical expertise. GlobeReady achieves high accuracy across imaging modalities: 93.9-98.5% for an 11-category fundus photo dataset and 87.2-92.7% for a 15-category OCT dataset. Through training-free local feature augmentation, it addresses domain shifts across centers and populations, reaching an average accuracy of 88.9% across five centers in China, 86.3% in Vietnam, and 90.2% in the UK. The built-in confidence-quantifiable diagnostic approach further boosted accuracy to 94.9-99.4% (fundus) and 88.2-96.2% (OCT), while identifying out-of-distribution cases at 86.3% (49 CFP categories) and 90.6% (13 OCT categories). Clinicians from multiple countries rated GlobeReady highly (average 4.6 out of 5) for its usability and clinical relevance. These results demonstrate GlobeReady's robust, scalable diagnostic capability and potential to support ophthalmic care without technical barriers.
DistillGrasp: Integrating Features Correlation with Knowledge Distillation for Depth Completion of Transparent Objects
Aug 01, 2024Due to the visual properties of reflection and refraction, RGB-D cameras cannot accurately capture the depth of transparent objects, leading to incomplete depth maps. To fill in the missing points, recent studies tend to explore new visual features and design complex networks to reconstruct the depth, however, these approaches tremendously increase computation, and the correlation of different visual features remains a problem. To this end, we propose an efficient depth completion network named DistillGrasp which distillates knowledge from the teacher branch to the student branch. Specifically, in the teacher branch, we design a position correlation block (PCB) that leverages RGB images as the query and key to search for the corresponding values, guiding the model to establish correct correspondence between two features and transfer it to the transparent areas. For the student branch, we propose a consistent feature correlation module (CFCM) that retains the reliable regions of RGB images and depth maps respectively according to the consistency and adopts a CNN to capture the pairwise relationship for depth completion. To avoid the student branch only learning regional features from the teacher branch, we devise a distillation loss that not only considers the distance loss but also the object structure and edge information. Extensive experiments conducted on the ClearGrasp dataset manifest that our teacher network outperforms state-of-the-art methods in terms of accuracy and generalization, and the student network achieves competitive results with a higher speed of 48 FPS. In addition, the significant improvement in a real-world robotic grasping system illustrates the effectiveness and robustness of our proposed system.
Leveraging Data Mining, Active Learning, and Domain Adaptation in a Multi-Stage, Machine Learning-Driven Approach for the Efficient Discovery of Advanced Acidic Oxygen Evolution Electrocatalysts
Jul 05, 2024



Developing advanced catalysts for acidic oxygen evolution reaction (OER) is crucial for sustainable hydrogen production. This study introduces a novel, multi-stage machine learning (ML) approach to streamline the discovery and optimization of complex multi-metallic catalysts. Our method integrates data mining, active learning, and domain adaptation throughout the materials discovery process. Unlike traditional trial-and-error methods, this approach systematically narrows the exploration space using domain knowledge with minimized reliance on subjective intuition. Then the active learning module efficiently refines element composition and synthesis conditions through iterative experimental feedback. The process culminated in the discovery of a promising Ru-Mn-Ca-Pr oxide catalyst. Our workflow also enhances theoretical simulations with domain adaptation strategy, providing deeper mechanistic insights aligned with experimental findings. By leveraging diverse data sources and multiple ML strategies, we establish an efficient pathway for electrocatalyst discovery and optimization. This comprehensive, data-driven approach represents a paradigm shift and potentially new benchmark in electrocatalysts research.
Dietary Assessment with Multimodal ChatGPT: A Systematic Analysis
Dec 14, 2023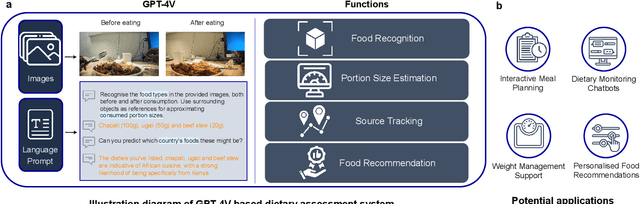

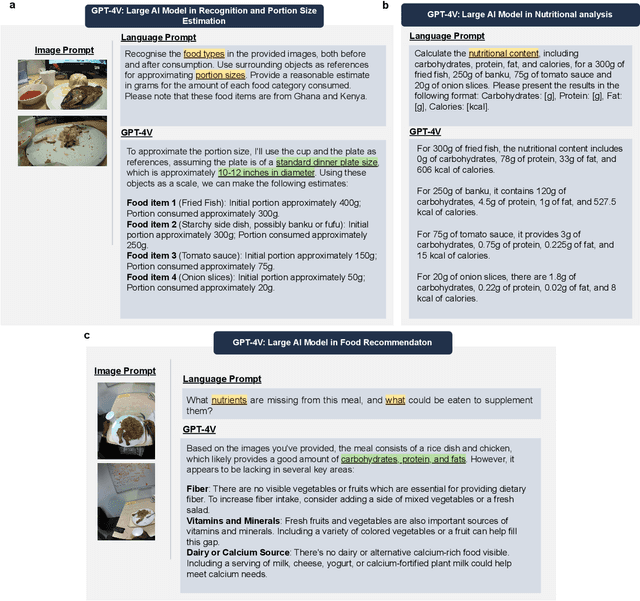

Conventional approaches to dietary assessment are primarily grounded in self-reporting methods or structured interviews conducted under the supervision of dietitians. These methods, however, are often subjective, potentially inaccurate, and time-intensive. Although artificial intelligence (AI)-based solutions have been devised to automate the dietary assessment process, these prior AI methodologies encounter challenges in their ability to generalize across a diverse range of food types, dietary behaviors, and cultural contexts. This results in AI applications in the dietary field that possess a narrow specialization and limited accuracy. Recently, the emergence of multimodal foundation models such as GPT-4V powering the latest ChatGPT has exhibited transformative potential across a wide range of tasks (e.g., Scene understanding and image captioning) in numerous research domains. These models have demonstrated remarkable generalist intelligence and accuracy, capable of processing various data modalities. In this study, we explore the application of multimodal ChatGPT within the realm of dietary assessment. Our findings reveal that GPT-4V excels in food detection under challenging conditions with accuracy up to 87.5% without any fine-tuning or adaptation using food-specific datasets. By guiding the model with specific language prompts (e.g., African cuisine), it shifts from recognizing common staples like rice and bread to accurately identifying regional dishes like banku and ugali. Another GPT-4V's standout feature is its contextual awareness. GPT-4V can leverage surrounding objects as scale references to deduce the portion sizes of food items, further enhancing its accuracy in translating food weight into nutritional content. This alignment with the USDA National Nutrient Database underscores GPT-4V's potential to advance nutritional science and dietary assessment techniques.
Uncertainty-inspired Open Set Learning for Retinal Anomaly Identification
Apr 08, 2023
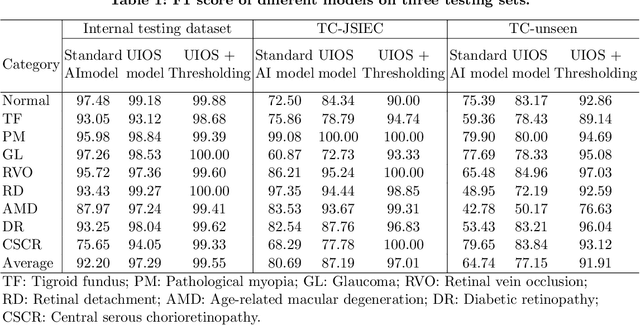


Failure to recognize samples from the classes unseen during training is a major limit of artificial intelligence (AI) in real-world implementation of retinal anomaly classification. To resolve this obstacle, we propose an uncertainty-inspired open-set (UIOS) model which was trained with fundus images of 9 common retinal conditions. Besides the probability of each category, UIOS also calculates an uncertainty score to express its confidence. Our UIOS model with thresholding strategy achieved an F1 score of 99.55%, 97.01% and 91.91% for the internal testing set, external testing set and non-typical testing set, respectively, compared to the F1 score of 92.20%, 80.69% and 64.74% by the standard AI model. Furthermore, UIOS correctly predicted high uncertainty scores, which prompted the need for a manual check, in the datasets of rare retinal diseases, low-quality fundus images, and non-fundus images. This work provides a robust method for real-world screening of retinal anomalies.
Human-Robot Shared Control for Surgical Robot Based on Context-Aware Sim-to-Real Adaptation
Apr 23, 2022



Human-robot shared control, which integrates the advantages of both humans and robots, is an effective approach to facilitate efficient surgical operation. Learning from demonstration (LfD) techniques can be used to automate some of the surgical subtasks for the construction of the shared control mechanism. However, a sufficient amount of data is required for the robot to learn the manoeuvres. Using a surgical simulator to collect data is a less resource-demanding approach. With sim-to-real adaptation, the manoeuvres learned from a simulator can be transferred to a physical robot. To this end, we propose a sim-to-real adaptation method to construct a human-robot shared control framework for robotic surgery. In this paper, a desired trajectory is generated from a simulator using LfD method, while dynamic motion primitives (DMP) is used to transfer the desired trajectory from the simulator to the physical robotic platform. Moreover, a role adaptation mechanism is developed such that the robot can adjust its role according to the surgical operation contexts predicted by a neural network model. The effectiveness of the proposed framework is validated on the da Vinci Research Kit (dVRK). Results of the user studies indicated that with the adaptive human-robot shared control framework, the path length of the remote controller, the total clutching number and the task completion time can be reduced significantly. The proposed method outperformed the traditional manual control via teleoperation.