 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Objective and Feature Weights of Minkowski Weighted k-Means
Mar 26, 2026The Minkowski weighted k-means (mwk-means) algorithm extends classical k-means by incorporating feature weights and a Minkowski distance. Despite its empirical success, its theoretical properties remain insufficiently understood. We show that the mwk-means objective can be expressed as a power-mean aggregation of within-cluster dispersions, with the order determined by the Minkowski exponent p. This formulation reveals how p controls the transition between selective and uniform use of features. Using this representation, we derive bounds for the objective function and characterise the structure of the feature weights, showing that they depend only on relative dispersion and follow a power-law relationship with dispersion ratios. This leads to explicit guarantees on the suppression of high-dispersion features. Finally, we establish convergence of the algorithm and provide a unified theoretical interpretation of its behaviour.
BayTTA: Uncertainty-aware medical image classification with optimized test-time augmentation using Bayesian model averaging
Jun 25, 2024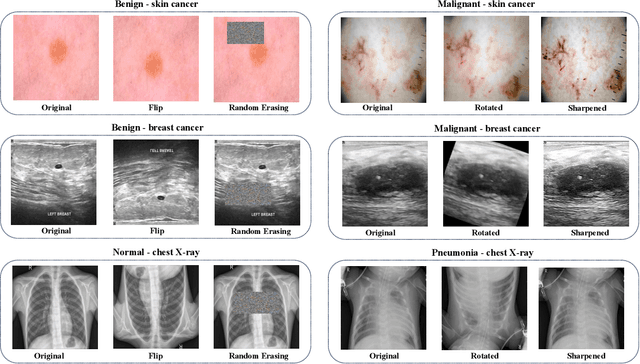
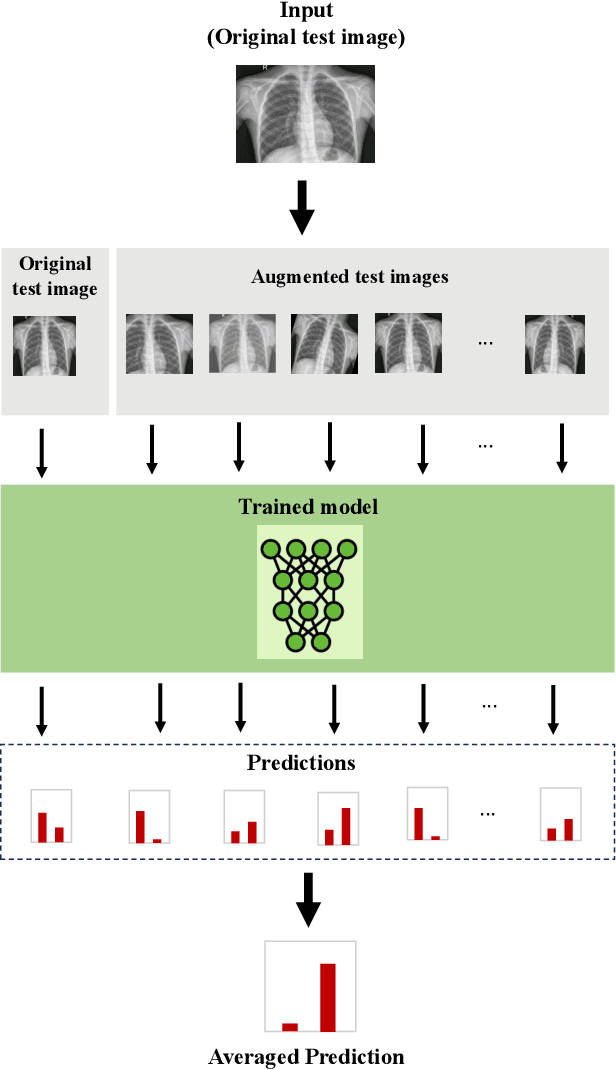
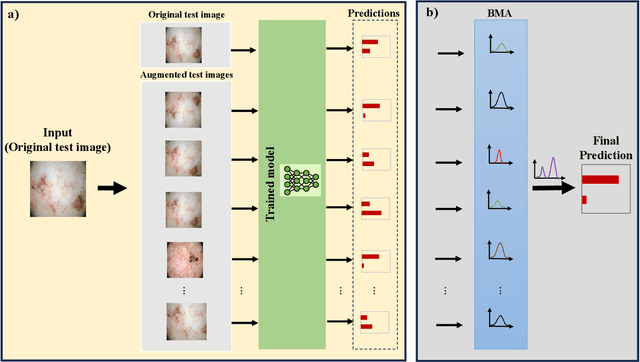
Test-time augmentation (TTA) is a well-known technique employed during the testing phase of computer vision tasks. It involves aggregating multiple augmented versions of input data. Combining predictions using a simple average formulation is a common and straightforward approach after performing TTA. This paper introduces a novel framework for optimizing TTA, called BayTTA (Bayesian-based TTA), which is based on Bayesian Model Averaging (BMA). First, we generate a model list associated with different variations of the input data created through TTA. Then, we use BMA to combine model predictions weighted by their respective posterior probabilities. Such an approach allows one to take into account model uncertainty, and thus to enhance the predictive performance of the related machine learning or deep learning model. We evaluate the performance of BayTTA on various public data, including three medical image datasets comprising skin cancer, breast cancer, and chest X-ray images and two well-known gene editing datasets, CRISPOR and GUIDE-seq. Our experimental results indicate that BayTTA can be effectively integrated into state-of-the-art deep learning models used in medical image analysis as well as into some popular pre-trained CNN models such as VGG-16, MobileNetV2, DenseNet201, ResNet152V2, and InceptionRes-NetV2, leading to the enhancement in their accuracy and robustness performance.
Improving cluster recovery with feature rescaling factors
Dec 01, 2020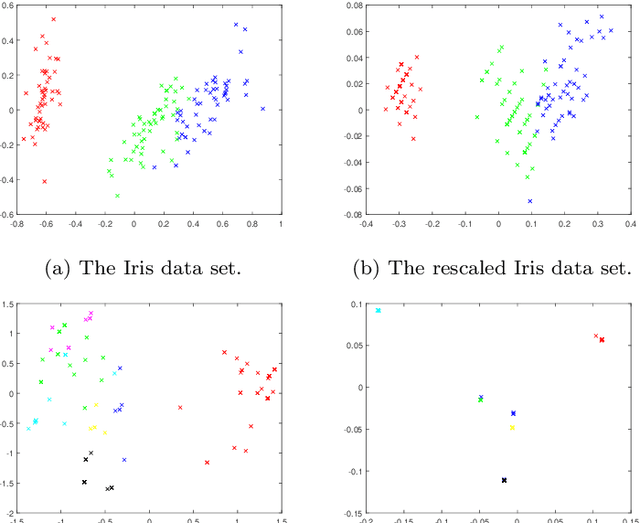



The data preprocessing stage is crucial in clustering. Features may describe entities using different scales. To rectify this, one usually applies feature normalisation aiming at rescaling features so that none of them overpowers the others in the objective function of the selected clustering algorithm. In this paper, we argue that the rescaling procedure should not treat all features identically. Instead, it should favour the features that are more meaningful for clustering. With this in mind, we introduce a feature rescaling method that takes into account the within-cluster degree of relevance of each feature. Our comprehensive simulation study, carried out on real and synthetic data, with and without noise features, clearly demonstrates that clustering methods that use the proposed data normalization strategy clearly outperform those that use traditional data normalization.
A Review of Uncertainty Quantification in Deep Learning: Techniques, Applications and Challenges
Nov 17, 2020

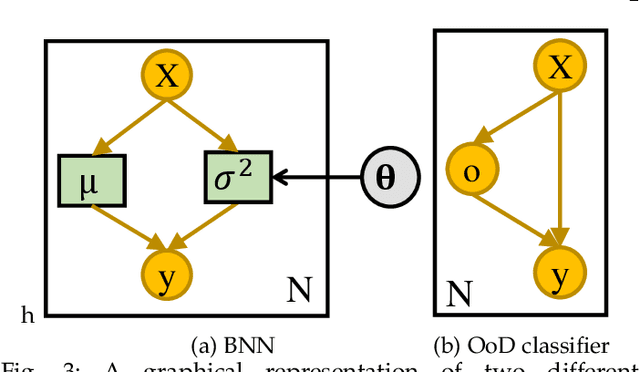
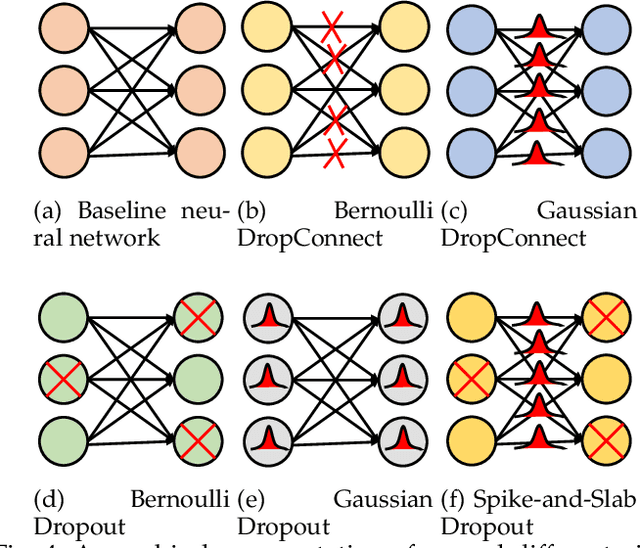
Uncertainty quantification (UQ) plays a pivotal role in reduction of uncertainties during both optimization and decision making processes. It can be applied to solve a variety of real-world applications in science and engineering. Bayesian approximation and ensemble learning techniques are two most widely-used UQ methods in the literature. In this regard, researchers have proposed different UQ methods and examined their performance in a variety of applications such as computer vision (e.g., self-driving cars and object detection), image processing (e.g., image restoration), medical image analysis (e.g., medical image classification and segmentation), natural language processing (e.g., text classification, social media texts and recidivism risk-scoring), bioinformatics, etc. This study reviews recent advances in UQ methods used in deep learning. Moreover, we also investigate the application of these methods in reinforcement learning (RL). Then, we outline a few important applications of UQ methods. Finally, we briefly highlight the fundamental research challenges faced by UQ methods and discuss the future research directions in this field.
XtracTree for Regulator Validation of Bagging Methods Used in Retail Banking
Apr 08, 2020
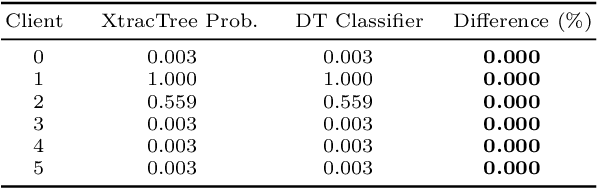

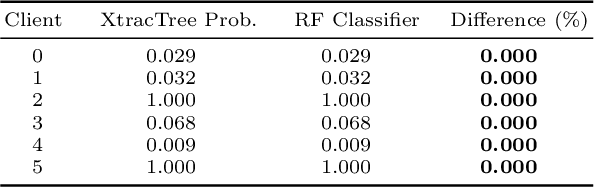
Bootstrap aggregation, known as bagging, is one of the most popular ensemble methods used in machine learning (ML). An ensemble method is a supervised ML method that combines multiple hypotheses to form a single hypothesis used for prediction. A bagging algorithm combines multiple classifiers modelled on different sub-samples of the same data set to build one large classifier. Large retail banks are nowadays using the power of ML algorithms, including decision trees and random forests, to optimize the retail banking activities. However, AI bank researchers face a strong challenge from their own model validation department as well as from national financial regulators. Each proposed ML model has to be validated and clear rules for every algorithm-based decision have to be established. In this context, we propose XtracTree, an algorithm that is capable of effectively converting an ML bagging classifier, such as a decision tree or a random forest, into simple "if-then" rules satisfying the requirements of model validation. Our algorithm is also capable of highlighting the decision path for each individual sample or a group of samples, addressing any concern from the regulators regarding ML "black-box". We use a public loan data set from Kaggle to illustrate the usefulness of our approach. Our experiments indicate that, using XtracTree, we are able to ensure a better understanding for our model, leading to an easier model validation by national financial regulators and the internal model validation department.
Provably efficient reconstruction of policy networks
Feb 07, 2020



Recent research has shown that learning poli-cies parametrized by large neural networks can achieve significant success on challenging reinforcement learning problems. However, when memory is limited, it is not always possible to store such models exactly for inference, and com-pressing the policy into a compact representation might be necessary. We propose a general framework for policy representation, which reduces this problem to finding a low-dimensional embedding of a given density function in a separable inner product space. Our framework allows us to de-rive strong theoretical guarantees, controlling the error of the reconstructed policies. Such guaran-tees are typically lacking in black-box models, but are very desirable in risk-sensitive tasks. Our experimental results suggest that the reconstructed policies can use less than 10%of the number of parameters in the original networks, while incurring almost no decrease in rewards.
A-Ward_p\b{eta}: Effective hierarchical clustering using the Minkowski metric and a fast k -means initialisation
Nov 03, 2016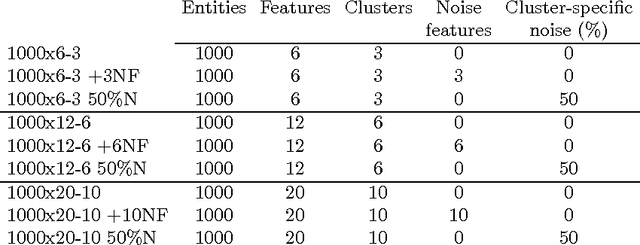
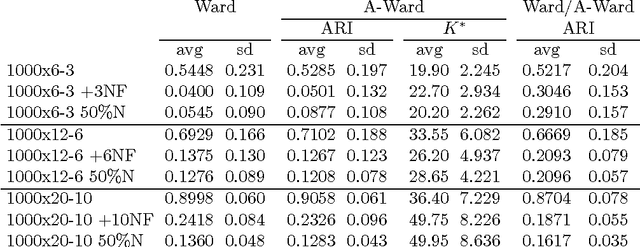
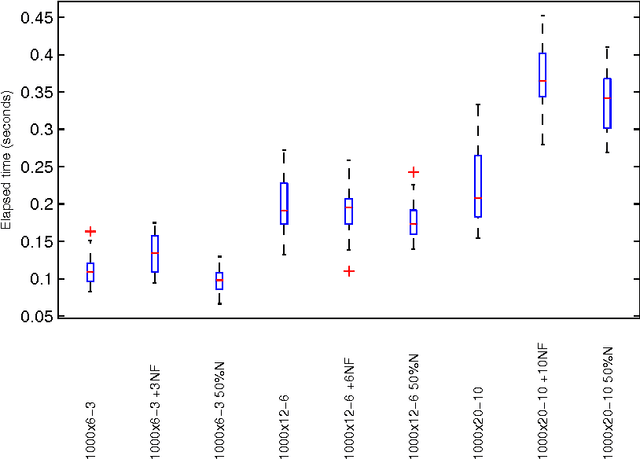
In this paper we make two novel contributions to hierarchical clustering. First, we introduce an anomalous pattern initialisation method for hierarchical clustering algorithms, called A-Ward, capable of substantially reducing the time they take to converge. This method generates an initial partition with a sufficiently large number of clusters. This allows the cluster merging process to start from this partition rather than from a trivial partition composed solely of singletons. Our second contribution is an extension of the Ward and Ward p algorithms to the situation where the feature weight exponent can differ from the exponent of the Minkowski distance. This new method, called A-Ward p\b{eta} , is able to generate a much wider variety of clustering solutions. We also demonstrate that its parameters can be estimated reasonably well by using a cluster validity index. We perform numerous experiments using data sets with two types of noise, insertion of noise features and blurring within-cluster values of some features. These experiments allow us to conclude: (i) our anomalous pattern initialisation method does indeed reduce the time a hierarchical clustering algorithm takes to complete, without negatively impacting its cluster recovery ability; (ii) A-Ward p\b{eta} provides better cluster recovery than both Ward and Ward p.