 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorization Dynamics in Knowledge Distillation for Language Models
Jan 21, 2026Knowledge Distillation (KD) is increasingly adopted to transfer capabilities from large language models to smaller ones, offering significant improvements in efficiency and utility while often surpassing standard fine-tuning. Beyond performance, KD is also explored as a privacy-preserving mechanism to mitigate the risk of training data leakage. While training data memorization has been extensively studied in standard pre-training and fine-tuning settings, its dynamics in a knowledge distillation setup remain poorly understood. In this work, we study memorization across the KD pipeline using three large language model (LLM) families (Pythia, OLMo-2, Qwen-3) and three datasets (FineWeb, Wikitext, Nemotron-CC-v2). We find: (1) distilled models memorize significantly less training data than standard fine-tuning (reducing memorization by more than 50%); (2) some examples are inherently easier to memorize and account for a large fraction of memorization during distillation (over ~95%); (3) student memorization is predictable prior to distillation using features based on zlib entropy, KL divergence, and perplexity; and (4) while soft and hard distillation have similar overall memorization rates, hard distillation poses a greater risk: it inherits $2.7\times$ more teacher-specific examples than soft distillation. Overall, we demonstrate that distillation can provide both improved generalization and reduced memorization risks compared to standard fine-tuning.
Privacy Ripple Effects from Adding or Removing Personal Information in Language Model Training
Feb 21, 2025Due to the sensitive nature of personally identifiable information (PII), its owners may have the authority to control its inclusion or request its removal from large-language model (LLM) training. Beyond this, PII may be added or removed from training datasets due to evolving dataset curation techniques, because they were newly scraped for retraining, or because they were included in a new downstream fine-tuning stage. We find that the amount and ease of PII memorization is a dynamic property of a model that evolves throughout training pipelines and depends on commonly altered design choices. We characterize three such novel phenomena: (1) similar-appearing PII seen later in training can elicit memorization of earlier-seen sequences in what we call assisted memorization, and this is a significant factor (in our settings, up to 1/3); (2) adding PII can increase memorization of other PII significantly (in our settings, as much as $\approx\!7.5\times$); and (3) removing PII can lead to other PII being memorized. Model creators should consider these first- and second-order privacy risks when training models to avoid the risk of new PII regurgitation.
Multiple References with Meaningful Variations Improve Literary Machine Translation
Dec 24, 2024While a source sentence can be translated in many ways, most machine translation (MT) models are trained with only a single reference. Previous work has shown that using synthetic paraphrases can improve MT. This paper investigates best practices for employing multiple references by analyzing the semantic similarity among different English translations of world literature in the Par3 dataset. We classify the semantic similarity between paraphrases into three groups: low, medium, and high, and fine-tune two different LLMs (mT5-large and LLaMA-2-7B) for downstream MT tasks. Across different models, holding the total training instances constant, single-reference but more source texts only marginally outperforms multiple-reference with half of the source texts. Moreover, using paraphrases of medium and high semantic similarity outperforms an unfiltered dataset (+BLEU 0.3-0.5, +COMET 0.2-0.9, +chrF++ 0.25-0.32). Our code is publicly available on GitHub.
Mind the Gap: Analyzing Lacunae with Transformer-Based Transcription
Jun 28, 2024Historical documents frequently suffer from damage and inconsistencies, including missing or illegible text resulting from issues such as holes, ink problems, and storage damage. These missing portions or gaps are referred to as lacunae. In this study, we employ transformer-based optical character recognition (OCR) models trained on synthetic data containing lacunae in a supervised manner. We demonstrate their effectiveness in detecting and restoring lacunae, achieving a success rate of 65%, compared to a base model lacking knowledge of lacunae, which achieves only 5% restoration. Additionally, we investigate the mechanistic properties of the model, such as the log probability of transcription, which can identify lacunae and other errors (e.g., mistranscriptions due to complex writing or ink issues) in line images without directly inspecting the image. This capability could be valuable for scholars seeking to distinguish images containing lacunae or errors from clean ones. Although we explore the potential of attention mechanisms in flagging lacunae and transcription errors, our findings suggest it is not a significant factor. Our work highlights a promising direction in utilizing transformer-based OCR models for restoring or analyzing damaged historical documents.
Composition and Deformance: Measuring Imageability with a Text-to-Image Model
Jun 05, 2023



Although psycholinguists and psychologists have long studied the tendency of linguistic strings to evoke mental images in hearers or readers, most computational studies have applied this concept of imageability only to isolated words. Using recent developments in text-to-image generation models, such as DALLE mini, we propose computational methods that use generated images to measure the imageability of both single English words and connected text. We sample text prompts for image generation from three corpora: human-generated image captions, news article sentences, and poem lines. We subject these prompts to different deformances to examine the model's ability to detect changes in imageability caused by compositional change. We find high correlation between the proposed computational measures of imageability and human judgments of individual words. We also find the proposed measures more consistently respond to changes in compositionality than baseline approaches. We discuss possible effects of model training and implications for the study of compositionality in text-to-image models.
Adapting Transformer Language Models for Predictive Typing in Brain-Computer Interfaces
May 05, 2023
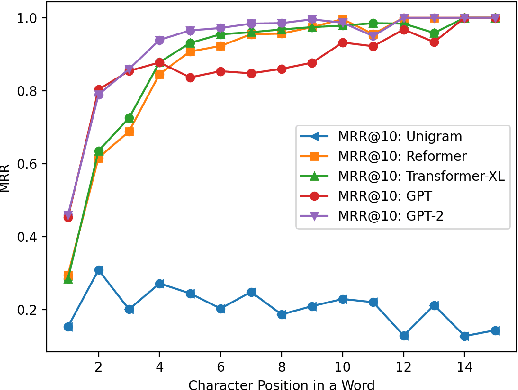

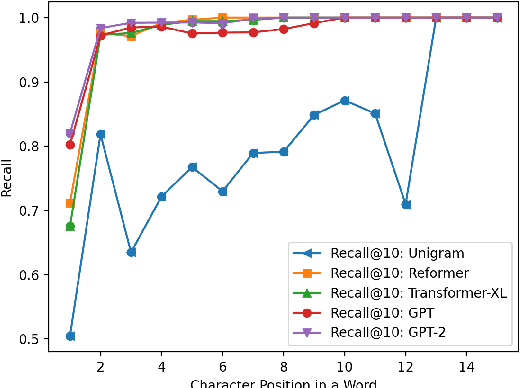
Brain-computer interfaces (BCI) are an important mode of alternative and augmentative communication for many people. Unlike keyboards, many BCI systems do not display even the 26 letters of English at one time, let alone all the symbols in more complex systems. Using language models to make character-level predictions, therefore, can greatly speed up BCI typing (Ghosh and Kristensson, 2017). While most existing BCI systems employ character n-gram models or no LM at all, this paper adapts several wordpiece-level Transformer LMs to make character predictions and evaluates them on typing tasks. GPT-2 fares best on clean text, but different LMs react differently to noisy histories. We further analyze the effect of character positions in a word and context lengths.
Digital Editions as Distant Supervision for Layout Analysis of Printed Books
Dec 23, 2021
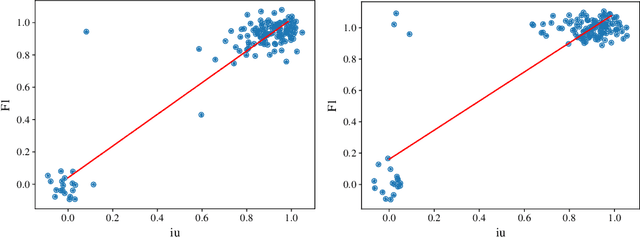
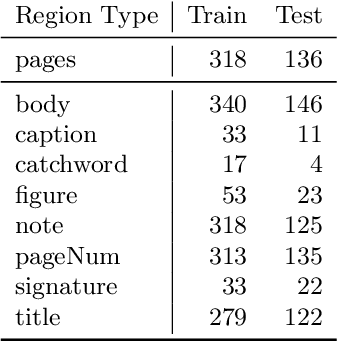
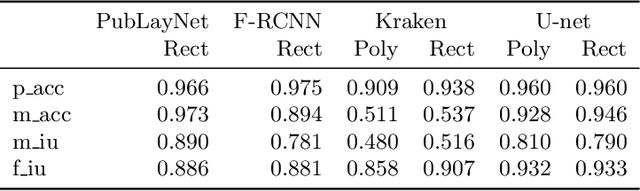
Archivists, textual scholars, and historians often produce digital editions of historical documents. Using markup schemes such as those of the Text Encoding Initiative and EpiDoc, these digital editions often record documents' semantic regions (such as notes and figures) and physical features (such as page and line breaks) as well as transcribing their textual content. We describe methods for exploiting this semantic markup as distant supervision for training and evaluating layout analysis models. In experiments with several model architectures on the half-million pages of the Deutsches Textarchiv (DTA), we find a high correlation of these region-level evaluation methods with pixel-level and word-level metrics. We discuss the possibilities for improving accuracy with self-training and the ability of models trained on the DTA to generalize to other historical printed books.
Contrastive Training for Models of Information Cascades
Dec 11, 2018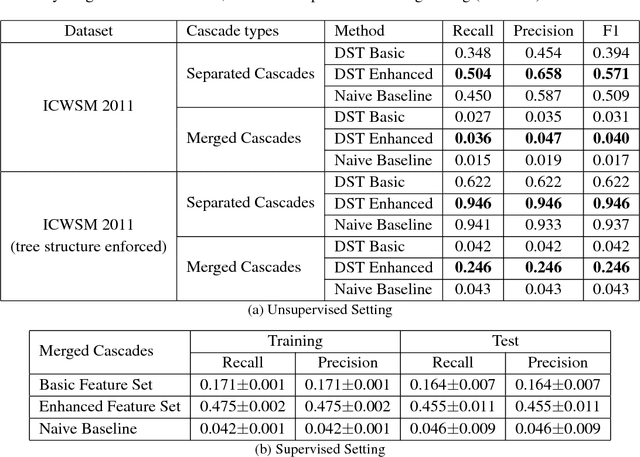
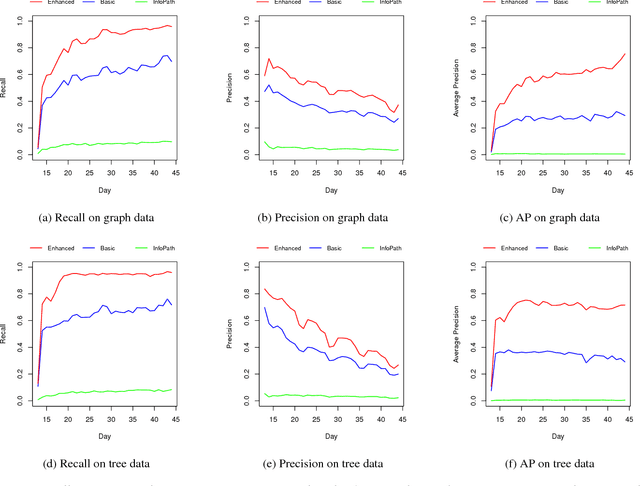
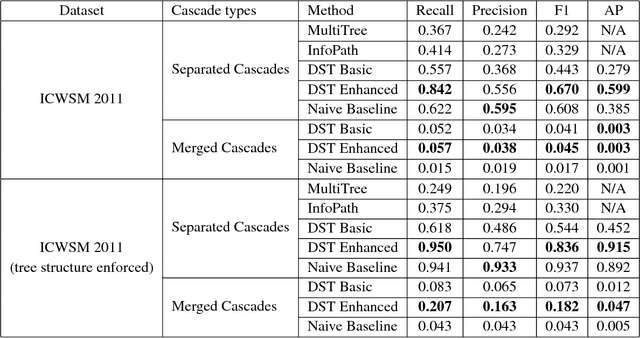
This paper proposes a model of information cascades as directed spanning trees (DSTs) over observed documents. In addition, we propose a contrastive training procedure that exploits partial temporal ordering of node infections in lieu of labeled training links. This combination of model and unsupervised training makes it possible to improve on models that use infection times alone and to exploit arbitrary features of the nodes and of the text content of messages in information cascades. With only basic node and time lag features similar to previous models, the DST model achieves performance with unsupervised training comparable to strong baselines on a blog network inference task. Unsupervised training with additional content features achieves significantly better results, reaching half the accuracy of a fully supervised model.
Multilingual Topic Models
Dec 18, 2017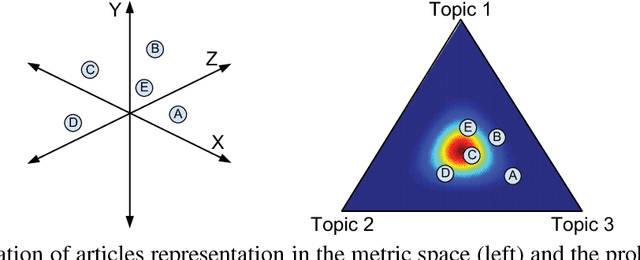
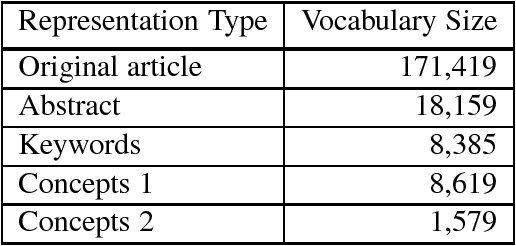
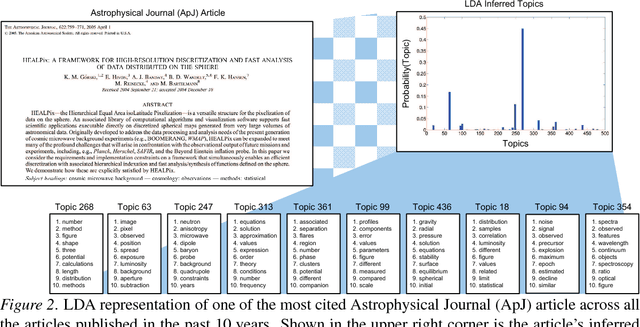
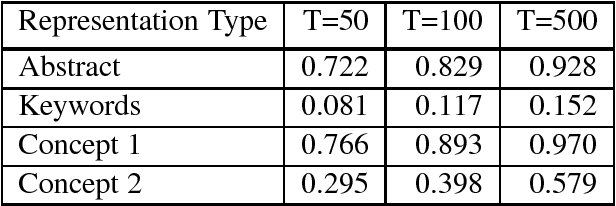
Scientific publications have evolved several features for mitigating vocabulary mismatch when indexing, retrieving, and computing similarity between articles. These mitigation strategies range from simply focusing on high-value article sections, such as titles and abstracts, to assigning keywords, often from controlled vocabularies, either manually or through automatic annotation. Various document representation schemes possess different cost-benefit tradeoffs. In this paper, we propose to model different representations of the same article as translations of each other, all generated from a common latent representation in a multilingual topic model. We start with a methodological overview on latent variable models for parallel document representations that could be used across many information science tasks. We then show how solving the inference problem of mapping diverse representations into a shared topic space allows us to evaluate representations based on how topically similar they are to the original article. In addition, our proposed approach provides means to discover where different concept vocabularies require improvement.
Inference by Minimizing Size, Divergence, or their Sum
Mar 15, 2012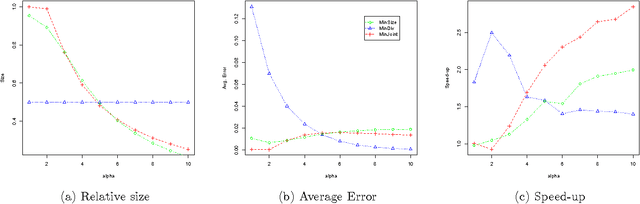

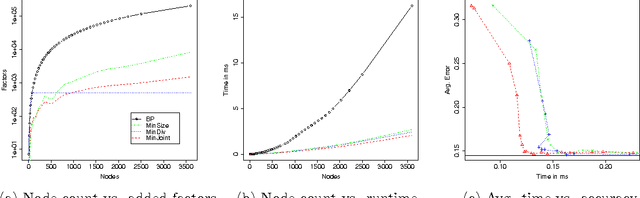
We speed up marginal inference by ignoring factors that do not significantly contribute to overall accuracy. In order to pick a suitable subset of factors to ignore, we propose three schemes: minimizing the number of model factors under a bound on the KL divergence between pruned and full models; minimizing the KL divergence under a bound on factor count; and minimizing the weighted sum of KL divergence and factor count. All three problems are solved using an approximation of the KL divergence than can be calculated in terms of marginals computed on a simple seed graph. Applied to synthetic image denoising and to three different types of NLP parsing models, this technique performs marginal inference up to 11 times faster than loopy BP, with graph sizes reduced up to 98%-at comparable error in marginals and parsing accuracy. We also show that minimizing the weighted sum of divergence and size is substantially faster than minimizing either of the other objectives based on the approximation to divergence presented here.