 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligned Music Notation and Lyrics Transcription
Dec 05, 2024The digitization of vocal music scores presents unique challenges that go beyond traditional Optical Music Recognition (OMR) and Optical Character Recognition (OCR), as it necessitates preserving the critical alignment between music notation and lyrics. This alignment is essential for proper interpretation and processing in practical applications. This paper introduces and formalizes, for the first time, the Aligned Music Notation and Lyrics Transcription (AMNLT) challenge, which addresses the complete transcription of vocal scores by jointly considering music symbols, lyrics, and their synchronization. We analyze different approaches to address this challenge, ranging from traditional divide-and-conquer methods that handle music and lyrics separately, to novel end-to-end solutions including direct transcription, unfolding mechanisms, and language modeling. To evaluate these methods, we introduce four datasets of Gregorian chants, comprising both real and synthetic sources, along with custom metrics specifically designed to assess both transcription and alignment accuracy. Our experimental results demonstrate that end-to-end approaches generally outperform heuristic methods in the alignment challenge, with language models showing particular promise in scenarios where sufficient training data is available. This work establishes the first comprehensive framework for AMNLT, providing both theoretical foundations and practical solutions for preserving and digitizing vocal music heritage.
Sheet Music Transformer: End-To-End Optical Music Recognition Beyond Monophonic Transcription
Feb 12, 2024State-of-the-art end-to-end Optical Music Recognition (OMR) has, to date, primarily been carried out using monophonic transcription techniques to handle complex score layouts, such as polyphony, often by resorting to simplifications or specific adaptations. Despite their efficacy, these approaches imply challenges related to scalability and limitations. This paper presents the Sheet Music Transformer, the first end-to-end OMR model designed to transcribe complex musical scores without relying solely on monophonic strategies. Our model employs a Transformer-based image-to-sequence framework that predicts score transcriptions in a standard digital music encoding format from input images. Our model has been tested on two polyphonic music datasets and has proven capable of handling these intricate music structures effectively. The experimental outcomes not only indicate the competence of the model, but also show that it is better than the state-of-the-art methods, thus contributing to advancements in end-to-end OMR transcription.
Image Transformation Sequence Retrieval with General Reinforcement Learning
Jul 13, 2023In this work, the novel Image Transformation Sequence Retrieval (ITSR) task is presented, in which a model must retrieve the sequence of transformations between two given images that act as source and target, respectively. Given certain characteristics of the challenge such as the multiplicity of a correct sequence or the correlation between consecutive steps of the process, we propose a solution to ITSR using a general model-based Reinforcement Learning such as Monte Carlo Tree Search (MCTS), which is combined with a deep neural network. Our experiments provide a benchmark in both synthetic and real domains, where the proposed approach is compared with supervised training. The results report that a model trained with MCTS is able to outperform its supervised counterpart in both the simplest and the most complex cases. Our work draws interesting conclusions about the nature of ITSR and its associated challenges.
End-to-End Page-Level Assessment of Handwritten Text Recognition
Jan 14, 2023The evaluation of Handwritten Text Recognition (HTR) systems has traditionally used metrics based on the edit distance between HTR and ground truth (GT) transcripts, at both the character and word levels. This is very adequate when the experimental protocol assumes that both GT and HTR text lines are the same, which allows edit distances to be independently computed to each given line. Driven by recent advances in pattern recognition, HTR systems increasingly face the end-to-end page-level transcription of a document, where the precision of locating the different text lines and their corresponding reading order (RO) play a key role. In such a case, the standard metrics do not take into account the inconsistencies that might appear. In this paper, the problem of evaluating HTR systems at the page level is introduced in detail. We analyze the convenience of using a two-fold evaluation, where the transcription accuracy and the RO goodness are considered separately. Different alternatives are proposed, analyzed and empirically compared both through partially simulated and through real, full end-to-end experiments. Results support the validity of the proposed two-fold evaluation approach. An important conclusion is that such an evaluation can be adequately achieved by just two simple and well-known metrics: the Word Error Rate, that takes transcription sequentiality into account, and the here re-formulated Bag of Words Word Error Rate, that ignores order. While the latter directly and very accurately assess intrinsic word recognition errors, the difference between both metrics gracefully correlates with the Spearman's Foot Rule Distance, a metric which explicitly measures RO errors associated with layout analysis flaws.
Region-based Layout Analysis of Music Score Images
Jan 11, 2022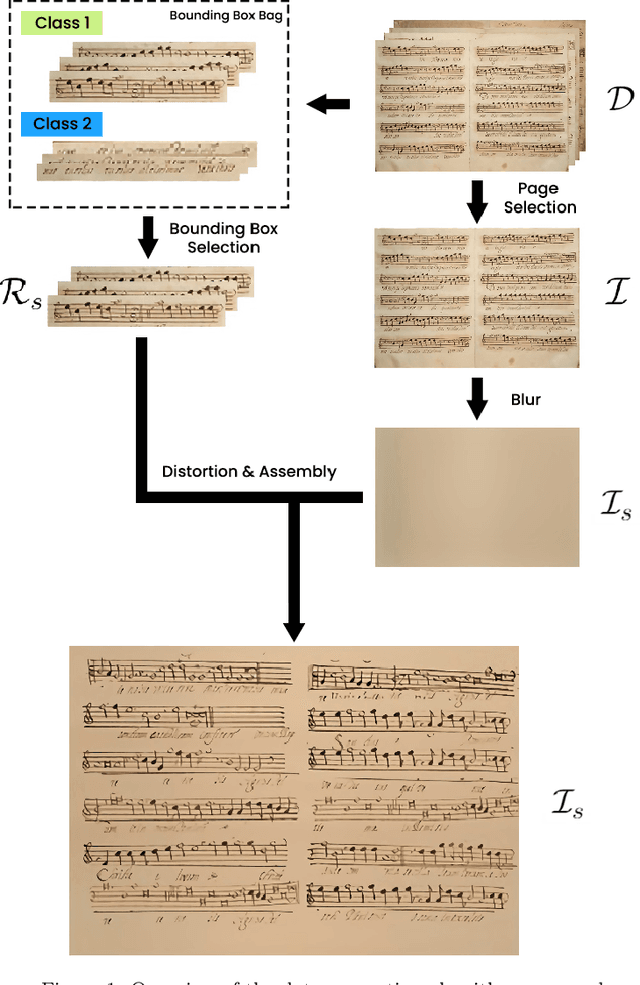
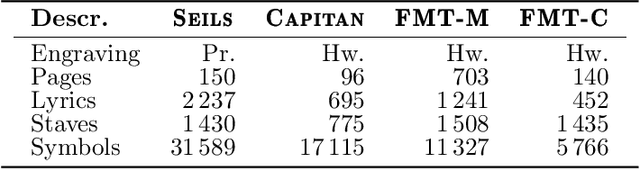

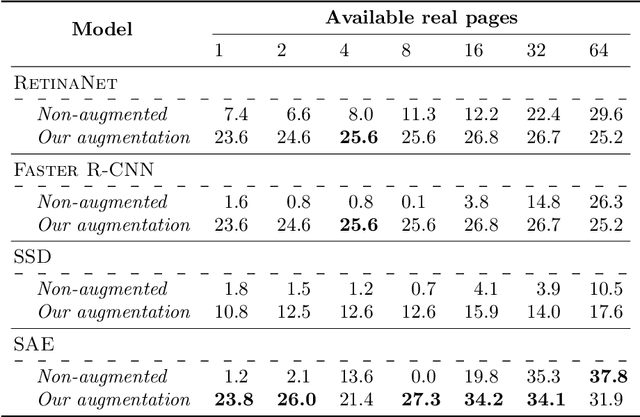
The Layout Analysis (LA) stage is of vital importance to the correct performance of an Optical Music Recognition (OMR) system. It identifies the regions of interest, such as staves or lyrics, which must then be processed in order to transcribe their content. Despite the existence of modern approaches based on deep learning, an exhaustive study of LA in OMR has not yet been carried out with regard to the precision of different models, their generalization to different domains or, more importantly, their impact on subsequent stages of the pipeline. This work focuses on filling this gap in literature by means of an experimental study of different neural architectures, music document types and evaluation scenarios. The need for training data has also led to a proposal for a new semi-synthetic data generation technique that enables the efficient applicability of LA approaches in real scenarios. Our results show that: (i) the choice of the model and its performance are crucial for the entire transcription process; (ii) the metrics commonly used to evaluate the LA stage do not always correlate with the final performance of the OMR system, and (iii) the proposed data-generation technique enables state-of-the-art results to be achieved with a limited set of labeled data.