 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Page-Level Assessment of Handwritten Text Recognition
Jan 14, 2023The evaluation of Handwritten Text Recognition (HTR) systems has traditionally used metrics based on the edit distance between HTR and ground truth (GT) transcripts, at both the character and word levels. This is very adequate when the experimental protocol assumes that both GT and HTR text lines are the same, which allows edit distances to be independently computed to each given line. Driven by recent advances in pattern recognition, HTR systems increasingly face the end-to-end page-level transcription of a document, where the precision of locating the different text lines and their corresponding reading order (RO) play a key role. In such a case, the standard metrics do not take into account the inconsistencies that might appear. In this paper, the problem of evaluating HTR systems at the page level is introduced in detail. We analyze the convenience of using a two-fold evaluation, where the transcription accuracy and the RO goodness are considered separately. Different alternatives are proposed, analyzed and empirically compared both through partially simulated and through real, full end-to-end experiments. Results support the validity of the proposed two-fold evaluation approach. An important conclusion is that such an evaluation can be adequately achieved by just two simple and well-known metrics: the Word Error Rate, that takes transcription sequentiality into account, and the here re-formulated Bag of Words Word Error Rate, that ignores order. While the latter directly and very accurately assess intrinsic word recognition errors, the difference between both metrics gracefully correlates with the Spearman's Foot Rule Distance, a metric which explicitly measures RO errors associated with layout analysis flaws.
Open Set Classification of Untranscribed Handwritten Documents
Jun 20, 2022

Huge amounts of digital page images of important manuscripts are preserved in archives worldwide. The amounts are so large that it is generally unfeasible for archivists to adequately tag most of the documents with the required metadata so as to low proper organization of the archives and effective exploration by scholars and the general public. The class or ``typology'' of a document is perhaps the most important tag to be included in the metadata. The technical problem is one of automatic classification of documents, each consisting of a set of untranscribed handwritten text images, by the textual contents of the images. The approach considered is based on ``probabilistic indexing'', a relatively novel technology which allows to effectively represent the intrinsic word-level uncertainty exhibited by handwritten text images. We assess the performance of this approach on a large collection of complex notarial manuscripts from the Spanish Archivo Host\'orico Provincial de C\'adiz, with promising results.
Evaluation of a Region Proposal Architecture for Multi-task Document Layout Analysis
Jun 22, 2021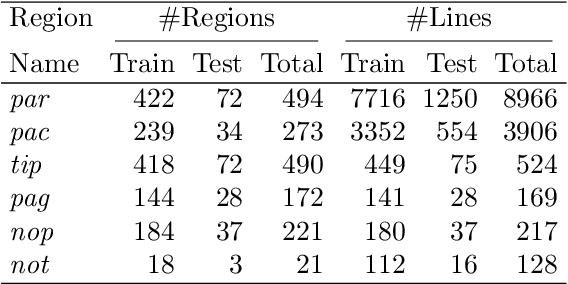
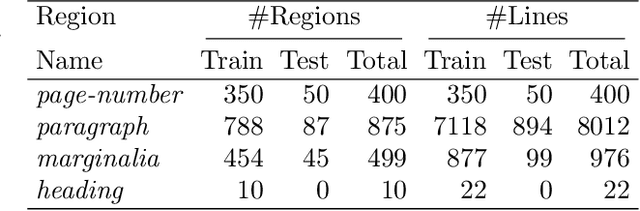


Automatically recognizing the layout of handwritten documents is an important step towards useful extraction of information from those documents. The most common application is to feed downstream applications such as automatic text recognition and keyword spotting; however, the recognition of the layout also helps to establish relationships between elements in the document which allows to enrich the information that can be extracted. Most of the modern document layout analysis systems are designed to address only one part of the document layout problem, namely: baseline detection or region segmentation. In contrast, we evaluate the effectiveness of the Mask-RCNN architecture to address the problem of baseline detection and region segmentation in an integrated manner. We present experimental results on two handwritten text datasets and one handwritten music dataset. The analyzed architecture yields promising results, outperforming state-of-the-art techniques in all three datasets.