 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning While Asking: Transforming Reasoning Large Language Models from Passive Solvers to Proactive Inquirers
Jan 29, 2026Reasoning-oriented Large Language Models (LLMs) have achieved remarkable progress with Chain-of-Thought (CoT) prompting, yet they remain fundamentally limited by a \emph{blind self-thinking} paradigm: performing extensive internal reasoning even when critical information is missing or ambiguous. We propose Proactive Interactive Reasoning (PIR), a new reasoning paradigm that transforms LLMs from passive solvers into proactive inquirers that interleave reasoning with clarification. Unlike existing search- or tool-based frameworks that primarily address knowledge uncertainty by querying external environments, PIR targets premise- and intent-level uncertainty through direct interaction with the user. PIR is implemented via two core components: (1) an uncertainty-aware supervised fine-tuning procedure that equips models with interactive reasoning capability, and (2) a user-simulator-based policy optimization framework driven by a composite reward that aligns model behavior with user intent. Extensive experiments on mathematical reasoning, code generation, and document editing demonstrate that PIR consistently outperforms strong baselines, achieving up to 32.70\% higher accuracy, 22.90\% higher pass rate, and 41.36 BLEU improvement, while reducing nearly half of the reasoning computation and unnecessary interaction turns. Further reliability evaluations on factual knowledge, question answering, and missing-premise scenarios confirm the strong generalization and robustness of PIR. Model and code are publicly available at: \href{https://github.com/SUAT-AIRI/Proactive-Interactive-R1}
SpatialThinker: Reinforcing 3D Reasoning in Multimodal LLMs via Spatial Rewards
Nov 10, 2025Multimodal large language models (MLLMs) have achieved remarkable progress in vision-language tasks, but they continue to struggle with spatial understanding. Existing spatial MLLMs often rely on explicit 3D inputs or architecture-specific modifications, and remain constrained by large-scale datasets or sparse supervision. To address these limitations, we introduce SpatialThinker, a 3D-aware MLLM trained with RL to integrate structured spatial grounding with multi-step reasoning. The model simulates human-like spatial perception by constructing a scene graph of task-relevant objects and spatial relations, and reasoning towards an answer via dense spatial rewards. SpatialThinker consists of two key contributions: (1) a data synthesis pipeline that generates STVQA-7K, a high-quality spatial VQA dataset, and (2) online RL with a multi-objective dense spatial reward enforcing spatial grounding. SpatialThinker-7B outperforms supervised fine-tuning and the sparse RL baseline on spatial understanding and real-world VQA benchmarks, nearly doubling the base-model gain compared to sparse RL, and surpassing GPT-4o. These results showcase the effectiveness of combining spatial supervision with reward-aligned reasoning in enabling robust 3D spatial understanding with limited data and advancing MLLMs towards human-level visual reasoning.
SFT or RL? An Early Investigation into Training R1-Like Reasoning Large Vision-Language Models
Apr 10, 2025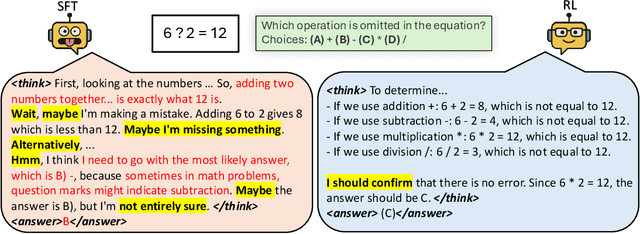
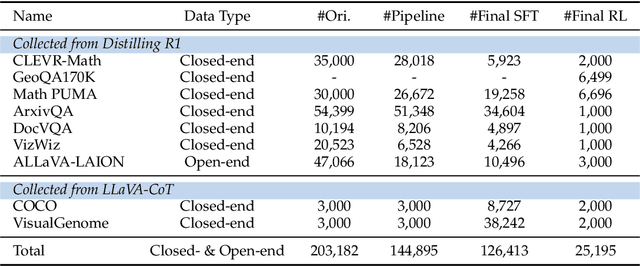
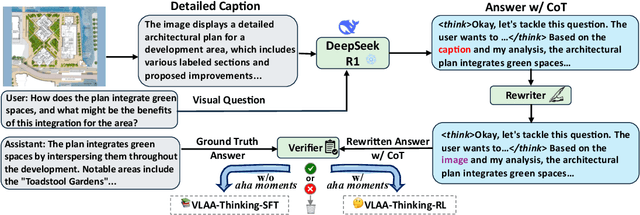
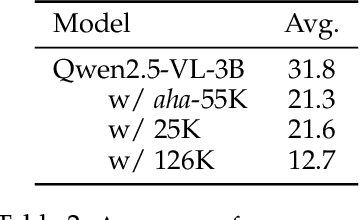
This work revisits the dominant supervised fine-tuning (SFT) then reinforcement learning (RL) paradigm for training Large Vision-Language Models (LVLMs), and reveals a key finding: SFT can significantly undermine subsequent RL by inducing ``pseudo reasoning paths'' imitated from expert models. While these paths may resemble the native reasoning paths of RL models, they often involve prolonged, hesitant, less informative steps, and incorrect reasoning. To systematically study this effect, we introduce VLAA-Thinking, a new multimodal dataset designed to support reasoning in LVLMs. Constructed via a six-step pipeline involving captioning, reasoning distillation, answer rewrite and verification, VLAA-Thinking comprises high-quality, step-by-step visual reasoning traces for SFT, along with a more challenging RL split from the same data source. Using this dataset, we conduct extensive experiments comparing SFT, RL and their combinations. Results show that while SFT helps models learn reasoning formats, it often locks aligned models into imitative, rigid reasoning modes that impede further learning. In contrast, building on the Group Relative Policy Optimization (GRPO) with a novel mixed reward module integrating both perception and cognition signals, our RL approach fosters more genuine, adaptive reasoning behavior. Notably, our model VLAA-Thinker, based on Qwen2.5VL 3B, achieves top-1 performance on Open LMM Reasoning Leaderboard (https://huggingface.co/spaces/opencompass/Open_LMM_Reasoning_Leaderboard) among 4B scale LVLMs, surpassing the previous state-of-the-art by 1.8%. We hope our findings provide valuable insights in developing reasoning-capable LVLMs and can inform future research in this area.
ViLBench: A Suite for Vision-Language Process Reward Modeling
Mar 26, 2025Process-supervised reward models serve as a fine-grained function that provides detailed step-wise feedback to model responses, facilitating effective selection of reasoning trajectories for complex tasks. Despite its advantages, evaluation on PRMs remains less explored, especially in the multimodal domain. To address this gap, this paper first benchmarks current vision large language models (VLLMs) as two types of reward models: output reward models (ORMs) and process reward models (PRMs) on multiple vision-language benchmarks, which reveal that neither ORM nor PRM consistently outperforms across all tasks, and superior VLLMs do not necessarily yield better rewarding performance. To further advance evaluation, we introduce ViLBench, a vision-language benchmark designed to require intensive process reward signals. Notably, OpenAI's GPT-4o with Chain-of-Thought (CoT) achieves only 27.3% accuracy, indicating the benchmark's challenge for current VLLMs. Lastly, we preliminarily showcase a promising pathway towards bridging the gap between general VLLMs and reward models -- by collecting 73.6K vision-language process reward data using an enhanced tree-search algorithm, our 3B model is able to achieve an average improvement of 3.3% over standard CoT and up to 2.5% compared to its untrained counterpart on ViLBench by selecting OpenAI o1's generations. We release the implementations at https://ucsc-vlaa.github.io/ViLBench with our code, model, and data.