 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Augmentation Invariance Pretraining
Paper and Code
Oct 31, 2024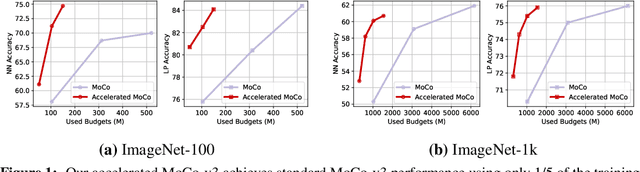

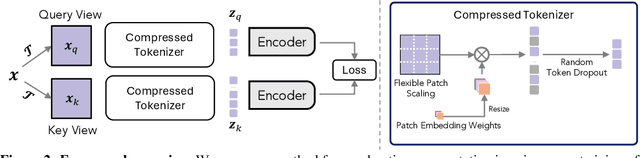
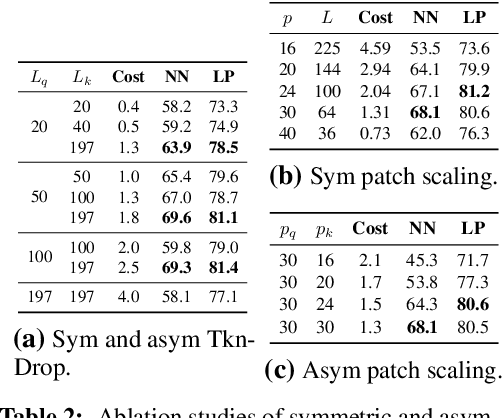
Our work tackles the computational challenges of contrastive learning methods, particularly for the pretraining of Vision Transformers (ViTs). Despite the effectiveness of contrastive learning, the substantial computational resources required for training often hinder their practical application. To mitigate this issue, we propose an acceleration framework, leveraging ViT's unique ability to generalize across inputs of varying sequence lengths. Our method employs a mix of sequence compression strategies, including randomized token dropout and flexible patch scaling, to reduce the cost of gradient estimation and accelerate convergence. We further provide an in-depth analysis of the gradient estimation error of various acceleration strategies as well as their impact on downstream tasks, offering valuable insights into the trade-offs between acceleration and performance. We also propose a novel procedure to identify an optimal acceleration schedule to adjust the sequence compression ratios to the training progress, ensuring efficient training without sacrificing downstream performance. Our approach significantly reduces computational overhead across various self-supervised learning algorithms on large-scale datasets. In ImageNet, our method achieves speedups of 4$\times$ in MoCo, 3.3$\times$ in SimCLR, and 2.5$\times$ in DINO, demonstrating substantial efficiency gains.