 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use
Jan 31, 2026As Large Language Models (LLMs) are increasingly applied in high-stakes domains, their ability to reason strategically under uncertainty becomes critical. Poker provides a rigorous testbed, requiring not only strong actions but also principled, game-theoretic reasoning. In this paper, we conduct a systematic study of LLMs in multiple realistic poker tasks, evaluating both gameplay outcomes and reasoning traces. Our analysis reveals LLMs fail to compete against traditional algorithms and identifies three recurring flaws: reliance on heuristics, factual misunderstandings, and a "knowing-doing" gap where actions diverge from reasoning. An initial attempt with behavior cloning and step-level reinforcement learning improves reasoning style but remains insufficient for accurate game-theoretic play. Motivated by these limitations, we propose ToolPoker, a tool-integrated reasoning framework that combines external solvers for GTO-consistent actions with more precise professional-style explanations. Experiments demonstrate that ToolPoker achieves state-of-the-art gameplay while producing reasoning traces that closely reflect game-theoretic principles.
Bradley-Terry and Multi-Objective Reward Modeling Are Complementary
Jul 10, 2025Reward models trained on human preference data have demonstrated strong effectiveness in aligning Large Language Models (LLMs) with human intent under the framework of Reinforcement Learning from Human Feedback (RLHF). However, RLHF remains vulnerable to reward hacking, where the policy exploits imperfections in the reward function rather than genuinely learning the intended behavior. Although significant efforts have been made to mitigate reward hacking, they predominantly focus on and evaluate in-distribution scenarios, where the training and testing data for the reward model share the same distribution. In this paper, we empirically show that state-of-the-art methods struggle in more challenging out-of-distribution (OOD) settings. We further demonstrate that incorporating fine-grained multi-attribute scores helps address this challenge. However, the limited availability of high-quality data often leads to weak performance of multi-objective reward functions, which can negatively impact overall performance and become the bottleneck. To address this issue, we propose a unified reward modeling framework that jointly trains Bradley--Terry (BT) single-objective and multi-objective regression-based reward functions using a shared embedding space. We theoretically establish a connection between the BT loss and the regression objective and highlight their complementary benefits. Specifically, the regression task enhances the single-objective reward function's ability to mitigate reward hacking in challenging OOD settings, while BT-based training improves the scoring capability of the multi-objective reward function, enabling a 7B model to outperform a 70B baseline. Extensive experimental results demonstrate that our framework significantly improves both the robustness and the scoring performance of reward models.
Image Corruption-Inspired Membership Inference Attacks against Large Vision-Language Models
Jun 14, 2025Large vision-language models (LVLMs) have demonstrated outstanding performance in many downstream tasks. However, LVLMs are trained on large-scale datasets, which can pose privacy risks if training images contain sensitive information. Therefore, it is important to detect whether an image is used to train the LVLM. Recent studies have investigated membership inference attacks (MIAs) against LVLMs, including detecting image-text pairs and single-modality content. In this work, we focus on detecting whether a target image is used to train the target LVLM. We design simple yet effective Image Corruption-Inspired Membership Inference Attacks (ICIMIA) against LLVLMs, which are inspired by LVLM's different sensitivity to image corruption for member and non-member images. We first perform an MIA method under the white-box setting, where we can obtain the embeddings of the image through the vision part of the target LVLM. The attacks are based on the embedding similarity between the image and its corrupted version. We further explore a more practical scenario where we have no knowledge about target LVLMs and we can only query the target LVLMs with an image and a question. We then conduct the attack by utilizing the output text embeddings' similarity. Experiments on existing datasets validate the effectiveness of our proposed attack methods under those two different settings.
BioMol-MQA: A Multi-Modal Question Answering Dataset For LLM Reasoning Over Bio-Molecular Interactions
Jun 06, 2025



Retrieval augmented generation (RAG) has shown great power in improving Large Language Models (LLMs). However, most existing RAG-based LLMs are dedicated to retrieving single modality information, mainly text; while for many real-world problems, such as healthcare, information relevant to queries can manifest in various modalities such as knowledge graph, text (clinical notes), and complex molecular structure. Thus, being able to retrieve relevant multi-modality domain-specific information, and reason and synthesize diverse knowledge to generate an accurate response is important. To address the gap, we present BioMol-MQA, a new question-answering (QA) dataset on polypharmacy, which is composed of two parts (i) a multimodal knowledge graph (KG) with text and molecular structure for information retrieval; and (ii) challenging questions that designed to test LLM capabilities in retrieving and reasoning over multimodal KG to answer questions. Our benchmarks indicate that existing LLMs struggle to answer these questions and do well only when given the necessary background data, signaling the necessity for strong RAG frameworks.
Diagnosing and Addressing Pitfalls in KG-RAG Datasets: Toward More Reliable Benchmarking
May 29, 2025
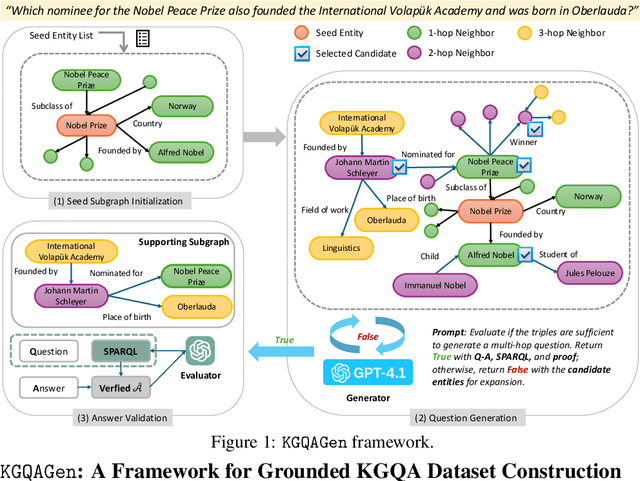

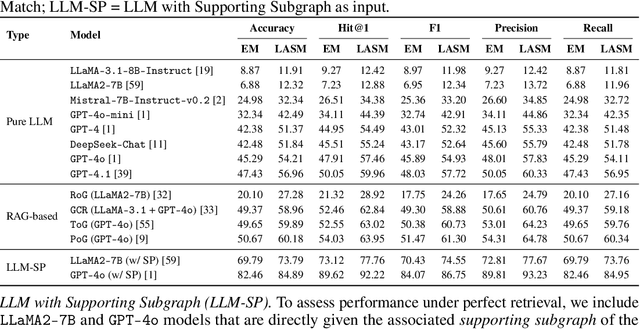
Knowledge Graph Question Answering (KGQA) systems rely on high-quality benchmarks to evaluate complex multi-hop reasoning. However, despite their widespread use, popular datasets such as WebQSP and CWQ suffer from critical quality issues, including inaccurate or incomplete ground-truth annotations, poorly constructed questions that are ambiguous, trivial, or unanswerable, and outdated or inconsistent knowledge. Through a manual audit of 16 popular KGQA datasets, including WebQSP and CWQ, we find that the average factual correctness rate is only 57 %. To address these issues, we introduce KGQAGen, an LLM-in-the-loop framework that systematically resolves these pitfalls. KGQAGen combines structured knowledge grounding, LLM-guided generation, and symbolic verification to produce challenging and verifiable QA instances. Using KGQAGen, we construct KGQAGen-10k, a ten-thousand scale benchmark grounded in Wikidata, and evaluate a diverse set of KG-RAG models. Experimental results demonstrate that even state-of-the-art systems struggle on this benchmark, highlighting its ability to expose limitations of existing models. Our findings advocate for more rigorous benchmark construction and position KGQAGen as a scalable framework for advancing KGQA evaluation.
SFT or RL? An Early Investigation into Training R1-Like Reasoning Large Vision-Language Models
Apr 10, 2025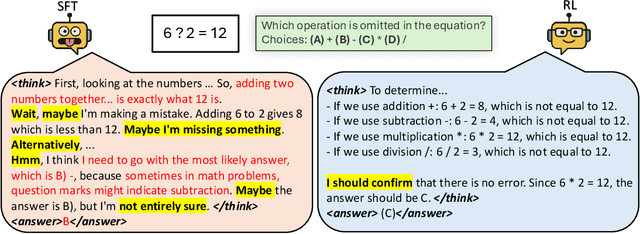
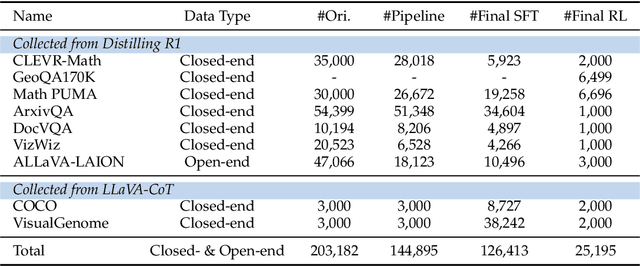
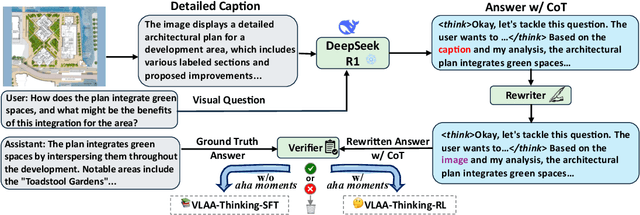
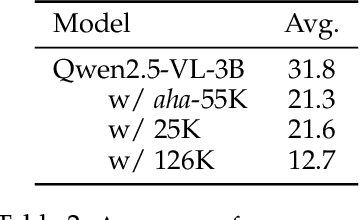
This work revisits the dominant supervised fine-tuning (SFT) then reinforcement learning (RL) paradigm for training Large Vision-Language Models (LVLMs), and reveals a key finding: SFT can significantly undermine subsequent RL by inducing ``pseudo reasoning paths'' imitated from expert models. While these paths may resemble the native reasoning paths of RL models, they often involve prolonged, hesitant, less informative steps, and incorrect reasoning. To systematically study this effect, we introduce VLAA-Thinking, a new multimodal dataset designed to support reasoning in LVLMs. Constructed via a six-step pipeline involving captioning, reasoning distillation, answer rewrite and verification, VLAA-Thinking comprises high-quality, step-by-step visual reasoning traces for SFT, along with a more challenging RL split from the same data source. Using this dataset, we conduct extensive experiments comparing SFT, RL and their combinations. Results show that while SFT helps models learn reasoning formats, it often locks aligned models into imitative, rigid reasoning modes that impede further learning. In contrast, building on the Group Relative Policy Optimization (GRPO) with a novel mixed reward module integrating both perception and cognition signals, our RL approach fosters more genuine, adaptive reasoning behavior. Notably, our model VLAA-Thinker, based on Qwen2.5VL 3B, achieves top-1 performance on Open LMM Reasoning Leaderboard (https://huggingface.co/spaces/opencompass/Open_LMM_Reasoning_Leaderboard) among 4B scale LVLMs, surpassing the previous state-of-the-art by 1.8%. We hope our findings provide valuable insights in developing reasoning-capable LVLMs and can inform future research in this area.
A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness
Nov 04, 2024Large language models (LLM) have demonstrated emergent abilities in text generation, question answering, and reasoning, facilitating various tasks and domains. Despite their proficiency in various tasks, LLMs like LaPM 540B and Llama-3.1 405B face limitations due to large parameter sizes and computational demands, often requiring cloud API use which raises privacy concerns, limits real-time applications on edge devices, and increases fine-tuning costs. Additionally, LLMs often underperform in specialized domains such as healthcare and law due to insufficient domain-specific knowledge, necessitating specialized models. Therefore, Small Language Models (SLMs) are increasingly favored for their low inference latency, cost-effectiveness, efficient development, and easy customization and adaptability. These models are particularly well-suited for resource-limited environments and domain knowledge acquisition, addressing LLMs' challenges and proving ideal for applications that require localized data handling for privacy, minimal inference latency for efficiency, and domain knowledge acquisition through lightweight fine-tuning. The rising demand for SLMs has spurred extensive research and development. However, a comprehensive survey investigating issues related to the definition, acquisition, application, enhancement, and reliability of SLM remains lacking, prompting us to conduct a detailed survey on these topics. The definition of SLMs varies widely, thus to standardize, we propose defining SLMs by their capability to perform specialized tasks and suitability for resource-constrained settings, setting boundaries based on the minimal size for emergent abilities and the maximum size sustainable under resource constraints. For other aspects, we provide a taxonomy of relevant models/methods and develop general frameworks for each category to enhance and utilize SLMs effectively.
Does your LLM truly unlearn? An embarrassingly simple approach to recover unlearned knowledge
Oct 21, 2024



Large language models (LLMs) have shown remarkable proficiency in generating text, benefiting from extensive training on vast textual corpora. However, LLMs may also acquire unwanted behaviors from the diverse and sensitive nature of their training data, which can include copyrighted and private content. Machine unlearning has been introduced as a viable solution to remove the influence of such problematic content without the need for costly and time-consuming retraining. This process aims to erase specific knowledge from LLMs while preserving as much model utility as possible. Despite the effectiveness of current unlearning methods, little attention has been given to whether existing unlearning methods for LLMs truly achieve forgetting or merely hide the knowledge, which current unlearning benchmarks fail to detect. This paper reveals that applying quantization to models that have undergone unlearning can restore the "forgotten" information. To thoroughly evaluate this phenomenon, we conduct comprehensive experiments using various quantization techniques across multiple precision levels. We find that for unlearning methods with utility constraints, the unlearned model retains an average of 21\% of the intended forgotten knowledge in full precision, which significantly increases to 83\% after 4-bit quantization. Based on our empirical findings, we provide a theoretical explanation for the observed phenomenon and propose a quantization-robust unlearning strategy to mitigate this intricate issue...
Enhance Graph Alignment for Large Language Models
Oct 15, 2024



Graph-structured data is prevalent in the real world. Recently, due to the powerful emergent capabilities, Large Language Models (LLMs) have shown promising performance in modeling graphs. The key to effectively applying LLMs on graphs is converting graph data into a format LLMs can comprehend. Graph-to-token approaches are popular in enabling LLMs to process graph information. They transform graphs into sequences of tokens and align them with text tokens through instruction tuning, where self-supervised instruction tuning helps LLMs acquire general knowledge about graphs, and supervised fine-tuning specializes LLMs for the downstream tasks on graphs. Despite their initial success, we find that existing methods have a misalignment between self-supervised tasks and supervised downstream tasks, resulting in negative transfer from self-supervised fine-tuning to downstream tasks. To address these issues, we propose Graph Alignment Large Language Models (GALLM) to benefit from aligned task templates. In the self-supervised tuning stage, we introduce a novel text matching task using templates aligned with downstream tasks. In the task-specific tuning stage, we propose two category prompt methods that learn supervision information from additional explanation with further aligned templates. Experimental evaluations on four datasets demonstrate substantial improvements in supervised learning, multi-dataset generalizability, and particularly in zero-shot capability, highlighting the model's potential as a graph foundation model.
HC-GST: Heterophily-aware Distribution Consistency based Graph Self-training
Jul 25, 2024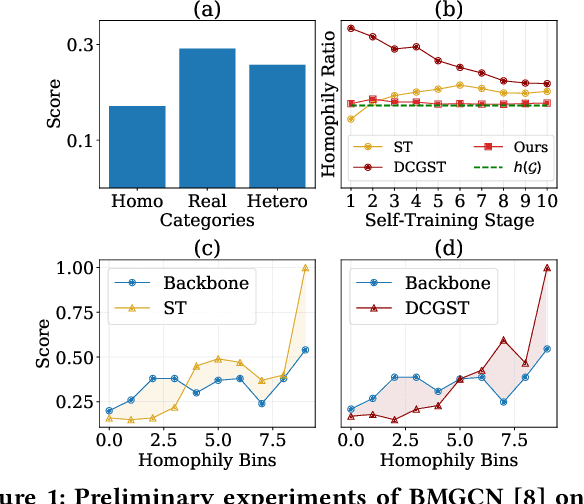
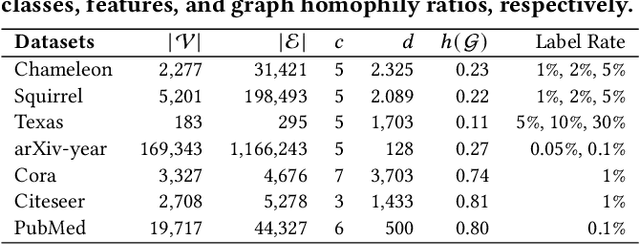
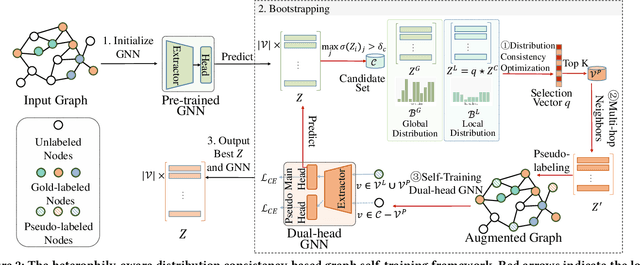
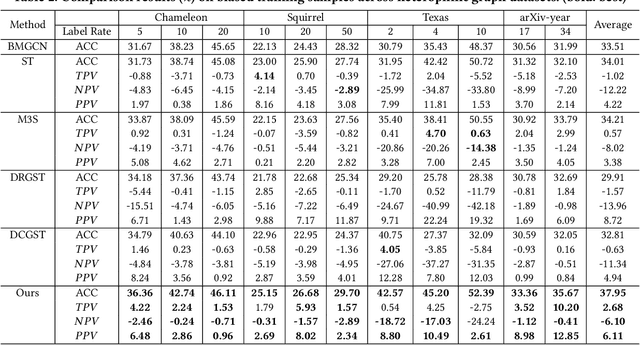
Graph self-training (GST), which selects and assigns pseudo-labels to unlabeled nodes, is popular for tackling label sparsity in graphs. However, recent study on homophily graphs show that GST methods could introduce and amplify distribution shift between training and test nodes as they tend to assign pseudo-labels to nodes they are good at. As GNNs typically perform better on homophilic nodes, there could be potential shifts towards homophilic pseudo-nodes, which is underexplored. Our preliminary experiments on heterophilic graphs verify that these methods can cause shifts in homophily ratio distributions, leading to \textit{training bias} that improves performance on homophilic nodes while degrading it on heterophilic ones. Therefore, we study a novel problem of reducing homophily ratio distribution shifts during self-training on heterophilic graphs. A key challenge is the accurate calculation of homophily ratios and their distributions without extensive labeled data. To tackle them, we propose a novel Heterophily-aware Distribution Consistency-based Graph Self-Training (HC-GST) framework, which estimates homophily ratios using soft labels and optimizes a selection vector to align pseudo-nodes with the global homophily ratio distribution. Extensive experiments on both homophilic and heterophilic graphs show that HC-GST effectively reduces training bias and enhances self-training performance.