 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Devil is in the Details: A Deep Dive into the Rabbit Hole of Data Filtering
Sep 27, 2023

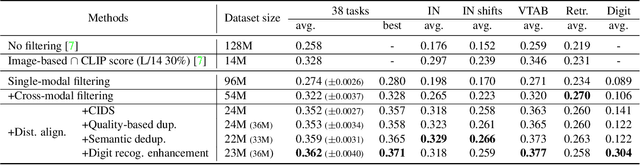

The quality of pre-training data plays a critical role in the performance of foundation models. Popular foundation models often design their own recipe for data filtering, which makes it hard to analyze and compare different data filtering approaches. DataComp is a new benchmark dedicated to evaluating different methods for data filtering. This paper describes our learning and solution when participating in the DataComp challenge. Our filtering strategy includes three stages: single-modality filtering, cross-modality filtering, and data distribution alignment. We integrate existing methods and propose new solutions, such as computing CLIP score on horizontally flipped images to mitigate the interference of scene text, using vision and language models to retrieve training samples for target downstream tasks, rebalancing the data distribution to improve the efficiency of allocating the computational budget, etc. We slice and dice our design choices, provide in-depth analysis, and discuss open questions. Our approach outperforms the best method from the DataComp paper by over 4% on the average performance of 38 tasks and by over 2% on ImageNet.
Learning Dynamic Query Combinations for Transformer-based Object Detection and Segmentation
Jul 27, 2023



Transformer-based detection and segmentation methods use a list of learned detection queries to retrieve information from the transformer network and learn to predict the location and category of one specific object from each query. We empirically find that random convex combinations of the learned queries are still good for the corresponding models. We then propose to learn a convex combination with dynamic coefficients based on the high-level semantics of the image. The generated dynamic queries, named modulated queries, better capture the prior of object locations and categories in the different images. Equipped with our modulated queries, a wide range of DETR-based models achieve consistent and superior performance across multiple tasks including object detection, instance segmentation, panoptic segmentation, and video instance segmentation.
Why Is Prompt Tuning for Vision-Language Models Robust to Noisy Labels?
Jul 22, 2023



Vision-language models such as CLIP learn a generic text-image embedding from large-scale training data. A vision-language model can be adapted to a new classification task through few-shot prompt tuning. We find that such a prompt tuning process is highly robust to label noises. This intrigues us to study the key reasons contributing to the robustness of the prompt tuning paradigm. We conducted extensive experiments to explore this property and find the key factors are: 1) the fixed classname tokens provide a strong regularization to the optimization of the model, reducing gradients induced by the noisy samples; 2) the powerful pre-trained image-text embedding that is learned from diverse and generic web data provides strong prior knowledge for image classification. Further, we demonstrate that noisy zero-shot predictions from CLIP can be used to tune its own prompt, significantly enhancing prediction accuracy in the unsupervised setting. The code is available at https://github.com/CEWu/PTNL.
Exploring the Role of Audio in Video Captioning
Jun 21, 2023Recent focus in video captioning has been on designing architectures that can consume both video and text modalities, and using large-scale video datasets with text transcripts for pre-training, such as HowTo100M. Though these approaches have achieved significant improvement, the audio modality is often ignored in video captioning. In this work, we present an audio-visual framework, which aims to fully exploit the potential of the audio modality for captioning. Instead of relying on text transcripts extracted via automatic speech recognition (ASR), we argue that learning with raw audio signals can be more beneficial, as audio has additional information including acoustic events, speaker identity, etc. Our contributions are twofold. First, we observed that the model overspecializes to the audio modality when pre-training with both video and audio modality, since the ground truth (i.e., text transcripts) can be solely predicted using audio. We proposed a Modality Balanced Pre-training (MBP) loss to mitigate this issue and significantly improve the performance on downstream tasks. Second, we slice and dice different design choices of the cross-modal module, which may become an information bottleneck and generate inferior results. We proposed new local-global fusion mechanisms to improve information exchange across audio and video. We demonstrate significant improvements by leveraging the audio modality on four datasets, and even outperform the state of the art on some metrics without relying on the text modality as the input.
Boosted Dynamic Neural Networks
Nov 30, 2022



Early-exiting dynamic neural networks (EDNN), as one type of dynamic neural networks, has been widely studied recently. A typical EDNN has multiple prediction heads at different layers of the network backbone. During inference, the model will exit at either the last prediction head or an intermediate prediction head where the prediction confidence is higher than a predefined threshold. To optimize the model, these prediction heads together with the network backbone are trained on every batch of training data. This brings a train-test mismatch problem that all the prediction heads are optimized on all types of data in training phase while the deeper heads will only see difficult inputs in testing phase. Treating training and testing inputs differently at the two phases will cause the mismatch between training and testing data distributions. To mitigate this problem, we formulate an EDNN as an additive model inspired by gradient boosting, and propose multiple training techniques to optimize the model effectively. We name our method BoostNet. Our experiments show it achieves the state-of-the-art performance on CIFAR100 and ImageNet datasets in both anytime and budgeted-batch prediction modes. Our code is released at https://github.com/SHI-Labs/Boosted-Dynamic-Networks.
Dropout Prediction Variation Estimation Using Neuron Activation Strength
Oct 25, 2021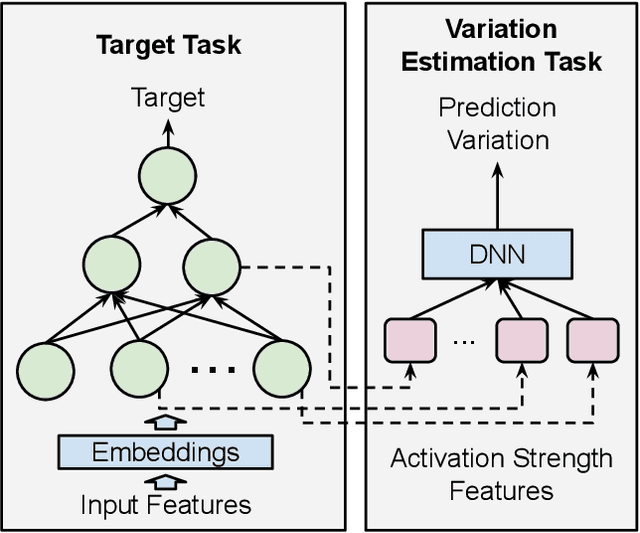
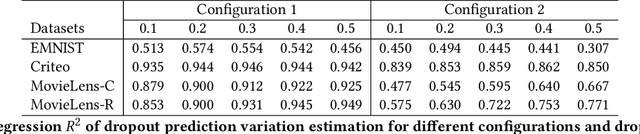
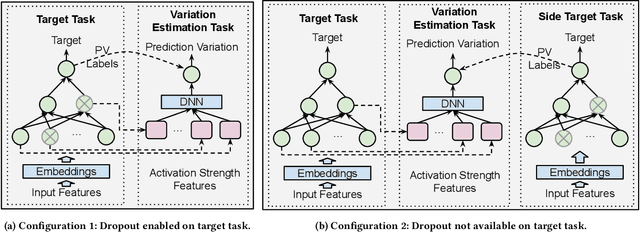
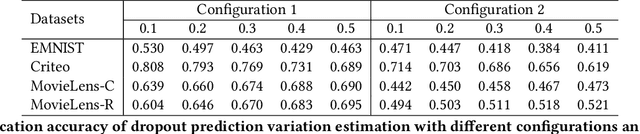
It is well-known that deep neural networks generate different predictions even given the same model configuration and training dataset. It thus becomes more and more important to study prediction variation, the variation of the predictions on a given input example, in neural network models. Dropout has been commonly used in various applications to quantify prediction variations. However, using dropout in practice can be expensive as it requires running dropout inferences many times to estimate prediction variation. We study how to estimate dropout prediction variation in a resource-efficient manner. We demonstrate that we can use neuron activation strengths to estimate dropout prediction variation under different dropout settings and on a variety of tasks using three large datasets, MovieLens, Criteo, and EMNIST. Our approach provides an inference-once alternative to estimate dropout prediction variation as an auxiliary task. Moreover, we demonstrate that using activation features from a subset of the neural network layers can be sufficient to achieve variation estimation performance almost comparable to that of using activation features from all layers, thus reducing resources even further for variation estimation.
Is In-Domain Data Really Needed? A Pilot Study on Cross-Domain Calibration for Network Quantization
May 16, 2021


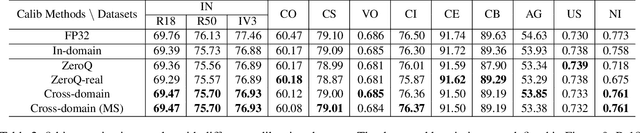
Post-training quantization methods use a set of calibration data to compute quantization ranges for network parameters and activations. The calibration data usually comes from the training dataset which could be inaccessible due to sensitivity of the data. In this work, we want to study such a problem: can we use out-of-domain data to calibrate the trained networks without knowledge of the original dataset? Specifically, we go beyond the domain of natural images to include drastically different domains such as X-ray images, satellite images and ultrasound images. We find cross-domain calibration leads to surprisingly stable performance of quantized models on 10 tasks in different image domains with 13 different calibration datasets. We also find that the performance of quantized models is correlated with the similarity of the Gram matrices between the source and calibration domains, which can be used as a criterion to choose calibration set for better performance. We believe our research opens the door to borrow cross-domain knowledge for network quantization and compression.
High-Resolution Deep Image Matting
Sep 14, 2020
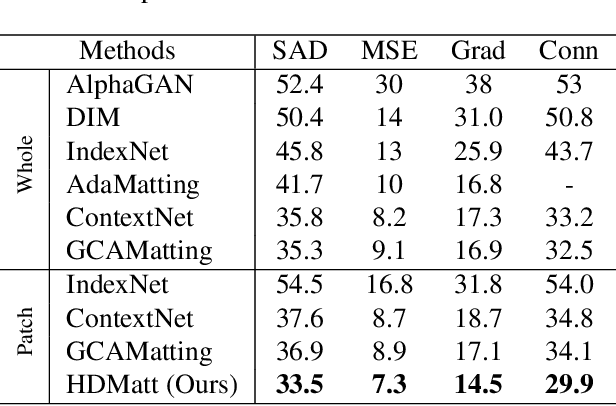
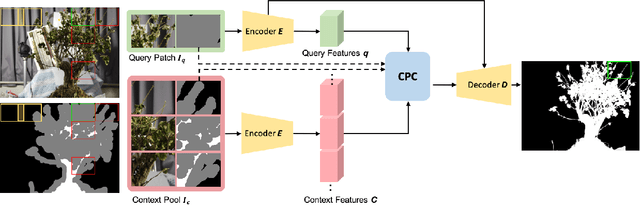
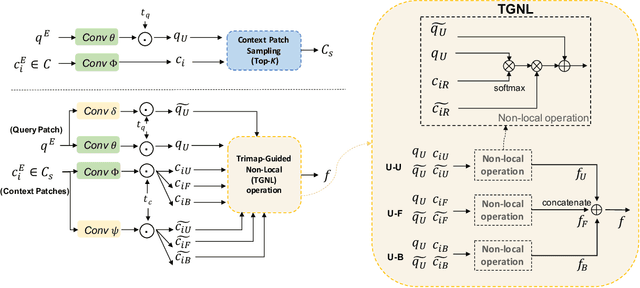
Image matting is a key technique for image and video editing and composition. Conventionally, deep learning approaches take the whole input image and an associated trimap to infer the alpha matte using convolutional neural networks. Such approaches set state-of-the-arts in image matting; however, they may fail in real-world matting applications due to hardware limitations, since real-world input images for matting are mostly of very high resolution. In this paper, we propose HDMatt, a first deep learning based image matting approach for high-resolution inputs. More concretely, HDMatt runs matting in a patch-based crop-and-stitch manner for high-resolution inputs with a novel module design to address the contextual dependency and consistency issues between different patches. Compared with vanilla patch-based inference which computes each patch independently, we explicitly model the cross-patch contextual dependency with a newly-proposed Cross-Patch Contextual module (CPC) guided by the given trimap. Extensive experiments demonstrate the effectiveness of the proposed method and its necessity for high-resolution inputs. Our HDMatt approach also sets new state-of-the-art performance on Adobe Image Matting and AlphaMatting benchmarks and produce impressive visual results on more real-world high-resolution images.
FOAL: Fast Online Adaptive Learning for Cardiac Motion Estimation
Mar 10, 2020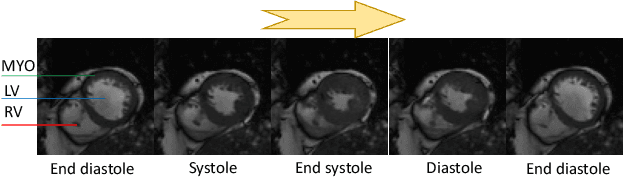
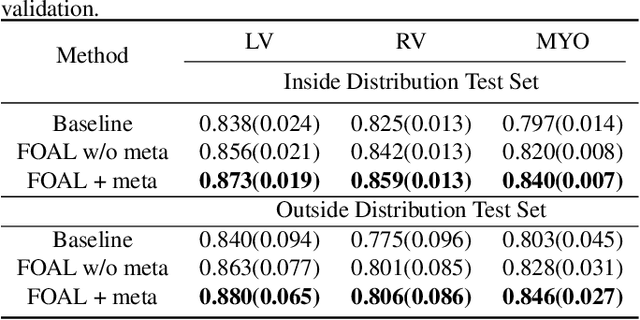
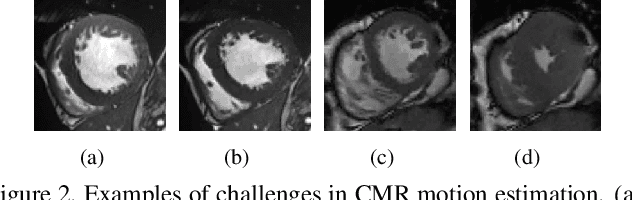

Motion estimation of cardiac MRI videos is crucial for the evaluation of human heart anatomy and function. Recent researches show promising results with deep learning-based methods. In clinical deployment, however, they suffer dramatic performance drops due to mismatched distributions between training and testing datasets, commonly encountered in the clinical environment. On the other hand, it is arguably impossible to collect all representative datasets and to train a universal tracker before deployment. In this context, we proposed a novel fast online adaptive learning (FOAL) framework: an online gradient descent based optimizer that is optimized by a meta-learner. The meta-learner enables the online optimizer to perform a fast and robust adaptation. We evaluated our method through extensive experiments on two public clinical datasets. The results showed the superior performance of FOAL in accuracy compared to the offline-trained tracking method. On average, the FOAL took only $0.4$ second per video for online optimization.
Any-Precision Deep Neural Networks
Nov 17, 2019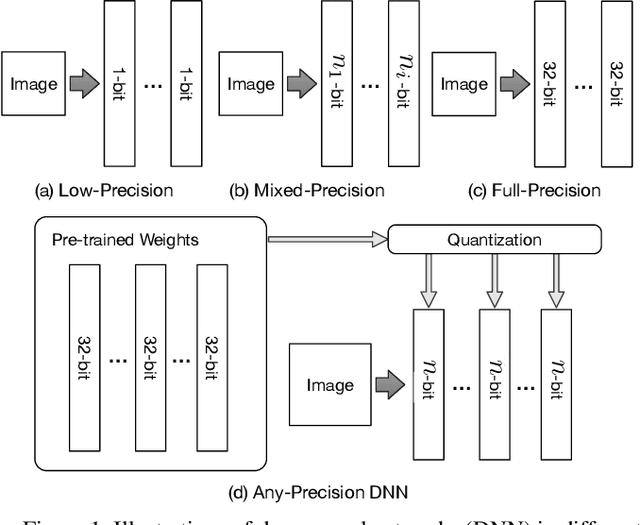
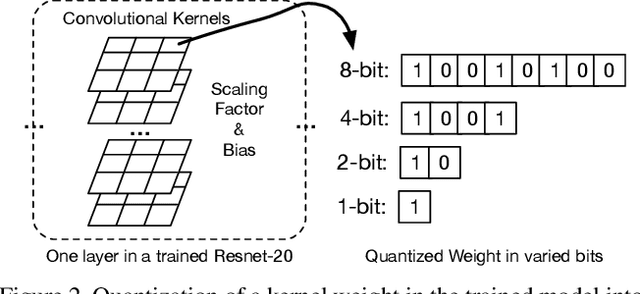

We present Any-Precision Deep Neural Networks (Any-Precision DNNs), which are trained with a new method that empowers learned DNNs to be flexible in any numerical precision during inference. The same model in runtime can be flexibly and directly set to different bit-width, by truncating the least significant bits, to support dynamic speed and accuracy trade-off. When all layers are set to low-bits, we show that the model achieved accuracy comparable to dedicated models trained at the same precision. This nice property facilitates flexible deployment of deep learning models in real-world applications, where in practice trade-offs between model accuracy and runtime efficiency are often sought. Previous literature presents solutions to train models at each individual fixed efficiency/accuracy trade-off point. But how to produce a model flexible in runtime precision is largely unexplored. When the demand of efficiency/accuracy trade-off varies from time to time or even dynamically changes in runtime, it is infeasible to re-train models accordingly, and the storage budget may forbid keeping multiple models. Our proposed framework achieves this flexibility without performance degradation. More importantly, we demonstrate that this achievement is agnostic to model architectures. We experimentally validated our method with different deep network backbones (AlexNet-small, Resnet-20, Resnet-50) on different datasets (SVHN, Cifar-10, ImageNet) and observed consistent results. Code and models will be available at https://github.com/haichaoyu.