 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Two Model Designs for Clinical Note Generation; Is an LLM a Useful Evaluator of Consistency?
Paper and Code
Apr 09, 2024

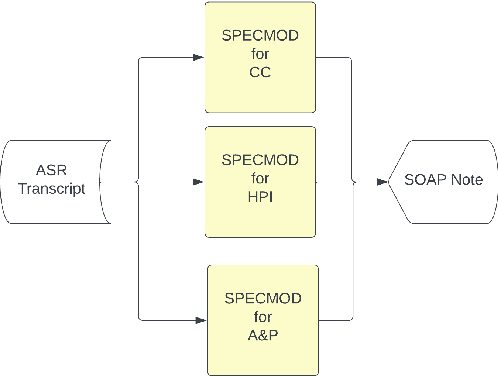

Following an interaction with a patient, physicians are responsible for the submission of clinical documentation, often organized as a SOAP note. A clinical note is not simply a summary of the conversation but requires the use of appropriate medical terminology. The relevant information can then be extracted and organized according to the structure of the SOAP note. In this paper we analyze two different approaches to generate the different sections of a SOAP note based on the audio recording of the conversation, and specifically examine them in terms of note consistency. The first approach generates the sections independently, while the second method generates them all together. In this work we make use of PEGASUS-X Transformer models and observe that both methods lead to similar ROUGE values (less than 1% difference) and have no difference in terms of the Factuality metric. We perform a human evaluation to measure aspects of consistency and demonstrate that LLMs like Llama2 can be used to perform the same tasks with roughly the same agreement as the human annotators. Between the Llama2 analysis and the human reviewers we observe a Cohen Kappa inter-rater reliability of 0.79, 1.00, and 0.32 for consistency of age, gender, and body part injury, respectively. With this we demonstrate the usefulness of leveraging an LLM to measure quality indicators that can be identified by humans but are not currently captured by automatic metrics. This allows scaling evaluation to larger data sets, and we find that clinical note consistency improves by generating each new section conditioned on the output of all previously generated sections.