 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAny-Precision Deep Neural Networks
Paper and Code
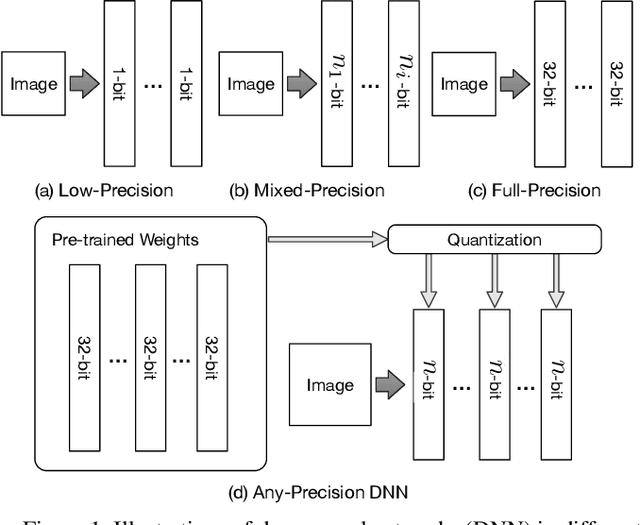
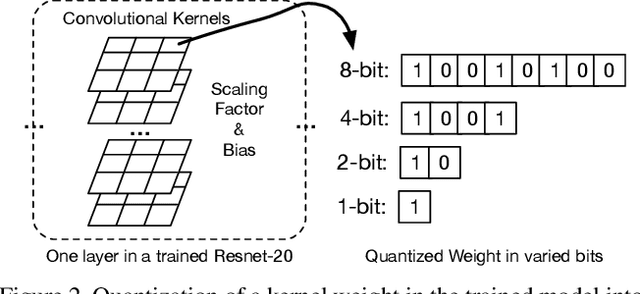

We present Any-Precision Deep Neural Networks (Any-Precision DNNs), which are trained with a new method that empowers learned DNNs to be flexible in any numerical precision during inference. The same model in runtime can be flexibly and directly set to different bit-width, by truncating the least significant bits, to support dynamic speed and accuracy trade-off. When all layers are set to low-bits, we show that the model achieved accuracy comparable to dedicated models trained at the same precision. This nice property facilitates flexible deployment of deep learning models in real-world applications, where in practice trade-offs between model accuracy and runtime efficiency are often sought. Previous literature presents solutions to train models at each individual fixed efficiency/accuracy trade-off point. But how to produce a model flexible in runtime precision is largely unexplored. When the demand of efficiency/accuracy trade-off varies from time to time or even dynamically changes in runtime, it is infeasible to re-train models accordingly, and the storage budget may forbid keeping multiple models. Our proposed framework achieves this flexibility without performance degradation. More importantly, we demonstrate that this achievement is agnostic to model architectures. We experimentally validated our method with different deep network backbones (AlexNet-small, Resnet-20, Resnet-50) on different datasets (SVHN, Cifar-10, ImageNet) and observed consistent results. Code and models will be available at https://github.com/haichaoyu.