 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Page-Level Assessment of Handwritten Text Recognition
Jan 14, 2023The evaluation of Handwritten Text Recognition (HTR) systems has traditionally used metrics based on the edit distance between HTR and ground truth (GT) transcripts, at both the character and word levels. This is very adequate when the experimental protocol assumes that both GT and HTR text lines are the same, which allows edit distances to be independently computed to each given line. Driven by recent advances in pattern recognition, HTR systems increasingly face the end-to-end page-level transcription of a document, where the precision of locating the different text lines and their corresponding reading order (RO) play a key role. In such a case, the standard metrics do not take into account the inconsistencies that might appear. In this paper, the problem of evaluating HTR systems at the page level is introduced in detail. We analyze the convenience of using a two-fold evaluation, where the transcription accuracy and the RO goodness are considered separately. Different alternatives are proposed, analyzed and empirically compared both through partially simulated and through real, full end-to-end experiments. Results support the validity of the proposed two-fold evaluation approach. An important conclusion is that such an evaluation can be adequately achieved by just two simple and well-known metrics: the Word Error Rate, that takes transcription sequentiality into account, and the here re-formulated Bag of Words Word Error Rate, that ignores order. While the latter directly and very accurately assess intrinsic word recognition errors, the difference between both metrics gracefully correlates with the Spearman's Foot Rule Distance, a metric which explicitly measures RO errors associated with layout analysis flaws.
Open Set Classification of Untranscribed Handwritten Documents
Jun 20, 2022

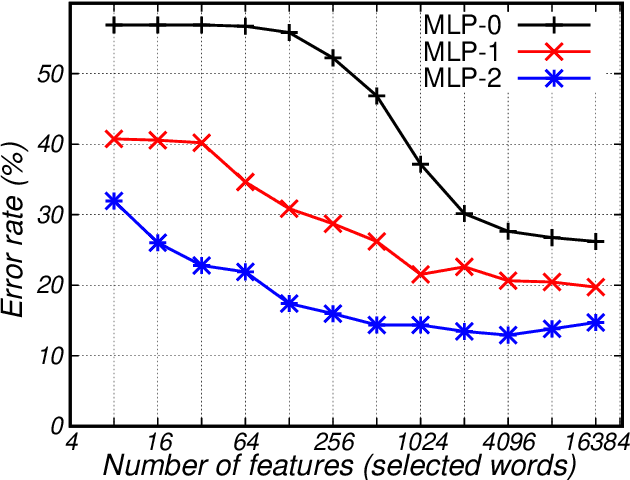
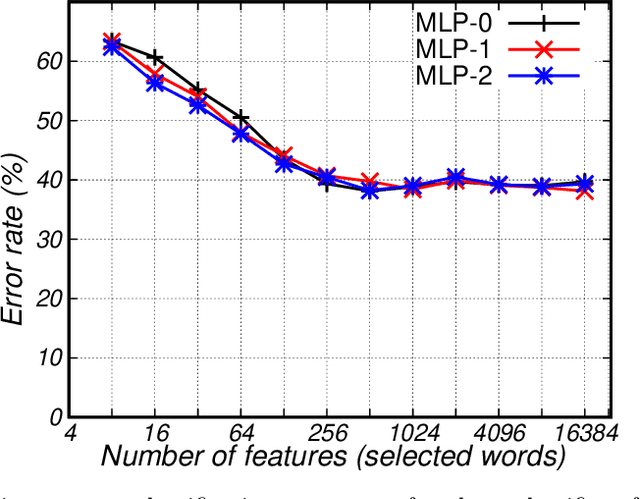
Huge amounts of digital page images of important manuscripts are preserved in archives worldwide. The amounts are so large that it is generally unfeasible for archivists to adequately tag most of the documents with the required metadata so as to low proper organization of the archives and effective exploration by scholars and the general public. The class or ``typology'' of a document is perhaps the most important tag to be included in the metadata. The technical problem is one of automatic classification of documents, each consisting of a set of untranscribed handwritten text images, by the textual contents of the images. The approach considered is based on ``probabilistic indexing'', a relatively novel technology which allows to effectively represent the intrinsic word-level uncertainty exhibited by handwritten text images. We assess the performance of this approach on a large collection of complex notarial manuscripts from the Spanish Archivo Host\'orico Provincial de C\'adiz, with promising results.
Digital Editions as Distant Supervision for Layout Analysis of Printed Books
Dec 23, 2021
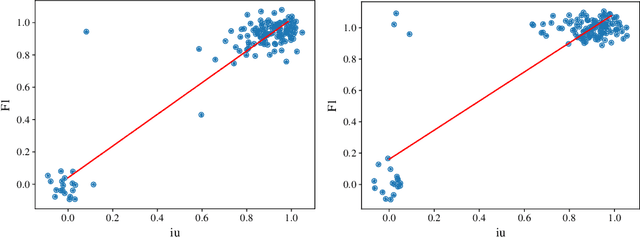
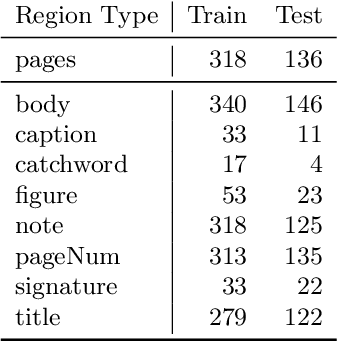
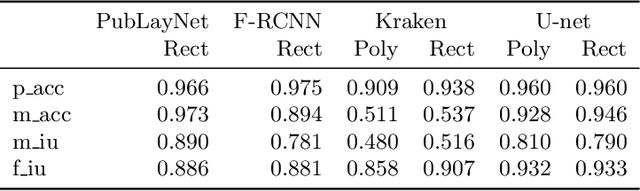
Archivists, textual scholars, and historians often produce digital editions of historical documents. Using markup schemes such as those of the Text Encoding Initiative and EpiDoc, these digital editions often record documents' semantic regions (such as notes and figures) and physical features (such as page and line breaks) as well as transcribing their textual content. We describe methods for exploiting this semantic markup as distant supervision for training and evaluating layout analysis models. In experiments with several model architectures on the half-million pages of the Deutsches Textarchiv (DTA), we find a high correlation of these region-level evaluation methods with pixel-level and word-level metrics. We discuss the possibilities for improving accuracy with self-training and the ability of models trained on the DTA to generalize to other historical printed books.
ICDAR 2021 Competition on Components Segmentation Task of Document Photos
Jul 09, 2021


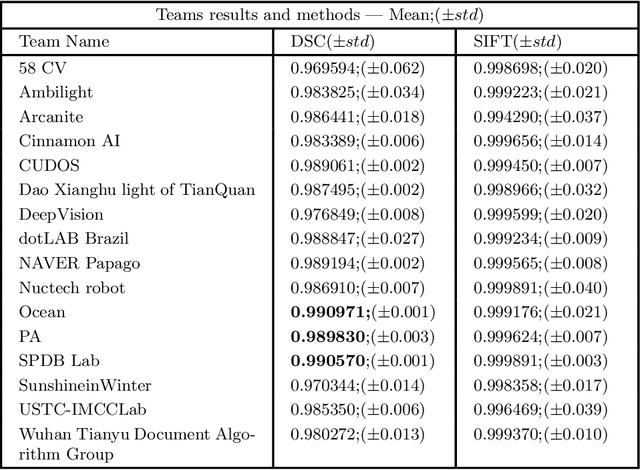
This paper describes the short-term competition on the Components Segmentation Task of Document Photos that was prepared in the context of the 16th International Conference on Document Analysis and Recognition (ICDAR 2021). This competition aims to bring together researchers working in the field of identification document image processing and provides them a suitable benchmark to compare their techniques on the component segmentation task of document images. Three challenge tasks were proposed entailing different segmentation assignments to be performed on a provided dataset. The collected data are from several types of Brazilian ID documents, whose personal information was conveniently replaced. There were 16 participants whose results obtained for some or all the three tasks show different rates for the adopted metrics, like Dice Similarity Coefficient ranging from 0.06 to 0.99. Different Deep Learning models were applied by the entrants with diverse strategies to achieve the best results in each of the tasks. Obtained results show that the currently applied methods for solving one of the proposed tasks (document boundary detection) are already well established. However, for the other two challenge tasks (text zone and handwritten sign detection) research and development of more robust approaches are still required to achieve acceptable results.