 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving cluster recovery with feature rescaling factors
Paper and Code
Dec 01, 2020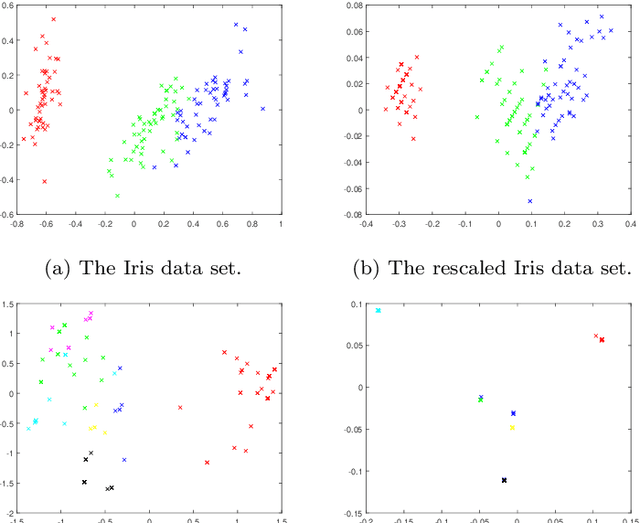



The data preprocessing stage is crucial in clustering. Features may describe entities using different scales. To rectify this, one usually applies feature normalisation aiming at rescaling features so that none of them overpowers the others in the objective function of the selected clustering algorithm. In this paper, we argue that the rescaling procedure should not treat all features identically. Instead, it should favour the features that are more meaningful for clustering. With this in mind, we introduce a feature rescaling method that takes into account the within-cluster degree of relevance of each feature. Our comprehensive simulation study, carried out on real and synthetic data, with and without noise features, clearly demonstrates that clustering methods that use the proposed data normalization strategy clearly outperform those that use traditional data normalization.