 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Self-Supervised Contrastive Learning for Facial Expression Recognition
Paper and Code
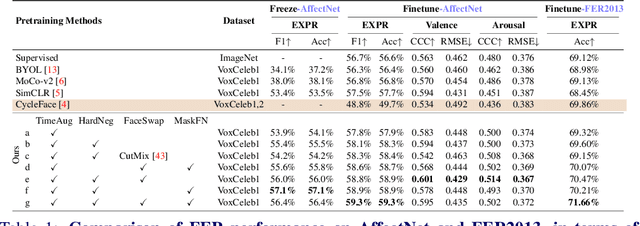


The success of most advanced facial expression recognition works relies heavily on large-scale annotated datasets. However, it poses great challenges in acquiring clean and consistent annotations for facial expression datasets. On the other hand, self-supervised contrastive learning has gained great popularity due to its simple yet effective instance discrimination training strategy, which can potentially circumvent the annotation issue. Nevertheless, there remain inherent disadvantages of instance-level discrimination, which are even more challenging when faced with complicated facial representations. In this paper, we revisit the use of self-supervised contrastive learning and explore three core strategies to enforce expression-specific representations and to minimize the interference from other facial attributes, such as identity and face styling. Experimental results show that our proposed method outperforms the current state-of-the-art self-supervised learning methods, in terms of both categorical and dimensional facial expression recognition tasks.