 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Essence to Defense: Adaptive Semantic-aware Watermarking for Embedding-as-a-Service Copyright Protection
Dec 18, 2025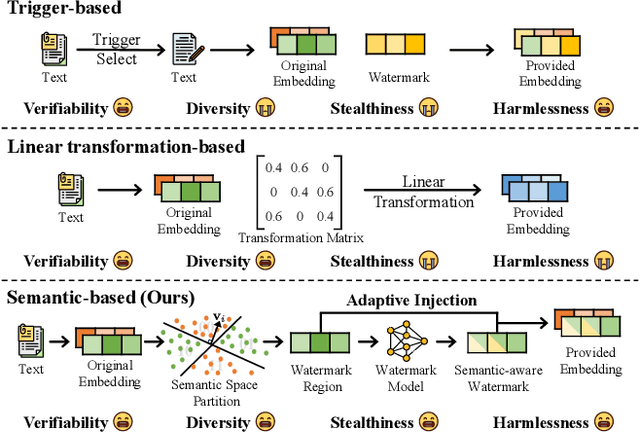



Benefiting from the superior capabilities of large language models in natural language understanding and generation, Embeddings-as-a-Service (EaaS) has emerged as a successful commercial paradigm on the web platform. However, prior studies have revealed that EaaS is vulnerable to imitation attacks. Existing methods protect the intellectual property of EaaS through watermarking techniques, but they all ignore the most important properties of embedding: semantics, resulting in limited harmlessness and stealthiness. To this end, we propose SemMark, a novel semantic-based watermarking paradigm for EaaS copyright protection. SemMark employs locality-sensitive hashing to partition the semantic space and inject semantic-aware watermarks into specific regions, ensuring that the watermark signals remain imperceptible and diverse. In addition, we introduce the adaptive watermark weight mechanism based on the local outlier factor to preserve the original embedding distribution. Furthermore, we propose Detect-Sampling and Dimensionality-Reduction attacks and construct four scenarios to evaluate the watermarking method. Extensive experiments are conducted on four popular NLP datasets, and SemMark achieves superior verifiability, diversity, stealthiness, and harmlessness.
Mining Word Boundaries from Speech-Text Parallel Data for Cross-domain Chinese Word Segmentation
Dec 12, 2024



Inspired by early research on exploring naturally annotated data for Chinese Word Segmentation (CWS), and also by recent research on integration of speech and text processing, this work for the first time proposes to explicitly mine word boundaries from speech-text parallel data. We employ the Montreal Forced Aligner (MFA) toolkit to perform character-level alignment on speech-text data, giving pauses as candidate word boundaries. Based on detailed analysis of collected pauses, we propose an effective probability-based strategy for filtering unreliable word boundaries. To more effectively utilize word boundaries as extra training data, we also propose a robust complete-then-train (CTT) strategy. We conduct cross-domain CWS experiments on two target domains, i.e., ZX and AISHELL2. We have annotated about 1,000 sentences as the evaluation data of AISHELL2. Experiments demonstrate the effectiveness of our proposed approach.
Leveraging Data Mining, Active Learning, and Domain Adaptation in a Multi-Stage, Machine Learning-Driven Approach for the Efficient Discovery of Advanced Acidic Oxygen Evolution Electrocatalysts
Jul 05, 2024



Developing advanced catalysts for acidic oxygen evolution reaction (OER) is crucial for sustainable hydrogen production. This study introduces a novel, multi-stage machine learning (ML) approach to streamline the discovery and optimization of complex multi-metallic catalysts. Our method integrates data mining, active learning, and domain adaptation throughout the materials discovery process. Unlike traditional trial-and-error methods, this approach systematically narrows the exploration space using domain knowledge with minimized reliance on subjective intuition. Then the active learning module efficiently refines element composition and synthesis conditions through iterative experimental feedback. The process culminated in the discovery of a promising Ru-Mn-Ca-Pr oxide catalyst. Our workflow also enhances theoretical simulations with domain adaptation strategy, providing deeper mechanistic insights aligned with experimental findings. By leveraging diverse data sources and multiple ML strategies, we establish an efficient pathway for electrocatalyst discovery and optimization. This comprehensive, data-driven approach represents a paradigm shift and potentially new benchmark in electrocatalysts research.
FlightPatchNet: Multi-Scale Patch Network with Differential Coding for Flight Trajectory Prediction
May 25, 2024
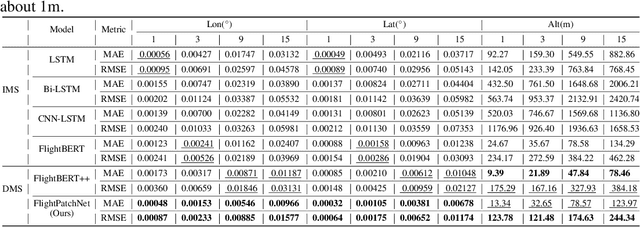
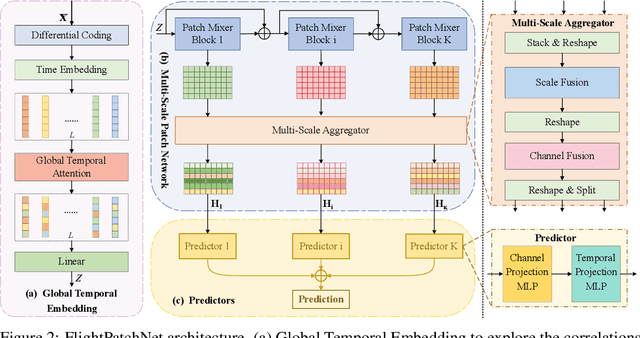
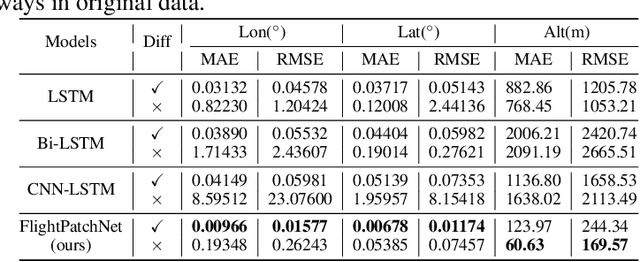
Accurate multi-step flight trajectory prediction plays an important role in Air Traffic Control, which can ensure the safety of air transportation. Two main issues limit the flight trajectory prediction performance of existing works. The first issue is the negative impact on prediction accuracy caused by the significant differences in data range. The second issue is that real-world flight trajectories involve underlying temporal dependencies, and existing methods fail to reveal the hidden complex temporal variations and only extract features from one single time scale. To address the above issues, we propose FlightPatchNet, a multi-scale patch network with differential coding for flight trajectory prediction. Specifically, FlightPatchNet first utilizes the differential coding to encode the original values of longitude and latitude into first-order differences and generates embeddings for all variables at each time step. Then, a global temporal attention is introduced to explore the dependencies between different time steps. To fully explore the diverse temporal patterns in flight trajectories, a multi-scale patch network is delicately designed to serve as the backbone. The multi-scale patch network exploits stacked patch mixer blocks to capture inter- and intra-patch dependencies under different time scales, and further integrates multi-scale temporal features across different scales and variables. Finally, FlightPatchNet ensembles multiple predictors to make direct multi-step prediction. Extensive experiments on ADS-B datasets demonstrate that our model outperforms the competitive baselines. Code is available at: https://github.com/FlightTrajectoryResearch/FlightPatchNet.
Adaptive Data Augmentation for Aspect Sentiment Quad Prediction
Jan 12, 2024Aspect sentiment quad prediction (ASQP) aims to predict the quad sentiment elements for a given sentence, which is a critical task in the field of aspect-based sentiment analysis. However, the data imbalance issue has not received sufficient attention in ASQP task. In this paper, we divide the issue into two-folds, quad-pattern imbalance and aspect-category imbalance, and propose an Adaptive Data Augmentation (ADA) framework to tackle the imbalance issue. Specifically, a data augmentation process with a condition function adaptively enhances the tail quad patterns and aspect categories, alleviating the data imbalance in ASQP. Following previous studies, we also further explore the generative framework for extracting complete quads by introducing the category prior knowledge and syntax-guided decoding target. Experimental results demonstrate that data augmentation for imbalance in ASQP task can improve the performance, and the proposed ADA method is superior to naive data oversampling.
How Well Do Large Language Models Understand Syntax? An Evaluation by Asking Natural Language Questions
Nov 14, 2023
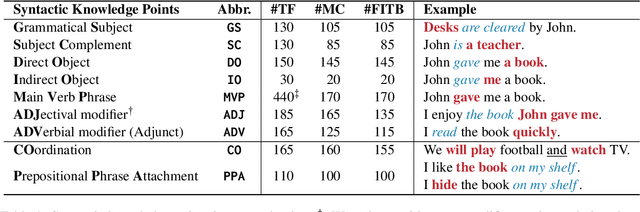


While recent advancements in large language models (LLMs) bring us closer to achieving artificial general intelligence, the question persists: Do LLMs truly understand language, or do they merely mimic comprehension through pattern recognition? This study seeks to explore this question through the lens of syntax, a crucial component of sentence comprehension. Adopting a natural language question-answering (Q&A) scheme, we craft questions targeting nine syntactic knowledge points that are most closely related to sentence comprehension. Experiments conducted on 24 LLMs suggest that most have a limited grasp of syntactic knowledge, exhibiting notable discrepancies across different syntactic knowledge points. In particular, questions involving prepositional phrase attachment pose the greatest challenge, whereas those concerning adjectival modifier and indirect object are relatively easier for LLMs to handle. Furthermore, a case study on the training dynamics of the LLMs reveals that the majority of syntactic knowledge is learned during the initial stages of training, hinting that simply increasing the number of training tokens may not be the `silver bullet' for improving the comprehension ability of LLMs.
Prompt2Gaussia: Uncertain Prompt-learning for Script Event Prediction
Aug 04, 2023



Script Event Prediction (SEP) aims to predict the subsequent event for a given event chain from a candidate list. Prior research has achieved great success by integrating external knowledge to enhance the semantics, but it is laborious to acquisite the appropriate knowledge resources and retrieve the script-related knowledge. In this paper, we regard public pre-trained language models as knowledge bases and automatically mine the script-related knowledge via prompt-learning. Still, the scenario-diversity and label-ambiguity in scripts make it uncertain to construct the most functional prompt and label token in prompt learning, i.e., prompt-uncertainty and verbalizer-uncertainty. Considering the innate ability of Gaussian distribution to express uncertainty, we deploy the prompt tokens and label tokens as random variables following Gaussian distributions, where a prompt estimator and a verbalizer estimator are proposed to estimate their probabilistic representations instead of deterministic representations. We take the lead to explore prompt-learning in SEP and provide a fresh perspective to enrich the script semantics. Our method is evaluated on the most widely used benchmark and a newly proposed large-scale one. Experiments show that our method, which benefits from knowledge evoked from pre-trained language models, outperforms prior baselines by 1.46\% and 1.05\% on two benchmarks, respectively.
Event Detection with Relation-Aware Graph Convolutional Neural Networks
Feb 25, 2020
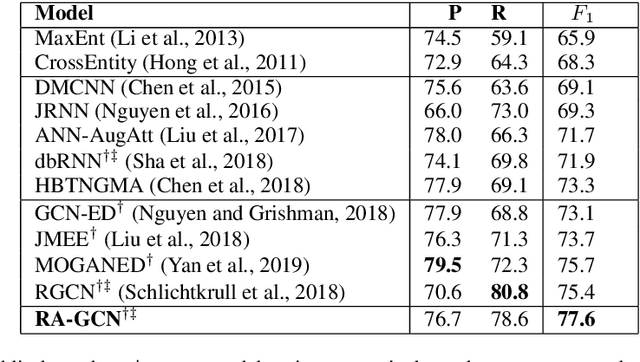
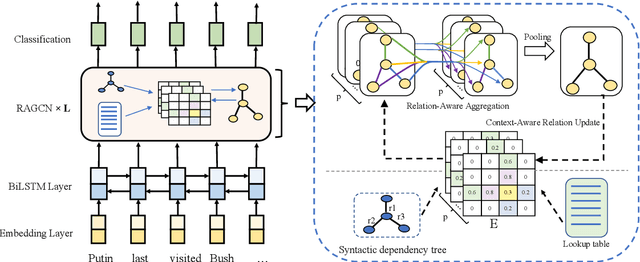
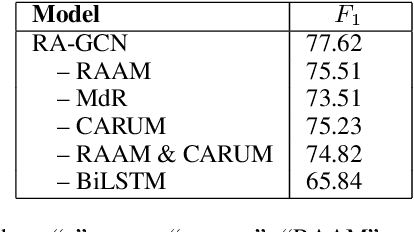
Event detection (ED), a key subtask of information extraction, aims to recognize instances of specific types of events in text. Recently, graph convolutional networks (GCNs) over dependency trees have been widely used to capture syntactic structure information and get convincing performances in event detection. However, these works ignore the syntactic relation labels on the tree, which convey rich and useful linguistic knowledge for event detection. In this paper, we investigate a novel architecture named Relation-Aware GCN (RA-GCN), which efficiently exploits syntactic relation labels and models the relation between words specifically. We first propose a relation-aware aggregation module to produce expressive word representation by aggregating syntactically connected words through specific relation. Furthermore, a context-aware relation update module is designed to explicitly update the relation representation between words, and these two modules work in the mutual promotion way. Experimental results on the ACE2005 dataset show that our model achieves a new state-of-the-art performance for event detection.