Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Suffix Tree Approach to Email Filtering
Paper and Code
Dec 06, 2005

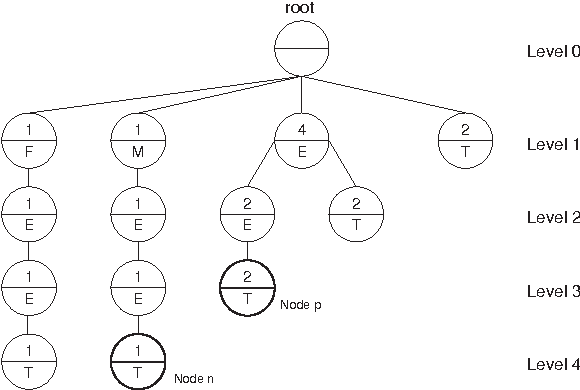

We present an approach to email filtering based on the suffix tree data structure. A method for the scoring of emails using the suffix tree is developed and a number of scoring and score normalisation functions are tested. Our results show that the character level representation of emails and classes facilitated by the suffix tree can significantly improve classification accuracy when compared with the currently popular methods, such as naive Bayes. We believe the method can be extended to the classification of documents in other domains.
* Revisions made in the light of reviewer comments. Main changes: (i)
The extension and elaboration of section 4.4 which describes the scoring
algorithm; (ii) Favouring the use of false positive and false negative
performance measures over the use of precision and recall; (iii) The addition
of ROC curves wherever possible; and (iv) Inclusion of performance statistics
for algorithm. Re-submitted 5th August 2005
View paper on