 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDASP: Self-supervised Nighttime Monocular Depth Estimation with Domain Adaptation of Spatiotemporal Priors
Dec 16, 2025Self-supervised monocular depth estimation has achieved notable success under daytime conditions. However, its performance deteriorates markedly at night due to low visibility and varying illumination, e.g., insufficient light causes textureless areas, and moving objects bring blurry regions. To this end, we propose a self-supervised framework named DASP that leverages spatiotemporal priors for nighttime depth estimation. Specifically, DASP consists of an adversarial branch for extracting spatiotemporal priors and a self-supervised branch for learning. In the adversarial branch, we first design an adversarial network where the discriminator is composed of four devised spatiotemporal priors learning blocks (SPLB) to exploit the daytime priors. In particular, the SPLB contains a spatial-based temporal learning module (STLM) that uses orthogonal differencing to extract motion-related variations along the time axis and an axial spatial learning module (ASLM) that adopts local asymmetric convolutions with global axial attention to capture the multiscale structural information. By combining STLM and ASLM, our model can acquire sufficient spatiotemporal features to restore textureless areas and estimate the blurry regions caused by dynamic objects. In the self-supervised branch, we propose a 3D consistency projection loss to bilaterally project the target frame and source frame into a shared 3D space, and calculate the 3D discrepancy between the two projected frames as a loss to optimize the 3D structural consistency and daytime priors. Extensive experiments on the Oxford RobotCar and nuScenes datasets demonstrate that our approach achieves state-of-the-art performance for nighttime depth estimation. Ablation studies further validate the effectiveness of each component.
DistillGrasp: Integrating Features Correlation with Knowledge Distillation for Depth Completion of Transparent Objects
Aug 01, 2024Due to the visual properties of reflection and refraction, RGB-D cameras cannot accurately capture the depth of transparent objects, leading to incomplete depth maps. To fill in the missing points, recent studies tend to explore new visual features and design complex networks to reconstruct the depth, however, these approaches tremendously increase computation, and the correlation of different visual features remains a problem. To this end, we propose an efficient depth completion network named DistillGrasp which distillates knowledge from the teacher branch to the student branch. Specifically, in the teacher branch, we design a position correlation block (PCB) that leverages RGB images as the query and key to search for the corresponding values, guiding the model to establish correct correspondence between two features and transfer it to the transparent areas. For the student branch, we propose a consistent feature correlation module (CFCM) that retains the reliable regions of RGB images and depth maps respectively according to the consistency and adopts a CNN to capture the pairwise relationship for depth completion. To avoid the student branch only learning regional features from the teacher branch, we devise a distillation loss that not only considers the distance loss but also the object structure and edge information. Extensive experiments conducted on the ClearGrasp dataset manifest that our teacher network outperforms state-of-the-art methods in terms of accuracy and generalization, and the student network achieves competitive results with a higher speed of 48 FPS. In addition, the significant improvement in a real-world robotic grasping system illustrates the effectiveness and robustness of our proposed system.
MMED: A Multi-domain and Multi-modality Event Dataset
Apr 09, 2019

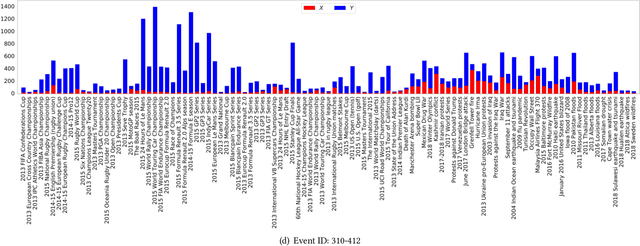
In this work, we construct and release a multi-domain and multi-modality event dataset (MMED), containing 25,165 textual news articles collected from hundreds of news media sites (e.g., Yahoo News, Google News, CNN News.) and 76,516 image posts shared on Flickr social media, which are annotated according to 412 real-world events. The dataset is collected to explore the problem of organizing heterogeneous data contributed by professionals and amateurs in different data domains, and the problem of transferring event knowledge obtained from one data domain to heterogeneous data domain, thus summarizing the data with different contributors. We hope that the release of the MMED dataset can stimulate innovate research on related challenging problems, such as event discovery, cross-modal (event) retrieval, and visual question answering, etc.
Learning Shared Semantic Space with Correlation Alignment for Cross-modal Event Retrieval
Jan 15, 2019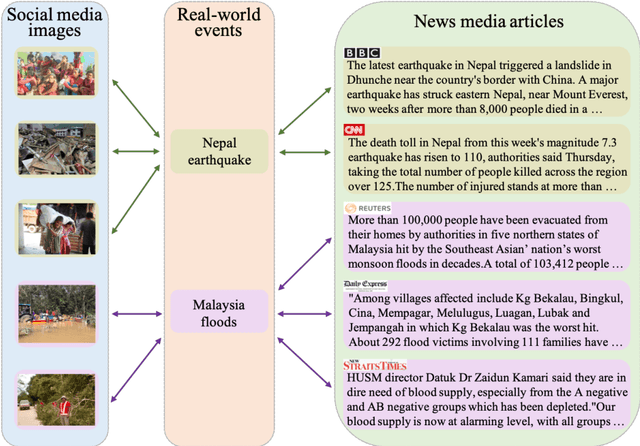

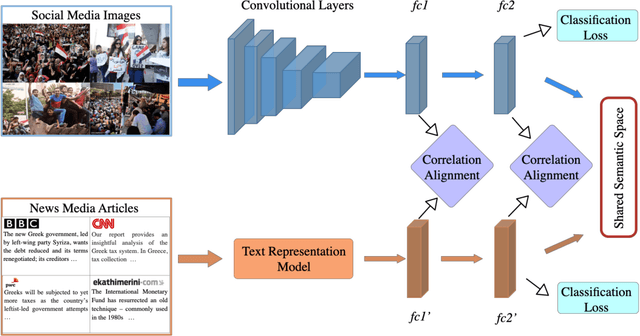
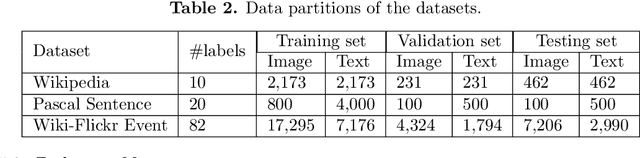
In this paper, we propose to learn shared semantic space with correlation alignment (${S}^{3}CA$) for multimodal data representations, which aligns nonlinear correlations of multimodal data distributions in deep neural networks designed for heterogeneous data. In the context of cross-modal (event) retrieval, we design a neural network with convolutional layers and fully-connected layers to extract features for images, including images on Flickr-like social media. Simultaneously, we exploit a fully-connected neural network to extract semantic features for texts, including news articles from news media. In particular, nonlinear correlations of layer activations in the two neural networks are aligned with correlation alignment during the joint training of the networks. Furthermore, we project the multimodal data into a shared semantic space for cross-modal (event) retrieval, where the distances between heterogeneous data samples can be measured directly. In addition, we contribute a Wiki-Flickr Event dataset, where the multimodal data samples are not describing each other in pairs like the existing paired datasets, but all of them are describing semantic events. Extensive experiments conducted on both paired and unpaired datasets manifest the effectiveness of ${S}^{3}CA$, outperforming the state-of-the-art methods.