 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaritime Search and Rescue Missions with Aerial Images: A Survey
Nov 12, 2024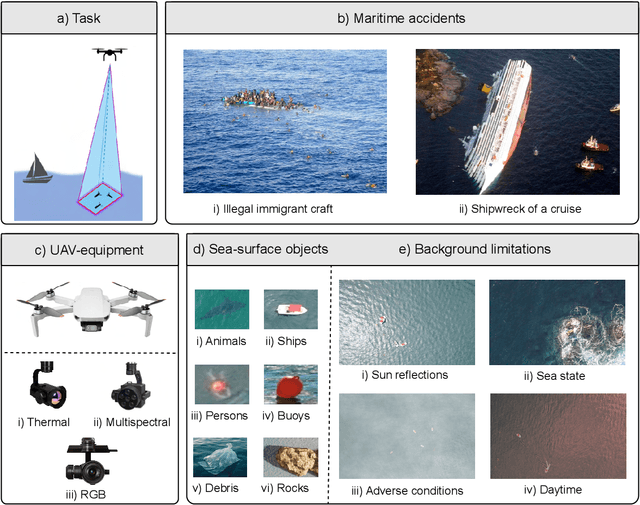
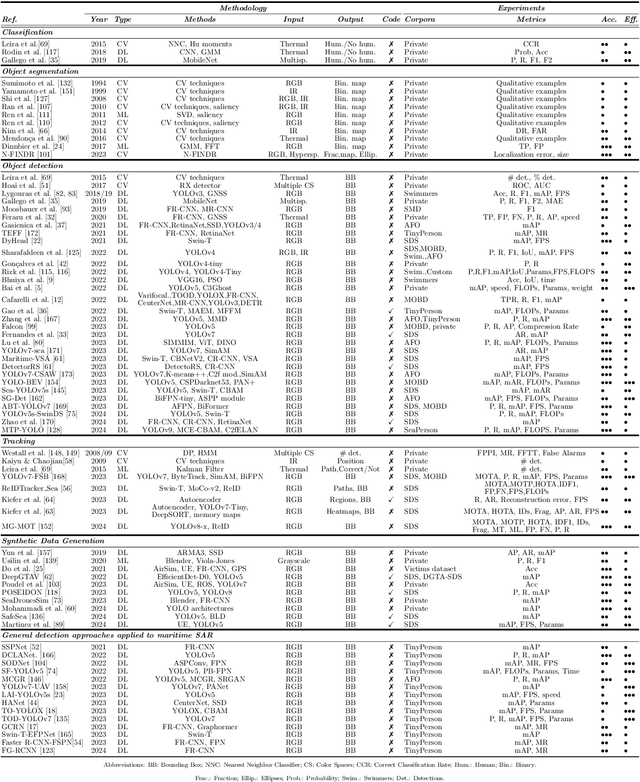
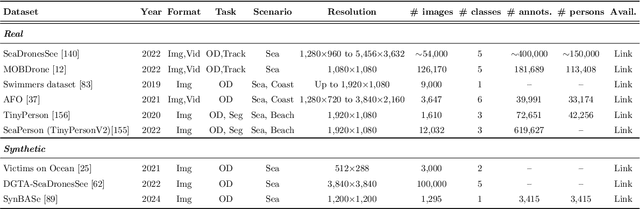
The speed of response by search and rescue teams at sea is of vital importance, as survival may depend on it. Recent technological advancements have led to the development of more efficient systems for locating individuals involved in a maritime incident, such as the use of Unmanned Aerial Vehicles (UAVs) equipped with cameras and other integrated sensors. Over the past decade, several researchers have contributed to the development of automatic systems capable of detecting people using aerial images, particularly by leveraging the advantages of deep learning. In this article, we provide a comprehensive review of the existing literature on this topic. We analyze the methods proposed to date, including both traditional techniques and more advanced approaches based on machine learning and neural networks. Additionally, we take into account the use of synthetic data to cover a wider range of scenarios without the need to deploy a team to collect data, which is one of the major obstacles for these systems. Overall, this paper situates the reader in the field of detecting people at sea using aerial images by quickly identifying the most suitable methodology for each scenario, as well as providing an in-depth discussion and direction for future trends.
Region-based Layout Analysis of Music Score Images
Jan 11, 2022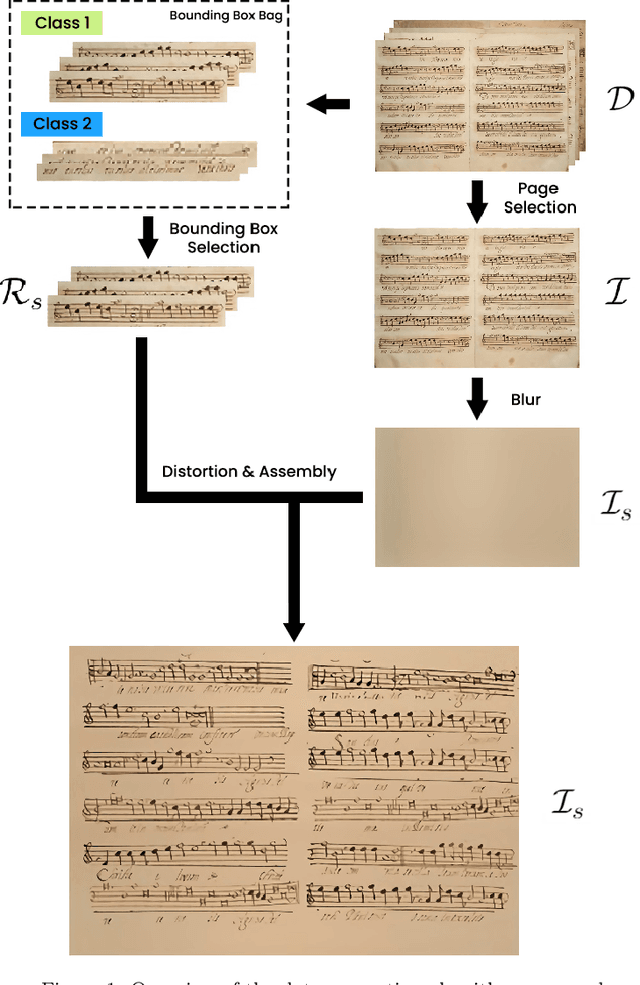
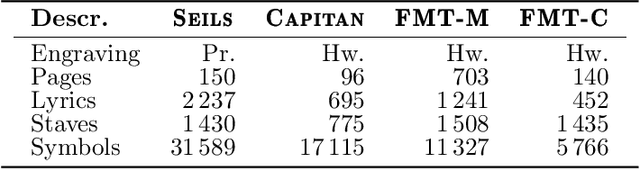

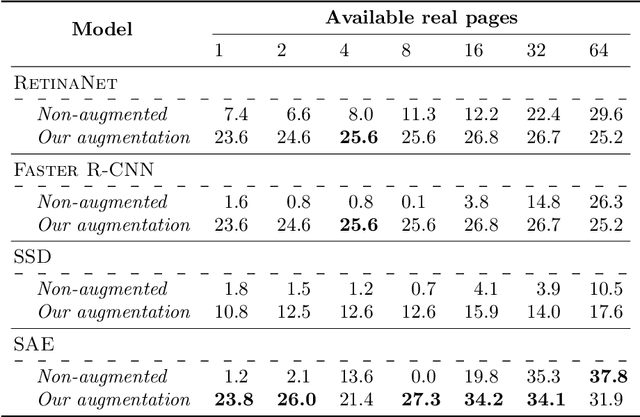
The Layout Analysis (LA) stage is of vital importance to the correct performance of an Optical Music Recognition (OMR) system. It identifies the regions of interest, such as staves or lyrics, which must then be processed in order to transcribe their content. Despite the existence of modern approaches based on deep learning, an exhaustive study of LA in OMR has not yet been carried out with regard to the precision of different models, their generalization to different domains or, more importantly, their impact on subsequent stages of the pipeline. This work focuses on filling this gap in literature by means of an experimental study of different neural architectures, music document types and evaluation scenarios. The need for training data has also led to a proposal for a new semi-synthetic data generation technique that enables the efficient applicability of LA approaches in real scenarios. Our results show that: (i) the choice of the model and its performance are crucial for the entire transcription process; (ii) the metrics commonly used to evaluate the LA stage do not always correlate with the final performance of the OMR system, and (iii) the proposed data-generation technique enables state-of-the-art results to be achieved with a limited set of labeled data.
Unsupervised Neural Domain Adaptation for Document Image Binarization
Dec 02, 2020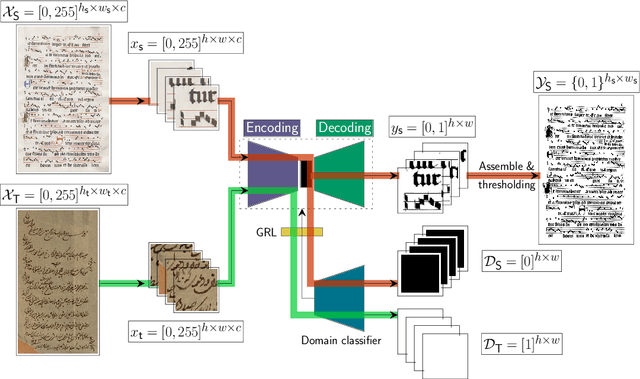
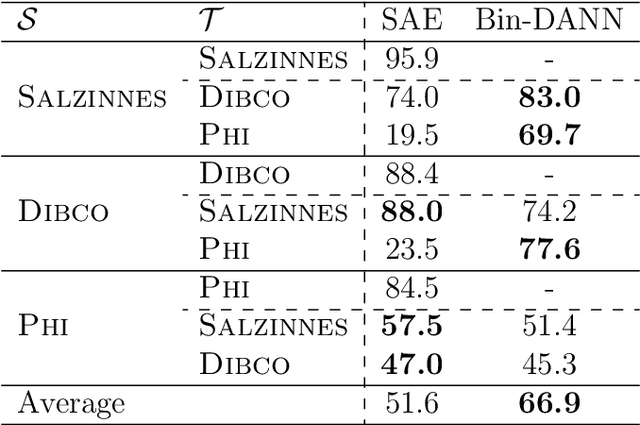
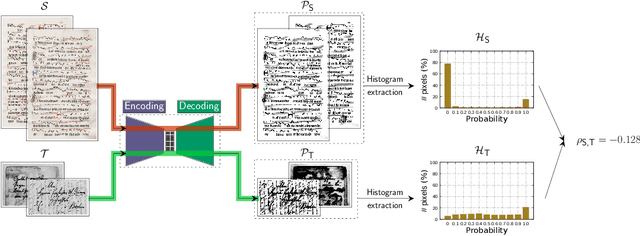
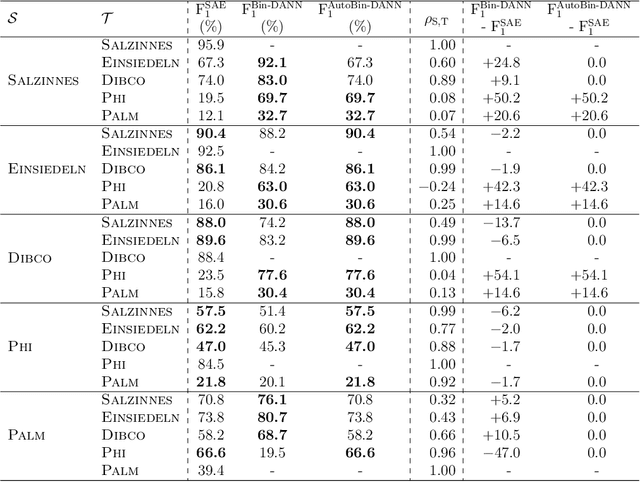
Binarization is a well-known image processing task, whose objective is to separate the foreground of an image from the background. One of the many tasks for which it is useful is that of preprocessing document images in order to identify relevant information, such as text or symbols. The wide variety of document types, typologies, alphabets, and formats makes binarization challenging, and there are, therefore, multiple proposals with which to solve this problem, from classical manually-adjusted methods, to more recent approaches based on machine learning. The latter techniques require a large amount of training data in order to obtain good results; however, labeling a portion of each existing collection of documents is not feasible in practice. This is a common problem in supervised learning, which can be addressed by using the so-called Domain Adaptation (DA) techniques. These techniques take advantage of the knowledge learned in one domain, for which labeled data are available, to apply it to other domains for which there are no labeled data. This paper proposes a method that combines neural networks and DA in order to carry out unsupervised document binarization. However, when both the source and target domains are very similar, this adaptation could be detrimental. Our methodology, therefore, first measures the similarity between domains in an innovative manner in order to determine whether or not it is appropriate to apply the adaptation process. The results reported in the experimentation, when evaluating up to 20 possible combinations among five different domains, show that our proposal successfully deals with the binarization of new document domains without the need for labeled data.