 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Well Do Large Language Models Understand Syntax? An Evaluation by Asking Natural Language Questions
Paper and Code

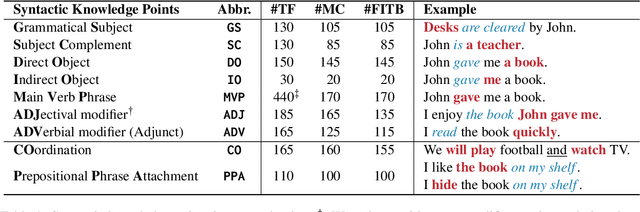


While recent advancements in large language models (LLMs) bring us closer to achieving artificial general intelligence, the question persists: Do LLMs truly understand language, or do they merely mimic comprehension through pattern recognition? This study seeks to explore this question through the lens of syntax, a crucial component of sentence comprehension. Adopting a natural language question-answering (Q&A) scheme, we craft questions targeting nine syntactic knowledge points that are most closely related to sentence comprehension. Experiments conducted on 24 LLMs suggest that most have a limited grasp of syntactic knowledge, exhibiting notable discrepancies across different syntactic knowledge points. In particular, questions involving prepositional phrase attachment pose the greatest challenge, whereas those concerning adjectival modifier and indirect object are relatively easier for LLMs to handle. Furthermore, a case study on the training dynamics of the LLMs reveals that the majority of syntactic knowledge is learned during the initial stages of training, hinting that simply increasing the number of training tokens may not be the `silver bullet' for improving the comprehension ability of LLMs.