 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Warmup: Complexity-Aware Curricula for Efficient Diffusion Training
Apr 08, 2026A key inefficiency in diffusion training occurs when a randomly initialized network, lacking visual priors, encounters gradients from the full complexity spectrum--most of which it lacks the capacity to resolve. We propose Data Warmup, a curriculum strategy that schedules training images from simple to complex without modifying the model or loss. Each image is scored offline by a semantic-aware complexity metric combining foreground dominance (how much of the image salient objects occupy) and foreground typicality (how closely the salient content matches learned visual prototypes). A temperature-controlled sampler then prioritizes low-complexity images early and anneals toward uniform sampling. On ImageNet 256x256 with SiT backbones (S/2 to XL/2), Data Warmup improves IS by up to 6.11 and FID by up to 3.41, reaching baseline quality tens of thousands of iterations earlier. Reversing the curriculum (exposing hard images first) degrades performance below the uniform baseline, confirming that the simple-to-complex ordering itself drives the gains. The method combines with orthogonal accelerators such as REPA and requires only ~10 minutes of one-time preprocessing with zero per-iteration overhead.
Scaling Up Audio-Synchronized Visual Animation: An Efficient Training Paradigm
Aug 05, 2025Recent advances in audio-synchronized visual animation enable control of video content using audios from specific classes. However, existing methods rely heavily on expensive manual curation of high-quality, class-specific training videos, posing challenges to scaling up to diverse audio-video classes in the open world. In this work, we propose an efficient two-stage training paradigm to scale up audio-synchronized visual animation using abundant but noisy videos. In stage one, we automatically curate large-scale videos for pretraining, allowing the model to learn diverse but imperfect audio-video alignments. In stage two, we finetune the model on manually curated high-quality examples, but only at a small scale, significantly reducing the required human effort. We further enhance synchronization by allowing each frame to access rich audio context via multi-feature conditioning and window attention. To efficiently train the model, we leverage pretrained text-to-video generator and audio encoders, introducing only 1.9\% additional trainable parameters to learn audio-conditioning capability without compromising the generator's prior knowledge. For evaluation, we introduce AVSync48, a benchmark with videos from 48 classes, which is 3$\times$ more diverse than previous benchmarks. Extensive experiments show that our method significantly reduces reliance on manual curation by over 10$\times$, while generalizing to many open classes.
From Prototypes to General Distributions: An Efficient Curriculum for Masked Image Modeling
Nov 16, 2024Masked Image Modeling (MIM) has emerged as a powerful self-supervised learning paradigm for visual representation learning, enabling models to acquire rich visual representations by predicting masked portions of images from their visible regions. While this approach has shown promising results, we hypothesize that its effectiveness may be limited by optimization challenges during early training stages, where models are expected to learn complex image distributions from partial observations before developing basic visual processing capabilities. To address this limitation, we propose a prototype-driven curriculum leagrning framework that structures the learning process to progress from prototypical examples to more complex variations in the dataset. Our approach introduces a temperature-based annealing scheme that gradually expands the training distribution, enabling more stable and efficient learning trajectories. Through extensive experiments on ImageNet-1K, we demonstrate that our curriculum learning strategy significantly improves both training efficiency and representation quality while requiring substantially fewer training epochs compared to standard Masked Auto-Encoding. Our findings suggest that carefully controlling the order of training examples plays a crucial role in self-supervised visual learning, providing a practical solution to the early-stage optimization challenges in MIM.
Accelerating Augmentation Invariance Pretraining
Oct 31, 2024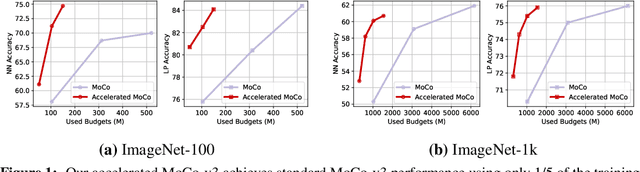

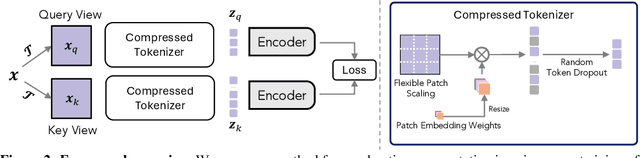
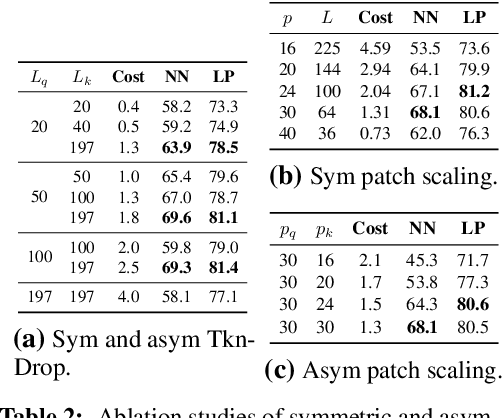
Our work tackles the computational challenges of contrastive learning methods, particularly for the pretraining of Vision Transformers (ViTs). Despite the effectiveness of contrastive learning, the substantial computational resources required for training often hinder their practical application. To mitigate this issue, we propose an acceleration framework, leveraging ViT's unique ability to generalize across inputs of varying sequence lengths. Our method employs a mix of sequence compression strategies, including randomized token dropout and flexible patch scaling, to reduce the cost of gradient estimation and accelerate convergence. We further provide an in-depth analysis of the gradient estimation error of various acceleration strategies as well as their impact on downstream tasks, offering valuable insights into the trade-offs between acceleration and performance. We also propose a novel procedure to identify an optimal acceleration schedule to adjust the sequence compression ratios to the training progress, ensuring efficient training without sacrificing downstream performance. Our approach significantly reduces computational overhead across various self-supervised learning algorithms on large-scale datasets. In ImageNet, our method achieves speedups of 4$\times$ in MoCo, 3.3$\times$ in SimCLR, and 2.5$\times$ in DINO, demonstrating substantial efficiency gains.
Patch Ranking: Efficient CLIP by Learning to Rank Local Patches
Sep 22, 2024Contrastive image-text pre-trained models such as CLIP have shown remarkable adaptability to downstream tasks. However, they face challenges due to the high computational requirements of the Vision Transformer (ViT) backbone. Current strategies to boost ViT efficiency focus on pruning patch tokens but fall short in addressing the multimodal nature of CLIP and identifying the optimal subset of tokens for maximum performance. To address this, we propose greedy search methods to establish a "Golden Ranking" and introduce a lightweight predictor specifically trained to approximate this Ranking. To compensate for any performance degradation resulting from token pruning, we incorporate learnable visual tokens that aid in restoring and potentially enhancing the model's performance. Our work presents a comprehensive and systematic investigation of pruning tokens within the ViT backbone of CLIP models. Through our framework, we successfully reduced 40% of patch tokens in CLIP's ViT while only suffering a minimal average accuracy loss of 0.3 across seven datasets. Our study lays the groundwork for building more computationally efficient multimodal models without sacrificing their performance, addressing a key challenge in the application of advanced vision-language models.
Towards Latent Masked Image Modeling for Self-Supervised Visual Representation Learning
Jul 22, 2024


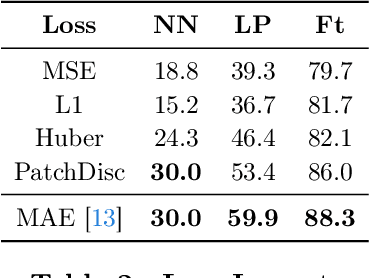
Masked Image Modeling (MIM) has emerged as a promising method for deriving visual representations from unlabeled image data by predicting missing pixels from masked portions of images. It excels in region-aware learning and provides strong initializations for various tasks, but struggles to capture high-level semantics without further supervised fine-tuning, likely due to the low-level nature of its pixel reconstruction objective. A promising yet unrealized framework is learning representations through masked reconstruction in latent space, combining the locality of MIM with the high-level targets. However, this approach poses significant training challenges as the reconstruction targets are learned in conjunction with the model, potentially leading to trivial or suboptimal solutions.Our study is among the first to thoroughly analyze and address the challenges of such framework, which we refer to as Latent MIM. Through a series of carefully designed experiments and extensive analysis, we identify the source of these challenges, including representation collapsing for joint online/target optimization, learning objectives, the high region correlation in latent space and decoding conditioning. By sequentially addressing these issues, we demonstrate that Latent MIM can indeed learn high-level representations while retaining the benefits of MIM models.
Audio-Synchronized Visual Animation
Mar 08, 2024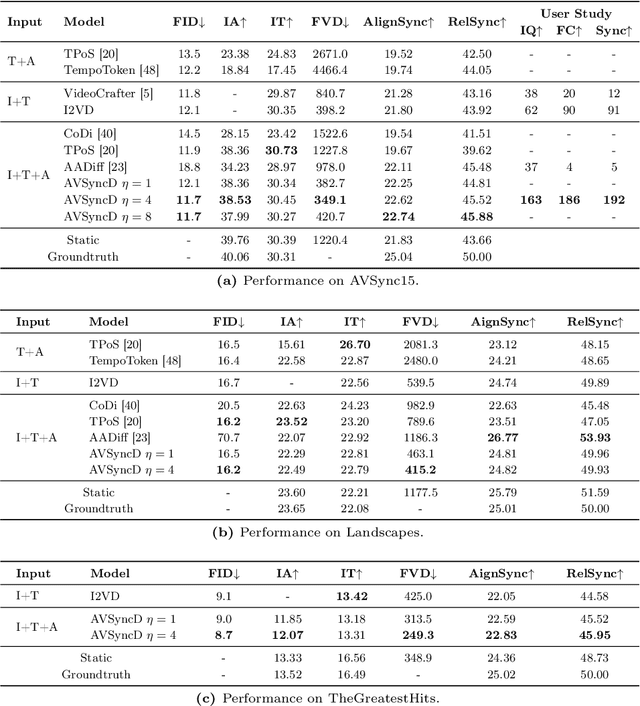
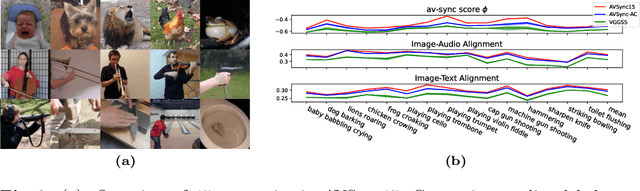

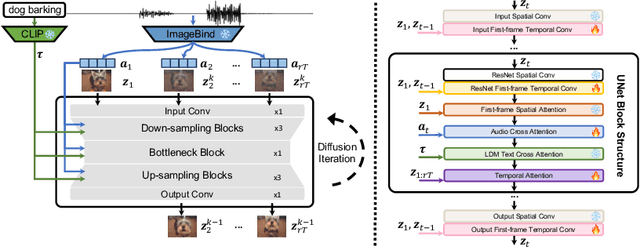
Current visual generation methods can produce high quality videos guided by texts. However, effectively controlling object dynamics remains a challenge. This work explores audio as a cue to generate temporally synchronized image animations. We introduce Audio Synchronized Visual Animation (ASVA), a task animating a static image to demonstrate motion dynamics, temporally guided by audio clips across multiple classes. To this end, we present AVSync15, a dataset curated from VGGSound with videos featuring synchronized audio visual events across 15 categories. We also present a diffusion model, AVSyncD, capable of generating dynamic animations guided by audios. Extensive evaluations validate AVSync15 as a reliable benchmark for synchronized generation and demonstrate our models superior performance. We further explore AVSyncDs potential in a variety of audio synchronized generation tasks, from generating full videos without a base image to controlling object motions with various sounds. We hope our established benchmark can open new avenues for controllable visual generation. More videos on project webpage https://lzhangbj.github.io/projects/asva/asva.html.
Unveiling the Power of Audio-Visual Early Fusion Transformers with Dense Interactions through Masked Modeling
Dec 02, 2023Humans possess a remarkable ability to integrate auditory and visual information, enabling a deeper understanding of the surrounding environment. This early fusion of audio and visual cues, demonstrated through cognitive psychology and neuroscience research, offers promising potential for developing multimodal perception models. However, training early fusion architectures poses significant challenges, as the increased model expressivity requires robust learning frameworks to harness their enhanced capabilities. In this paper, we address this challenge by leveraging the masked reconstruction framework, previously successful in unimodal settings, to train audio-visual encoders with early fusion. Additionally, we propose an attention-based fusion module that captures interactions between local audio and visual representations, enhancing the model's ability to capture fine-grained interactions. While effective, this procedure can become computationally intractable, as the number of local representations increases. Thus, to address the computational complexity, we propose an alternative procedure that factorizes the local representations before representing audio-visual interactions. Extensive evaluations on a variety of datasets demonstrate the superiority of our approach in audio-event classification, visual sound localization, sound separation, and audio-visual segmentation. These contributions enable the efficient training of deeply integrated audio-visual models and significantly advance the usefulness of early fusion architectures.
Why Is Prompt Tuning for Vision-Language Models Robust to Noisy Labels?
Jul 22, 2023



Vision-language models such as CLIP learn a generic text-image embedding from large-scale training data. A vision-language model can be adapted to a new classification task through few-shot prompt tuning. We find that such a prompt tuning process is highly robust to label noises. This intrigues us to study the key reasons contributing to the robustness of the prompt tuning paradigm. We conducted extensive experiments to explore this property and find the key factors are: 1) the fixed classname tokens provide a strong regularization to the optimization of the model, reducing gradients induced by the noisy samples; 2) the powerful pre-trained image-text embedding that is learned from diverse and generic web data provides strong prior knowledge for image classification. Further, we demonstrate that noisy zero-shot predictions from CLIP can be used to tune its own prompt, significantly enhancing prediction accuracy in the unsupervised setting. The code is available at https://github.com/CEWu/PTNL.
A Unified Audio-Visual Learning Framework for Localization, Separation, and Recognition
May 30, 2023The ability to accurately recognize, localize and separate sound sources is fundamental to any audio-visual perception task. Historically, these abilities were tackled separately, with several methods developed independently for each task. However, given the interconnected nature of source localization, separation, and recognition, independent models are likely to yield suboptimal performance as they fail to capture the interdependence between these tasks. To address this problem, we propose a unified audio-visual learning framework (dubbed OneAVM) that integrates audio and visual cues for joint localization, separation, and recognition. OneAVM comprises a shared audio-visual encoder and task-specific decoders trained with three objectives. The first objective aligns audio and visual representations through a localized audio-visual correspondence loss. The second tackles visual source separation using a traditional mix-and-separate framework. Finally, the third objective reinforces visual feature separation and localization by mixing images in pixel space and aligning their representations with those of all corresponding sound sources. Extensive experiments on MUSIC, VGG-Instruments, VGG-Music, and VGGSound datasets demonstrate the effectiveness of OneAVM for all three tasks, audio-visual source localization, separation, and nearest neighbor recognition, and empirically demonstrate a strong positive transfer between them.