 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Instructions: Compositional Instruction Tuning on Large Language Models
Feb 18, 2024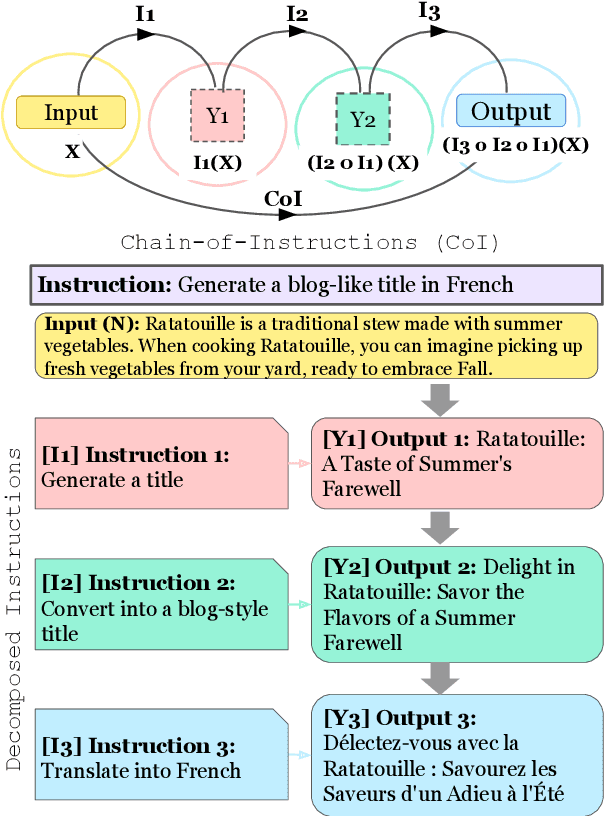
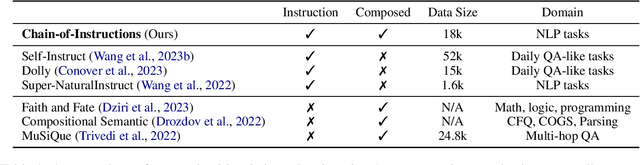

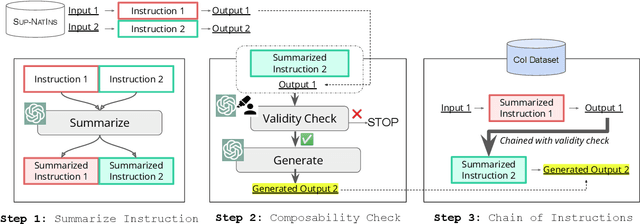
Fine-tuning large language models (LLMs) with a collection of large and diverse instructions has improved the model's generalization to different tasks, even for unseen tasks. However, most existing instruction datasets include only single instructions, and they struggle to follow complex instructions composed of multiple subtasks (Wang et al., 2023a). In this work, we propose a novel concept of compositional instructions called chain-of-instructions (CoI), where the output of one instruction becomes an input for the next like a chain. Unlike the conventional practice of solving single instruction tasks, our proposed method encourages a model to solve each subtask step by step until the final answer is reached. CoI-tuning (i.e., fine-tuning with CoI instructions) improves the model's ability to handle instructions composed of multiple subtasks. CoI-tuned models also outperformed baseline models on multilingual summarization, demonstrating the generalizability of CoI models on unseen composite downstream tasks.
Cluster-Guided Label Generation in Extreme Multi-Label Classification
Feb 17, 2023For extreme multi-label classification (XMC), existing classification-based models poorly perform for tail labels and often ignore the semantic relations among labels, like treating "Wikipedia" and "Wiki" as independent and separate labels. In this paper, we cast XMC as a generation task (XLGen), where we benefit from pre-trained text-to-text models. However, generating labels from the extremely large label space is challenging without any constraints or guidance. We, therefore, propose to guide label generation using label cluster information to hierarchically generate lower-level labels. We also find that frequency-based label ordering and using decoding ensemble methods are critical factors for the improvements in XLGen. XLGen with cluster guidance significantly outperforms the classification and generation baselines on tail labels, and also generally improves the overall performance in four popular XMC benchmarks. In human evaluation, we also find XLGen generates unseen but plausible labels. Our code is now available at https://github.com/alexa/xlgen-eacl-2023.
Posterior Calibrated Training on Sentence Classification Tasks
May 01, 2020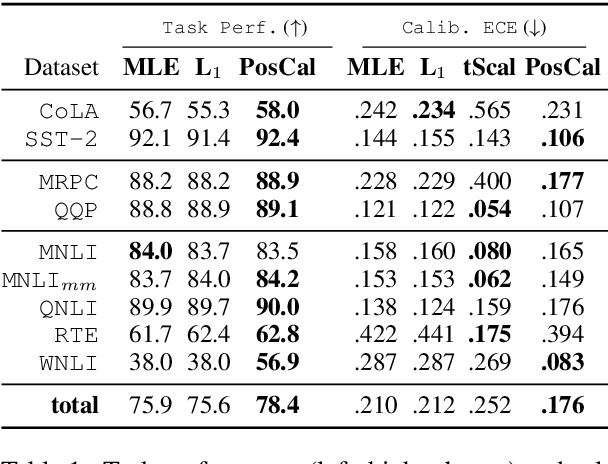
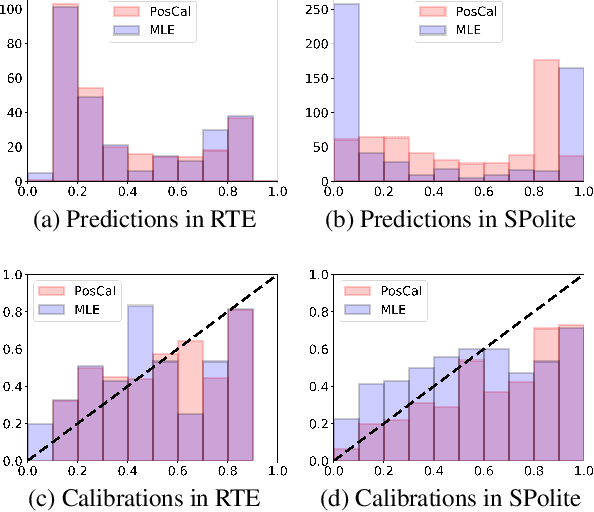
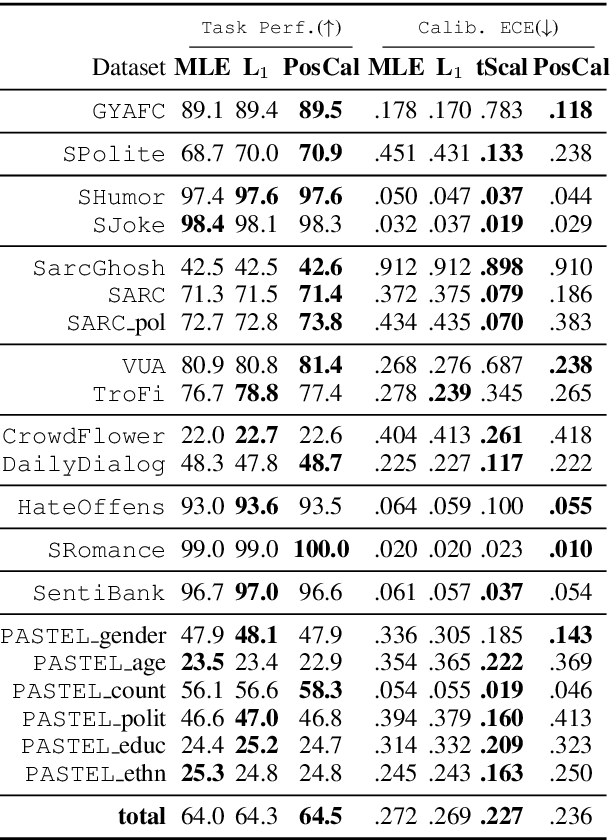
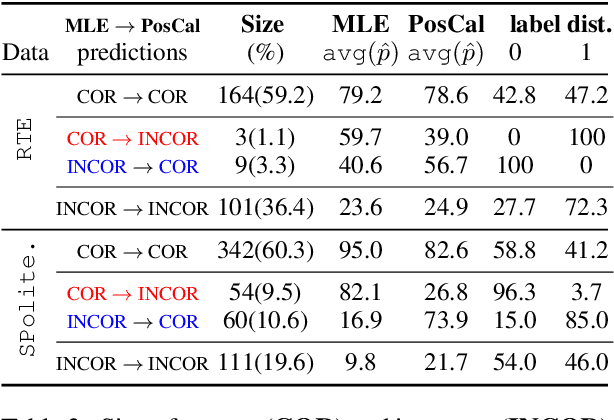
Most classification models work by first predicting a posterior probability distribution over all classes and then selecting that class with the largest estimated probability. In many settings however, the quality of posterior probability itself (e.g., 65% chance having diabetes), gives more reliable information than the final predicted class alone. When these methods are shown to be poorly calibrated, most fixes to date have relied on posterior calibration, which rescales the predicted probabilities but often has little impact on final classifications. Here we propose an end-to-end training procedure called posterior calibrated (PosCal) training that directly optimizes the objective while minimizing the difference between the predicted and empirical posterior probabilities.We show that PosCal not only helps reduce the calibration error but also improve task performance by penalizing drops in performance of both objectives. Our PosCal achieves about 2.5% of task performance gain and 16.1% of calibration error reduction on GLUE (Wang et al., 2018) compared to the baseline. We achieved the comparable task performance with 13.2% calibration error reduction on xSLUE (Kang and Hovy, 2019), but not outperforming the two-stage calibration baseline. PosCal training can be easily extendable to any types of classification tasks as a form of regularization term. Also, PosCal has the advantage that it incrementally tracks needed statistics for the calibration objective during the training process, making efficient use of large training sets.
Earlier Isn't Always Better: Sub-aspect Analysis on Corpus and System Biases in Summarization
Aug 30, 2019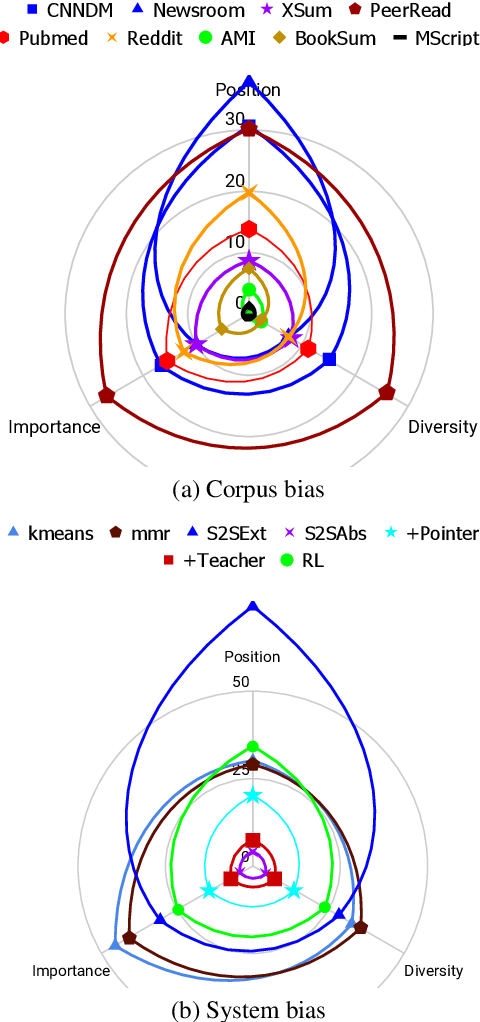

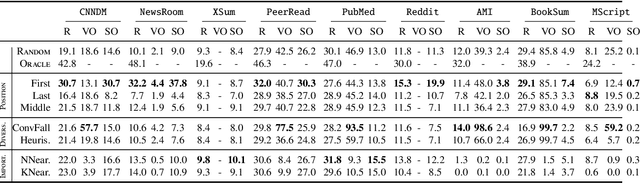
Despite the recent developments on neural summarization systems, the underlying logic behind the improvements from the systems and its corpus-dependency remains largely unexplored. Position of sentences in the original text, for example, is a well known bias for news summarization. Following in the spirit of the claim that summarization is a combination of sub-functions, we define three sub-aspects of summarization: position, importance, and diversity and conduct an extensive analysis of the biases of each sub-aspect with respect to the domain of nine different summarization corpora (e.g., news, academic papers, meeting minutes, movie script, books, posts). We find that while position exhibits substantial bias in news articles, this is not the case, for example, with academic papers and meeting minutes. Furthermore, our empirical study shows that different types of summarization systems (e.g., neural-based) are composed of different degrees of the sub-aspects. Our study provides useful lessons regarding consideration of underlying sub-aspects when collecting a new summarization dataset or developing a new system.