 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDialog: A Python Toolkit for End-to-End Agent Building, User Simulation, Dialog Generation, and Evaluation
Dec 12, 2025We present SDialog, an MIT-licensed open-source Python toolkit that unifies dialog generation, evaluation and mechanistic interpretability into a single end-to-end framework for building and analyzing LLM-based conversational agents. Built around a standardized \texttt{Dialog} representation, SDialog provides: (1) persona-driven multi-agent simulation with composable orchestration for controlled, synthetic dialog generation, (2) comprehensive evaluation combining linguistic metrics, LLM-as-a-judge and functional correctness validators, (3) mechanistic interpretability tools for activation inspection and steering via feature ablation and induction, and (4) audio generation with full acoustic simulation including 3D room modeling and microphone effects. The toolkit integrates with all major LLM backends, enabling mixed-backend experiments under a unified API. By coupling generation, evaluation, and interpretability in a dialog-centric architecture, SDialog enables researchers to build, benchmark and understand conversational systems more systematically.
Personalized Clinical Note Generation from Doctor-Patient Conversations
Aug 07, 2024


In this work, we present a novel technique to improve the quality of draft clinical notes for physicians. This technique is concentrated on the ability to model implicit physician conversation styles and note preferences. We also introduce a novel technique for the enrollment of new physicians when a limited number of clinical notes paired with conversations are available for that physician, without the need to re-train a model to support them. We show that our technique outperforms the baseline model by improving the ROUGE-2 score of the History of Present Illness section by 13.8%, the Physical Examination section by 88.6%, and the Assessment & Plan section by 50.8%.
Comparing Two Model Designs for Clinical Note Generation; Is an LLM a Useful Evaluator of Consistency?
Apr 09, 2024

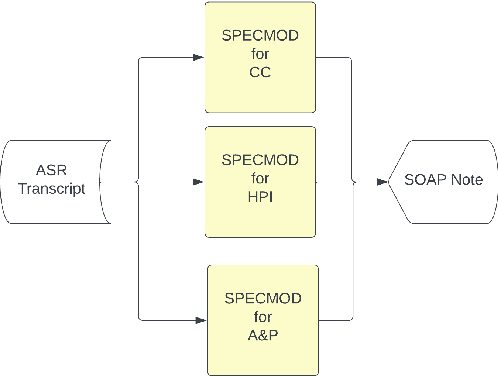

Following an interaction with a patient, physicians are responsible for the submission of clinical documentation, often organized as a SOAP note. A clinical note is not simply a summary of the conversation but requires the use of appropriate medical terminology. The relevant information can then be extracted and organized according to the structure of the SOAP note. In this paper we analyze two different approaches to generate the different sections of a SOAP note based on the audio recording of the conversation, and specifically examine them in terms of note consistency. The first approach generates the sections independently, while the second method generates them all together. In this work we make use of PEGASUS-X Transformer models and observe that both methods lead to similar ROUGE values (less than 1% difference) and have no difference in terms of the Factuality metric. We perform a human evaluation to measure aspects of consistency and demonstrate that LLMs like Llama2 can be used to perform the same tasks with roughly the same agreement as the human annotators. Between the Llama2 analysis and the human reviewers we observe a Cohen Kappa inter-rater reliability of 0.79, 1.00, and 0.32 for consistency of age, gender, and body part injury, respectively. With this we demonstrate the usefulness of leveraging an LLM to measure quality indicators that can be identified by humans but are not currently captured by automatic metrics. This allows scaling evaluation to larger data sets, and we find that clinical note consistency improves by generating each new section conditioned on the output of all previously generated sections.
Revisiting text decomposition methods for NLI-based factuality scoring of summaries
Nov 30, 2022



Scoring the factuality of a generated summary involves measuring the degree to which a target text contains factual information using the input document as support. Given the similarities in the problem formulation, previous work has shown that Natural Language Inference models can be effectively repurposed to perform this task. As these models are trained to score entailment at a sentence level, several recent studies have shown that decomposing either the input document or the summary into sentences helps with factuality scoring. But is fine-grained decomposition always a winning strategy? In this paper we systematically compare different granularities of decomposition -- from document to sub-sentence level, and we show that the answer is no. Our results show that incorporating additional context can yield improvement, but that this does not necessarily apply to all datasets. We also show that small changes to previously proposed entailment-based scoring methods can result in better performance, highlighting the need for caution in model and methodology selection for downstream tasks.
AdaFocal: Calibration-aware Adaptive Focal Loss
Nov 21, 2022



Much recent work has been devoted to the problem of ensuring that a neural network's confidence scores match the true probability of being correct, i.e. the calibration problem. Of note, it was found that training with focal loss leads to better calibration than cross-entropy while achieving similar level of accuracy \cite{mukhoti2020}. This success stems from focal loss regularizing the entropy of the model's prediction (controlled by the parameter $\gamma$), thereby reining in the model's overconfidence. Further improvement is expected if $\gamma$ is selected independently for each training sample (Sample-Dependent Focal Loss (FLSD-53) \cite{mukhoti2020}). However, FLSD-53 is based on heuristics and does not generalize well. In this paper, we propose a calibration-aware adaptive focal loss called AdaFocal that utilizes the calibration properties of focal (and inverse-focal) loss and adaptively modifies $\gamma_t$ for different groups of samples based on $\gamma_{t-1}$ from the previous step and the knowledge of model's under/over-confidence on the validation set. We evaluate AdaFocal on various image recognition and one NLP task, covering a wide variety of network architectures, to confirm the improvement in calibration while achieving similar levels of accuracy. Additionally, we show that models trained with AdaFocal achieve a significant boost in out-of-distribution detection.
Leveraging Pretrained Models for Automatic Summarization of Doctor-Patient Conversations
Sep 24, 2021

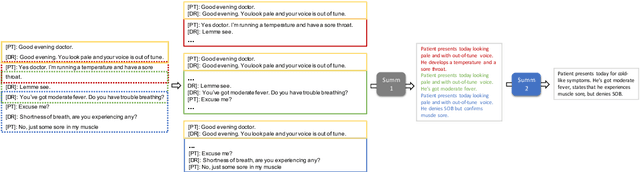
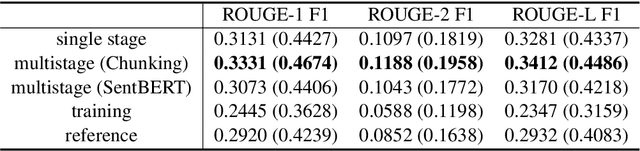
Fine-tuning pretrained models for automatically summarizing doctor-patient conversation transcripts presents many challenges: limited training data, significant domain shift, long and noisy transcripts, and high target summary variability. In this paper, we explore the feasibility of using pretrained transformer models for automatically summarizing doctor-patient conversations directly from transcripts. We show that fluent and adequate summaries can be generated with limited training data by fine-tuning BART on a specially constructed dataset. The resulting models greatly surpass the performance of an average human annotator and the quality of previous published work for the task. We evaluate multiple methods for handling long conversations, comparing them to the obvious baseline of truncating the conversation to fit the pretrained model length limit. We introduce a multistage approach that tackles the task by learning two fine-tuned models: one for summarizing conversation chunks into partial summaries, followed by one for rewriting the collection of partial summaries into a complete summary. Using a carefully chosen fine-tuning dataset, this method is shown to be effective at handling longer conversations, improving the quality of generated summaries. We conduct both an automatic evaluation (through ROUGE and two concept-based metrics focusing on medical findings) and a human evaluation (through qualitative examples from literature, assessing hallucination, generalization, fluency, and general quality of the generated summaries).
Posterior Calibrated Training on Sentence Classification Tasks
May 01, 2020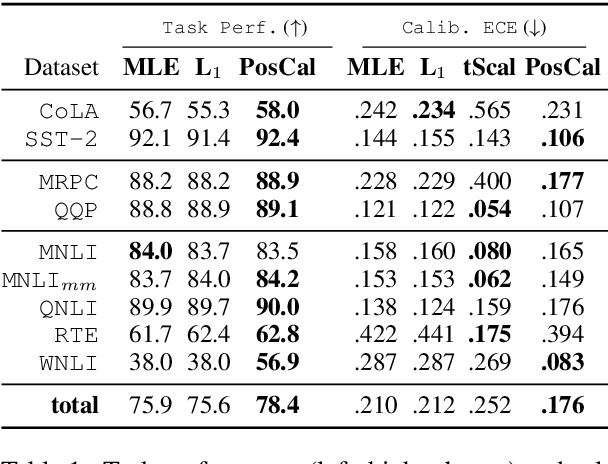
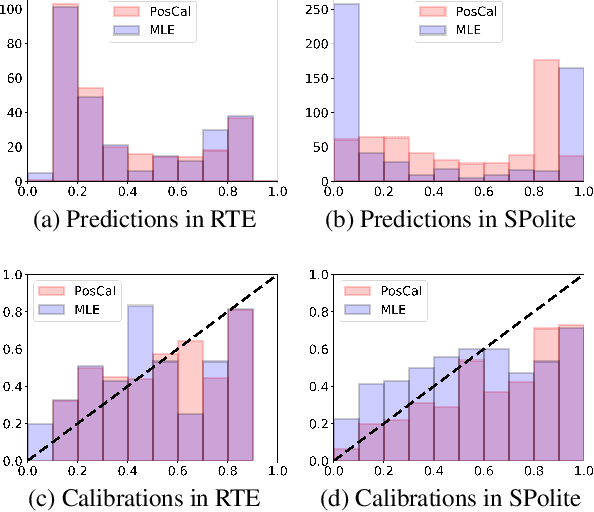
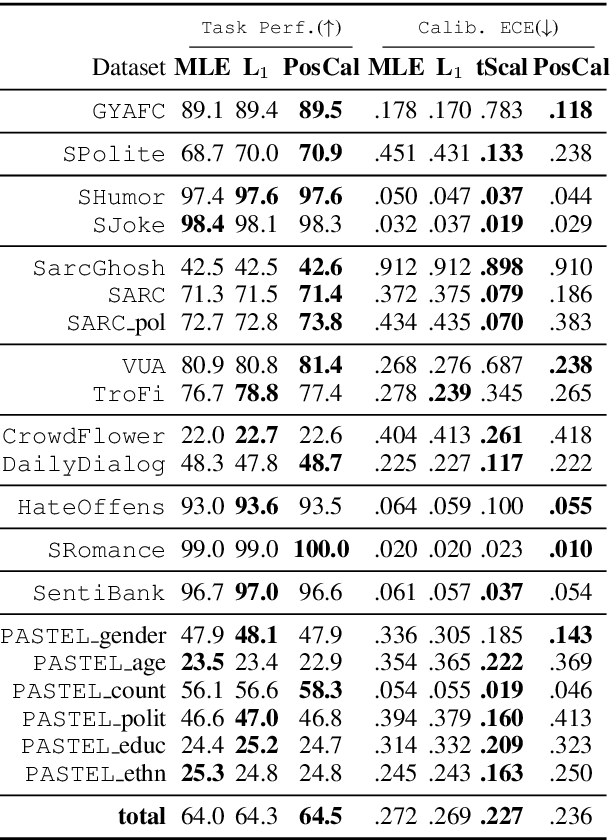
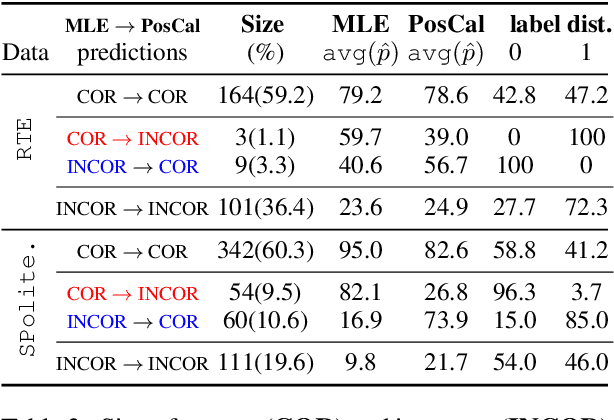
Most classification models work by first predicting a posterior probability distribution over all classes and then selecting that class with the largest estimated probability. In many settings however, the quality of posterior probability itself (e.g., 65% chance having diabetes), gives more reliable information than the final predicted class alone. When these methods are shown to be poorly calibrated, most fixes to date have relied on posterior calibration, which rescales the predicted probabilities but often has little impact on final classifications. Here we propose an end-to-end training procedure called posterior calibrated (PosCal) training that directly optimizes the objective while minimizing the difference between the predicted and empirical posterior probabilities.We show that PosCal not only helps reduce the calibration error but also improve task performance by penalizing drops in performance of both objectives. Our PosCal achieves about 2.5% of task performance gain and 16.1% of calibration error reduction on GLUE (Wang et al., 2018) compared to the baseline. We achieved the comparable task performance with 13.2% calibration error reduction on xSLUE (Kang and Hovy, 2019), but not outperforming the two-stage calibration baseline. PosCal training can be easily extendable to any types of classification tasks as a form of regularization term. Also, PosCal has the advantage that it incrementally tracks needed statistics for the calibration objective during the training process, making efficient use of large training sets.