 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePairEdit: Learning Semantic Variations for Exemplar-based Image Editing
Jun 09, 2025Recent advancements in text-guided image editing have achieved notable success by leveraging natural language prompts for fine-grained semantic control. However, certain editing semantics are challenging to specify precisely using textual descriptions alone. A practical alternative involves learning editing semantics from paired source-target examples. Existing exemplar-based editing methods still rely on text prompts describing the change within paired examples or learning implicit text-based editing instructions. In this paper, we introduce PairEdit, a novel visual editing method designed to effectively learn complex editing semantics from a limited number of image pairs or even a single image pair, without using any textual guidance. We propose a target noise prediction that explicitly models semantic variations within paired images through a guidance direction term. Moreover, we introduce a content-preserving noise schedule to facilitate more effective semantic learning. We also propose optimizing distinct LoRAs to disentangle the learning of semantic variations from content. Extensive qualitative and quantitative evaluations demonstrate that PairEdit successfully learns intricate semantics while significantly improving content consistency compared to baseline methods. Code will be available at https://github.com/xudonmao/PairEdit.
PSM-SQL: Progressive Schema Learning with Multi-granularity Semantics for Text-to-SQL
Feb 07, 2025
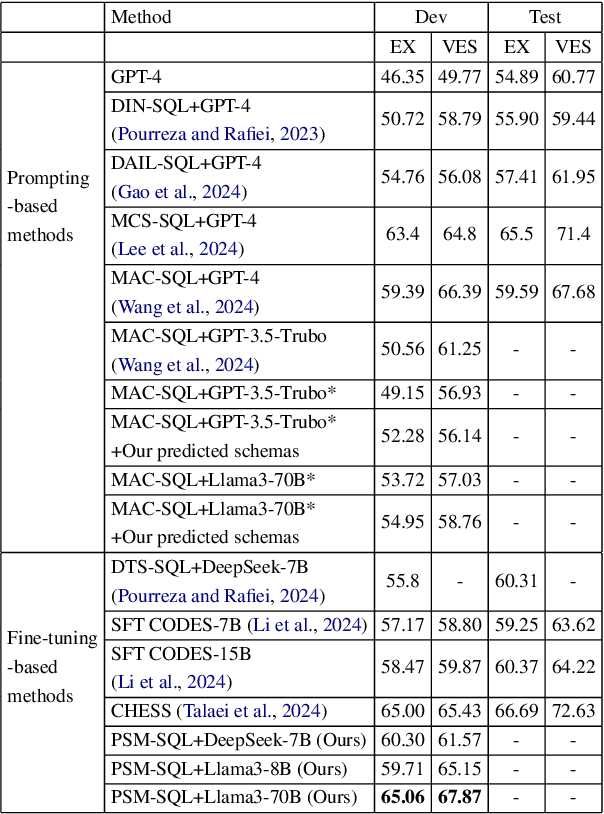

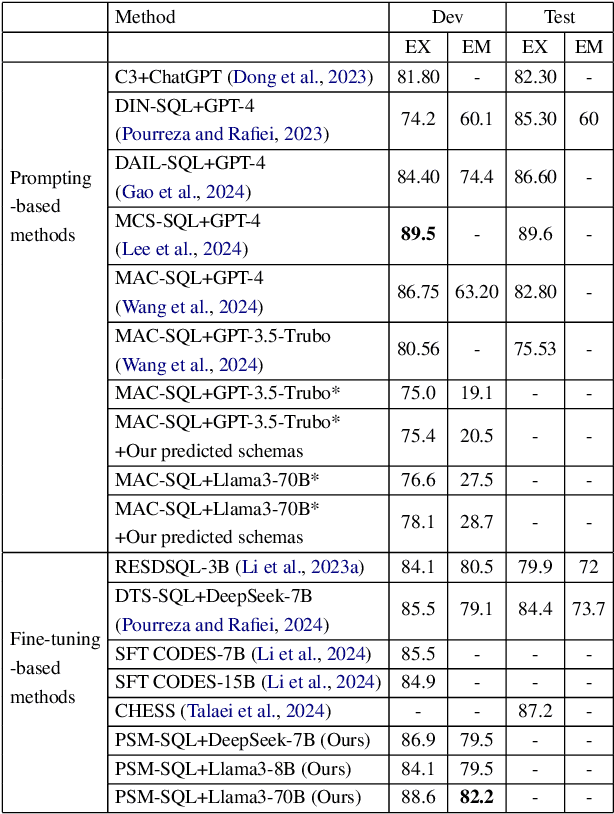
It is challenging to convert natural language (NL) questions into executable structured query language (SQL) queries for text-to-SQL tasks due to the vast number of database schemas with redundancy, which interferes with semantic learning, and the domain shift between NL and SQL. Existing works for schema linking focus on the table level and perform it once, ignoring the multi-granularity semantics and chainable cyclicity of schemas. In this paper, we propose a progressive schema linking with multi-granularity semantics (PSM-SQL) framework to reduce the redundant database schemas for text-to-SQL. Using the multi-granularity schema linking (MSL) module, PSM-SQL learns the schema semantics at the column, table, and database levels. More specifically, a triplet loss is used at the column level to learn embeddings, while fine-tuning LLMs is employed at the database level for schema reasoning. MSL employs classifier and similarity scores to model schema interactions for schema linking at the table level. In particular, PSM-SQL adopts a chain loop strategy to reduce the task difficulty of schema linking by continuously reducing the number of redundant schemas. Experiments conducted on text-to-SQL datasets show that the proposed PSM-SQL is 1-3 percentage points higher than the existing methods.
Cycle Encoding of a StyleGAN Encoder for Improved Reconstruction and Editability
Jul 19, 2022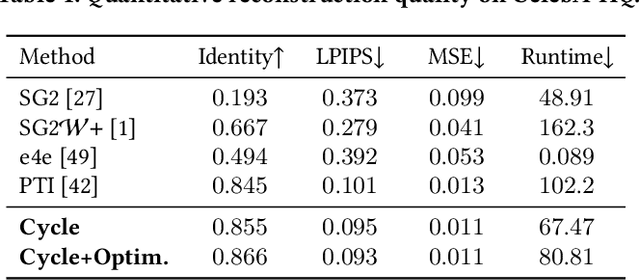
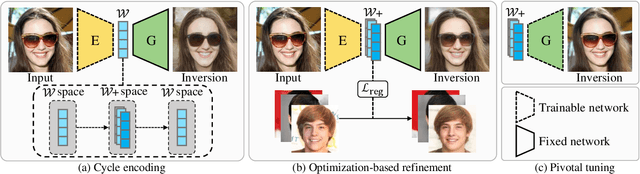
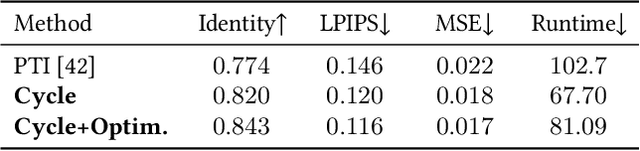
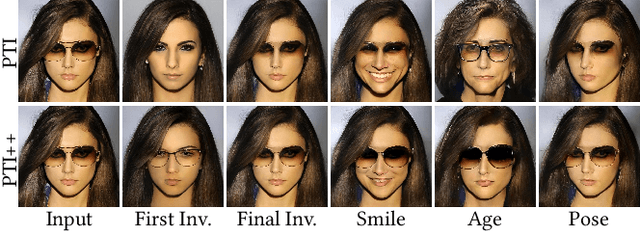
GAN inversion aims to invert an input image into the latent space of a pre-trained GAN. Despite the recent advances in GAN inversion, there remain challenges to mitigate the tradeoff between distortion and editability, i.e. reconstructing the input image accurately and editing the inverted image with a small visual quality drop. The recently proposed pivotal tuning model makes significant progress towards reconstruction and editability, by using a two-step approach that first inverts the input image into a latent code, called pivot code, and then alters the generator so that the input image can be accurately mapped into the pivot code. Here, we show that both reconstruction and editability can be improved by a proper design of the pivot code. We present a simple yet effective method, named cycle encoding, for a high-quality pivot code. The key idea of our method is to progressively train an encoder in varying spaces according to a cycle scheme: W->W+->W. This training methodology preserves the properties of both W and W+ spaces, i.e. high editability of W and low distortion of W+. To further decrease the distortion, we also propose to refine the pivot code with an optimization-based method, where a regularization term is introduced to reduce the degradation in editability. Qualitative and quantitative comparisons to several state-of-the-art methods demonstrate the superiority of our approach.
Virtual Mixup Training for Unsupervised Domain Adaptation
May 24, 2019
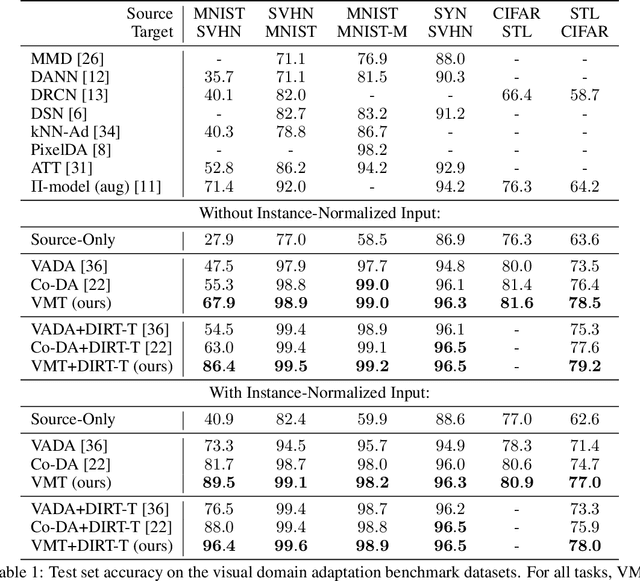
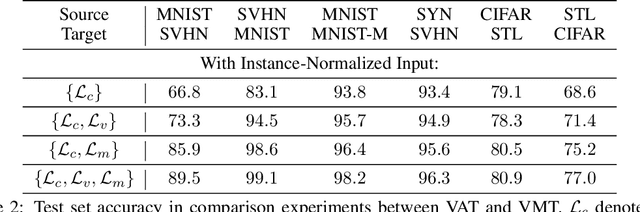

We study the problem of unsupervised domain adaptation which aims to adapt models trained on a labeled source domain to a completely unlabeled target domain. Domain adversarial training is a promising approach and has been a basis for many state-of-the-art models in unsupervised domain adaptation. The idea of domain adversarial training is to align the feature space between the source and target domains by adversarially training a domain classifier and a feature encoder. Recently, cluster assumption has been applied to unsupervised domain adaptation and achieved strong performance. In this paper, we propose a new regularization method called Virtual Mixup Training (VMT), which is able to further constrain the hypothesis of cluster assumption. The idea of VMT is to impose a locally-Lipschitz constraint on the model by smoothing the output distribution along the lines between pairs of training samples. Unlike the traditional mixup model, our method constructs the combination samples without using the label information, allowing it to be applicable to unsupervised domain adaptation. The proposed method is generic and can be combined with existing methods using domain adversarial training. We combine VMT with a recent state-of-the-art model called VADA, and extensive experiments demonstrate that VMT significantly improves the performance of VADA on several domain adaptation benchmark datasets. For the challenging task of adapting MNIST to SVHN, when not using instance normalization, VMT improves the accuracy of VADA by over 30%. When using instance normalization, our model achieves an accuracy of 96.4%, which is very close to the accuracy (96.5%) of the train-on-target model. Code will be made publicly available.
MMED: A Multi-domain and Multi-modality Event Dataset
Apr 09, 2019

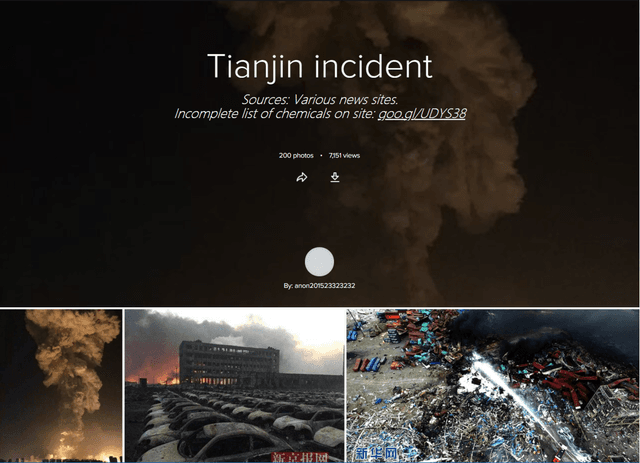
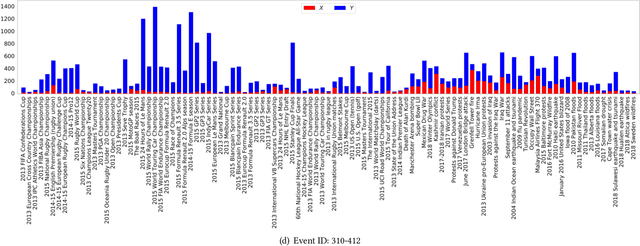
In this work, we construct and release a multi-domain and multi-modality event dataset (MMED), containing 25,165 textual news articles collected from hundreds of news media sites (e.g., Yahoo News, Google News, CNN News.) and 76,516 image posts shared on Flickr social media, which are annotated according to 412 real-world events. The dataset is collected to explore the problem of organizing heterogeneous data contributed by professionals and amateurs in different data domains, and the problem of transferring event knowledge obtained from one data domain to heterogeneous data domain, thus summarizing the data with different contributors. We hope that the release of the MMED dataset can stimulate innovate research on related challenging problems, such as event discovery, cross-modal (event) retrieval, and visual question answering, etc.
Learning Shared Semantic Space with Correlation Alignment for Cross-modal Event Retrieval
Jan 15, 2019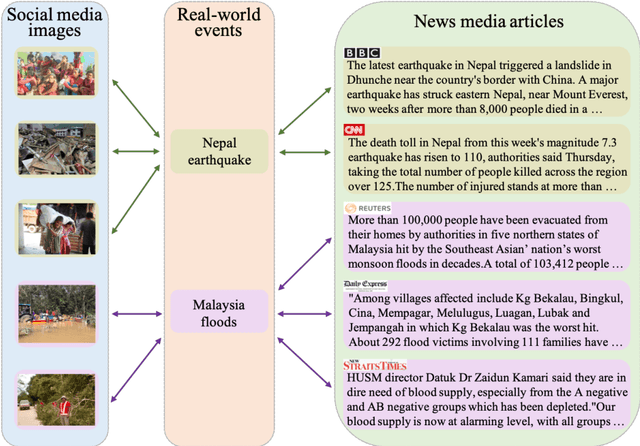

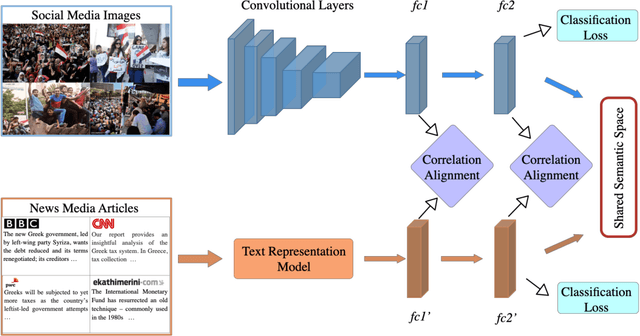
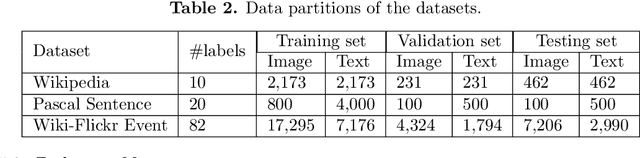
In this paper, we propose to learn shared semantic space with correlation alignment (${S}^{3}CA$) for multimodal data representations, which aligns nonlinear correlations of multimodal data distributions in deep neural networks designed for heterogeneous data. In the context of cross-modal (event) retrieval, we design a neural network with convolutional layers and fully-connected layers to extract features for images, including images on Flickr-like social media. Simultaneously, we exploit a fully-connected neural network to extract semantic features for texts, including news articles from news media. In particular, nonlinear correlations of layer activations in the two neural networks are aligned with correlation alignment during the joint training of the networks. Furthermore, we project the multimodal data into a shared semantic space for cross-modal (event) retrieval, where the distances between heterogeneous data samples can be measured directly. In addition, we contribute a Wiki-Flickr Event dataset, where the multimodal data samples are not describing each other in pairs like the existing paired datasets, but all of them are describing semantic events. Extensive experiments conducted on both paired and unpaired datasets manifest the effectiveness of ${S}^{3}CA$, outperforming the state-of-the-art methods.