 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLASP: An online learning algorithm for Convex Losses And Squared Penalties
Jan 24, 2026We study Constrained Online Convex Optimization (COCO), where a learner chooses actions iteratively, observes both unanticipated convex loss and convex constraint, and accumulates loss while incurring penalties for constraint violations. We introduce CLASP (Convex Losses And Squared Penalties), an algorithm that minimizes cumulative loss together with squared constraint violations. Our analysis departs from prior work by fully leveraging the firm non-expansiveness of convex projectors, a proof strategy not previously applied in this setting. For convex losses, CLASP achieves regret $O\left(T^{\max\{β,1-β\}}\right)$ and cumulative squared penalty $O\left(T^{1-β}\right)$ for any $β\in (0,1)$. Most importantly, for strongly convex problems, CLASP provides the first logarithmic guarantees on both regret and cumulative squared penalty. In the strongly convex case, the regret is upper bounded by $O( \log T )$ and the cumulative squared penalty is also upper bounded by $O( \log T )$.
Outlier-resilient model fitting via percentile losses: Methods for general and convex residuals
May 15, 2024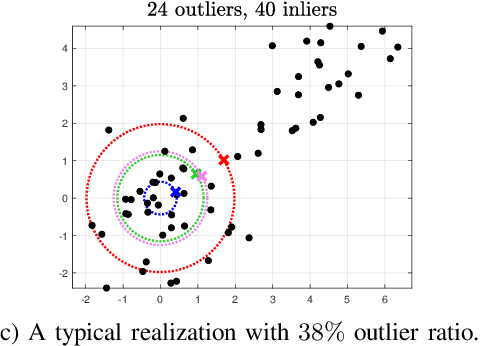
We consider the problem of robustly fitting a model to data that includes outliers by formulating a percentile optimization problem. This problem is non-smooth and non-convex, hence hard to solve. We derive properties that the minimizers of such problems must satisfy. These properties lead to methods that solve the percentile formulation both for general residuals and for convex residuals. The methods fit the model to subsets of the data, and then extract the solution of the percentile formulation from these partial fits. As illustrative simulations show, such methods endure higher outlier percentages, when compared with standard robust estimates. Additionally, the derived properties provide a broader and alternative theoretical validation for existing robust methods, whose validity was previously limited to specific forms of the residuals.
A Multi-Token Coordinate Descent Method for Semi-Decentralized Vertical Federated Learning
Sep 18, 2023Communication efficiency is a major challenge in federated learning (FL). In client-server schemes, the server constitutes a bottleneck, and while decentralized setups spread communications, they do not necessarily reduce them due to slower convergence. We propose Multi-Token Coordinate Descent (MTCD), a communication-efficient algorithm for semi-decentralized vertical federated learning, exploiting both client-server and client-client communications when each client holds a small subset of features. Our multi-token method can be seen as a parallel Markov chain (block) coordinate descent algorithm and it subsumes the client-server and decentralized setups as special cases. We obtain a convergence rate of $\mathcal{O}(1/T)$ for nonconvex objectives when tokens roam over disjoint subsets of clients and for convex objectives when they roam over possibly overlapping subsets. Numerical results show that MTCD improves the state-of-the-art communication efficiency and allows for a tunable amount of parallel communications.
Robust Target Localization in 2D: A Value-at-Risk Approach
Jul 05, 2023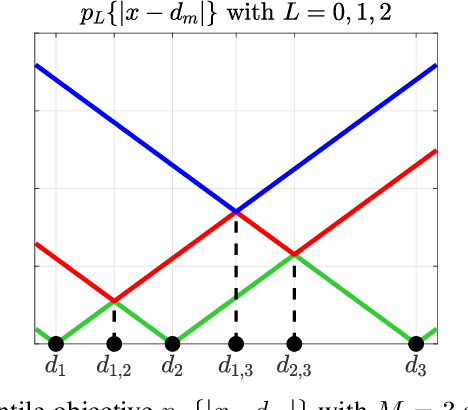
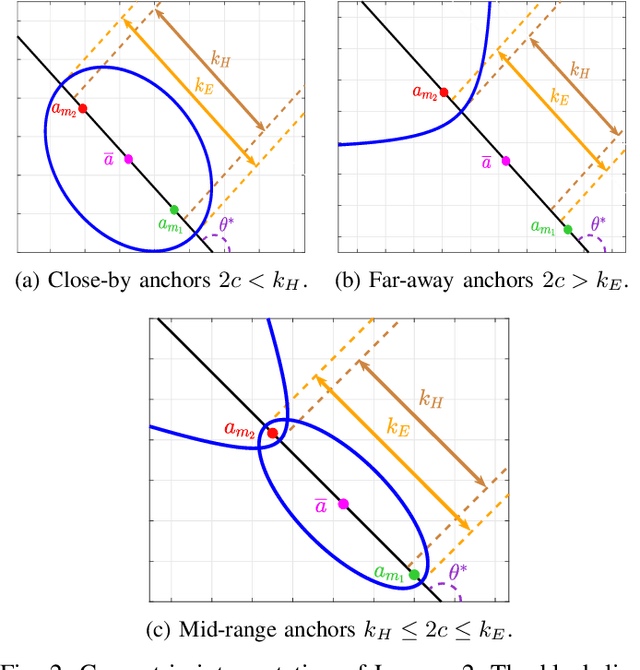
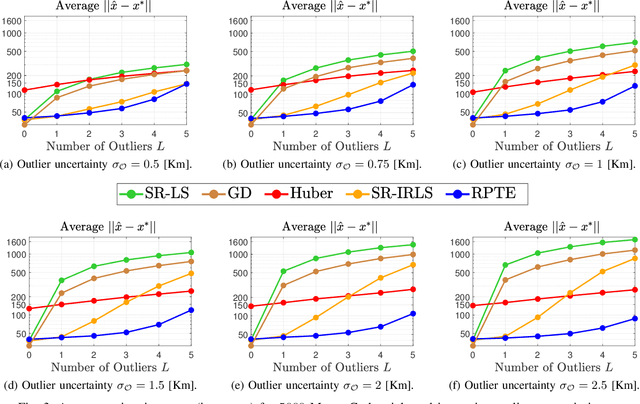
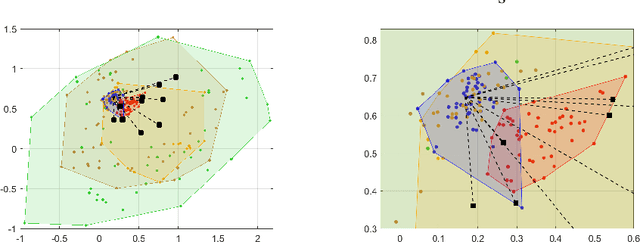
This paper consider considers the problem of locating a two dimensional target from range-measurements containing outliers. Assuming that the number of outlier is known, we formulate the problem of minimizing inlier losses while ignoring outliers. This leads to a combinatorial, non-convex, non-smooth problem involving the percentile function. Using the framework of risk analysis from Rockafellar et al., we start by interpreting this formulation as a Value-at-risk (VaR) problem from portfolio optimization. To the best of our knowledge, this is the first time that a localization problem was formulated using risk analysis theory. To study the VaR formulation, we start by designing a majorizer set that contains any solution of a general percentile problem. This set is useful because, when applied to a localization scenario in 2D, it allows to majorize the solution set in terms of singletons, circumferences, ellipses and hyperbolas. Using know parametrization of these curves, we propose a grid method for the original non-convex problem. So we reduce the task of optimizing the VaR objective to that of efficiently sampling the proposed majorizer set. We compare our algorithm with four benchmarks in target localization. Numerical simulations show that our method is fast while, on average, improving the accuracy of the best benchmarks by at least 100m in a 1 Km$^2$ area.
Distributed detection of ARMA signals
Apr 14, 2023
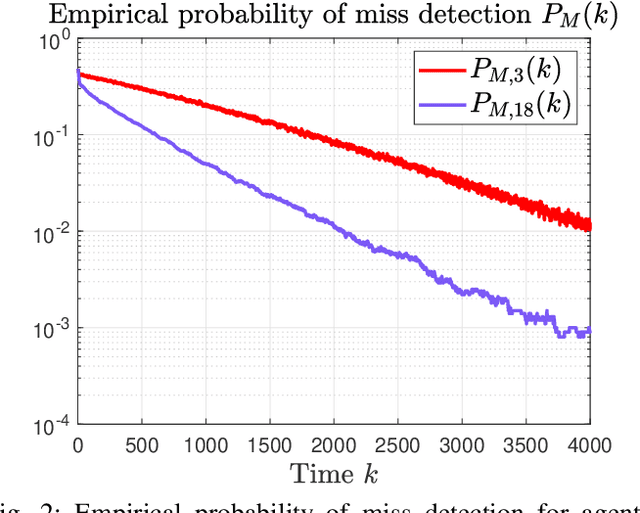
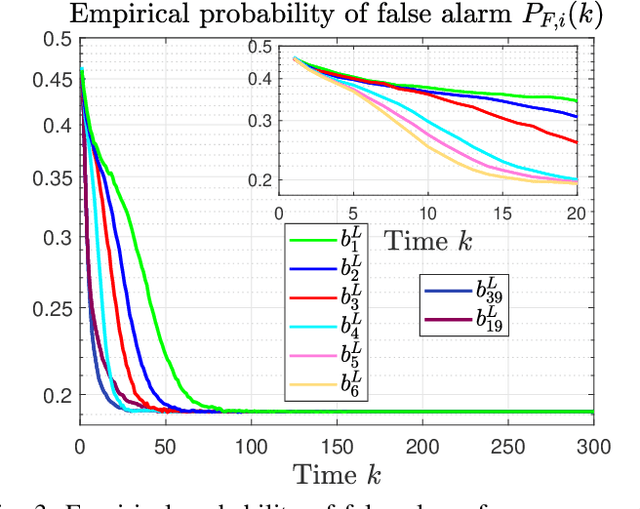
This paper considers a distributed detection setup where agents in a network want to detect a time-varying signal embedded in temporally correlated noise. The signal of interest is the impulse response of an ARMA (auto-regressive moving average) filter, and the noise is the output of yet another ARMA filter which is fed white Gaussian noise. For this extended problem setup, which can prompt novel behaviour, we propose a comprehensive solution. First, we extend the well-known running consensus detector (RCD) to this correlated setup; then, we design an efficient implementation of the RCD by exploiting the underlying ARMA structures; and, finally, we derive the theoretical asymptotic performance of the RCD in this ARMA setup. It turns out that the error probability at each agent exhibits one of two regimes: either (a) the error probability decays exponentially fast to zero or (b) it converges to a strictly positive error floor. While regime (a) spans staple results in large deviation theory, regime (b) is new in distributed detection and is elicited by the ARMA setup. We fully characterize these two scenarios: we give necessary and sufficient conditions, phrased in terms of the zero and poles of the underlying ARMA models, for the emergence of each regime, and provide closed-form expressions for both the decay rates of regime (a) and the positive error floors of regime (b). Our analysis also shows that the ARMA setup leads to two novel features: (1) the threshold level used in RCD can influence the asymptotics of the error probabilities and (2) some agents might be weakly informative, in the sense that their observations do not improve the asymptotic performance of RCD and, as such, can be safely muted to save sensing resources. Numerical simulations illustrate and confirm the theoretical findings.
Decentralized EM to Learn Gaussian Mixtures from Datasets Distributed by Features
Jan 24, 2022



Expectation Maximization (EM) is the standard method to learn Gaussian mixtures. Yet its classic, centralized form is often infeasible, due to privacy concerns and computational and communication bottlenecks. Prior work dealt with data distributed by examples, horizontal partitioning, but we lack a counterpart for data scattered by features, an increasingly common scheme (e.g. user profiling with data from multiple entities). To fill this gap, we provide an EM-based algorithm to fit Gaussian mixtures to Vertically Partitioned data (VP-EM). In federated learning setups, our algorithm matches the centralized EM fitting of Gaussian mixtures constrained to a subspace. In arbitrary communication graphs, consensus averaging allows VP-EM to run on large peer-to-peer networks as an EM approximation. This mismatch comes from consensus error only, which vanishes exponentially fast with the number of consensus rounds. We demonstrate VP-EM on various topologies for both synthetic and real data, evaluating its approximation of centralized EM and seeing that it outperforms the available benchmark.
Robust Localization with Bounded Noise: Creating a Superset of the Possible Target Positions via Linear-Fractional Representations
Oct 06, 2021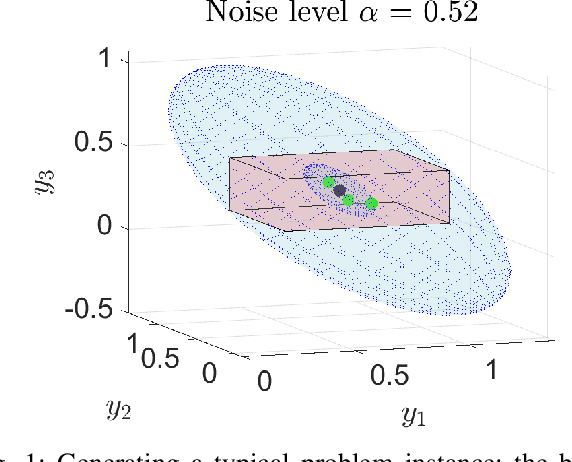
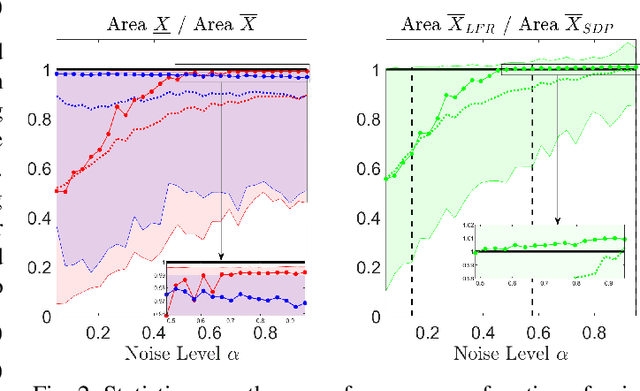
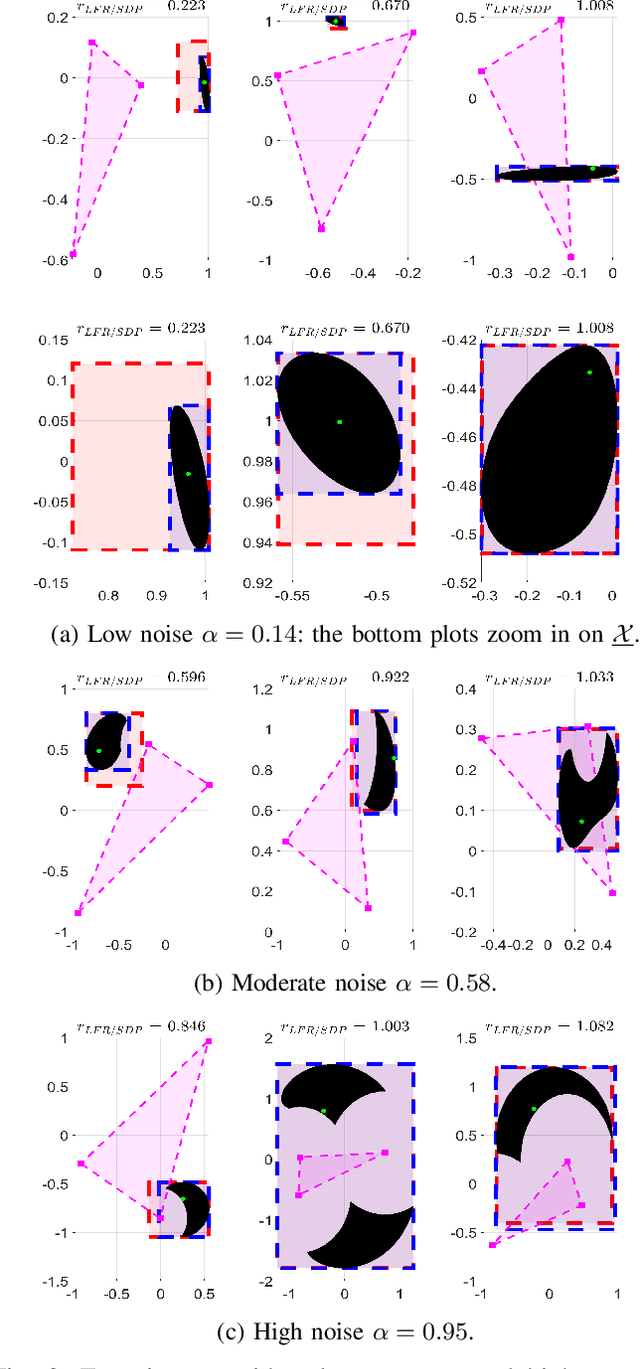
Locating an object is key in many applications, namely in high-stakes real-world scenarios, like detecting humans or obstacles in vehicular networks. In such applications, pointwise estimates are not enough, and the full area of locations compatible with acquired measurements should be available, for robust and safe navigation. This paper presents a scalable algorithm for creating a superset of all possible target locations, given range measurements with bounded error. The assumption of bounded error is mild, since both hardware characteristics and application scenario impose upper bounds on measurement errors, and the bounded set can be taken from confidence regions of the error distributions. We construct the superset through convex relaxations that use Linear Fractional Representations (LFRs), a well-known technique in robust control. Additionally, we also provide a statistical interpretation for the set of possible target positions, considering the framework of robust estimation. Finally, we provide empirical validation by comparing our LFR method with a standard semidefinite relaxation. Our approach has shown to pay off for small to moderate noise levels: the supersets created by our method are tighter than the benchmark ones being about 20% smaller in size. Furthermore, our method tends to be tight because the size of the supersets is, on median terms, within a 3% margin of a lower bound computed via grid search.
COCO Denoiser: Using Co-Coercivity for Variance Reduction in Stochastic Convex Optimization
Sep 07, 2021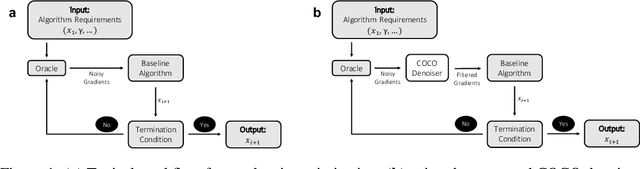
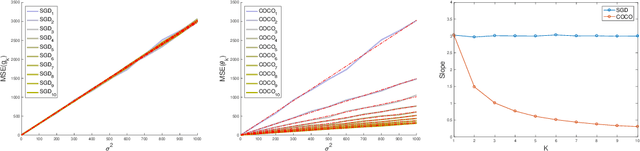
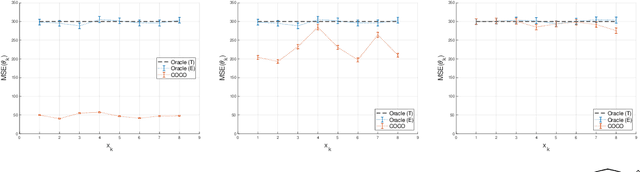
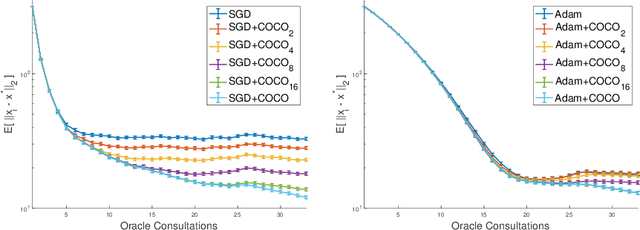
First-order methods for stochastic optimization have undeniable relevance, in part due to their pivotal role in machine learning. Variance reduction for these algorithms has become an important research topic. In contrast to common approaches, which rarely leverage global models of the objective function, we exploit convexity and L-smoothness to improve the noisy estimates outputted by the stochastic gradient oracle. Our method, named COCO denoiser, is the joint maximum likelihood estimator of multiple function gradients from their noisy observations, subject to co-coercivity constraints between them. The resulting estimate is the solution of a convex Quadratically Constrained Quadratic Problem. Although this problem is expensive to solve by interior point methods, we exploit its structure to apply an accelerated first-order algorithm, the Fast Dual Proximal Gradient method. Besides analytically characterizing the proposed estimator, we show empirically that increasing the number and proximity of the queried points leads to better gradient estimates. We also apply COCO in stochastic settings by plugging it in existing algorithms, such as SGD, Adam or STRSAGA, outperforming their vanilla versions, even in scenarios where our modelling assumptions are mismatched.
DJAM: distributed Jacobi asynchronous method for learning personal models
Jul 20, 2018
Processing data collected by a network of agents often boils down to solving an optimization problem. The distributed nature of these problems calls for methods that are, themselves, distributed. While most collaborative learning problems require agents to reach a common (or consensus) model, there are situations in which the consensus solution may not be optimal. For instance, agents may want to reach a compromise between agreeing with their neighbors and minimizing a personal loss function. We present DJAM, a Jacobi-like distributed algorithm for learning personalized models. This method is implementation-friendly: it has no hyperparameters that need tuning, it is asynchronous, and its updates only require single-neighbor interactions. We prove that DJAM converges with probability one to the solution, provided that the personal loss functions are strongly convex and have Lipschitz gradient. We then give evidence that DJAM is on par with state-of-the-art methods: our method reaches a solution with error similar to the error of a carefully tuned ADMM in about the same number of single-neighbor interactions.