 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Neural Domain Adaptation for Document Image Binarization
Dec 02, 2020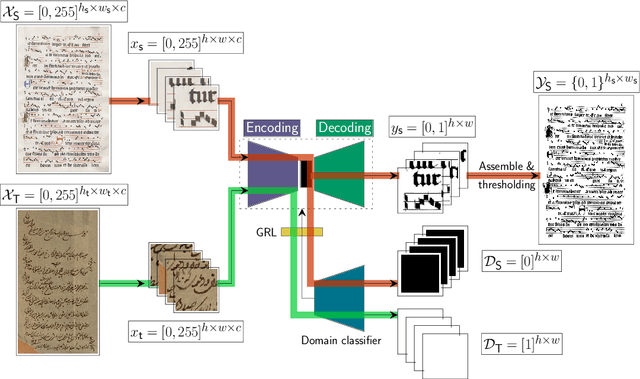
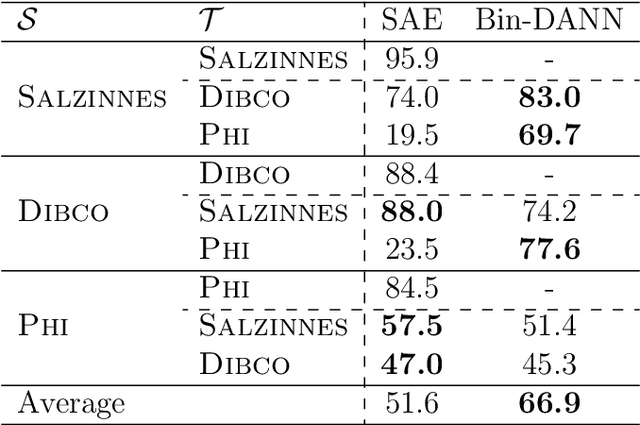
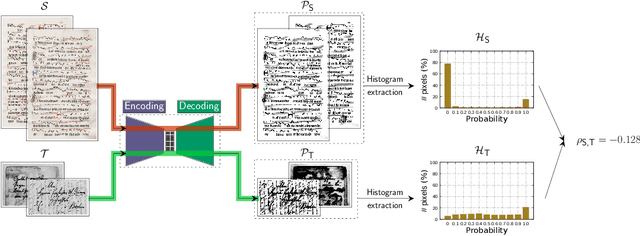
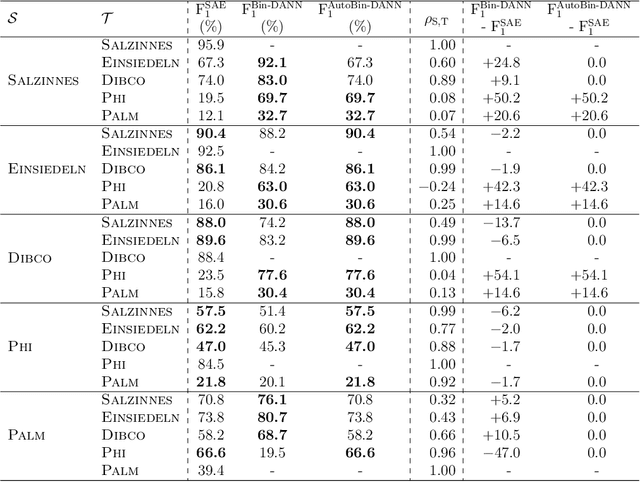
Binarization is a well-known image processing task, whose objective is to separate the foreground of an image from the background. One of the many tasks for which it is useful is that of preprocessing document images in order to identify relevant information, such as text or symbols. The wide variety of document types, typologies, alphabets, and formats makes binarization challenging, and there are, therefore, multiple proposals with which to solve this problem, from classical manually-adjusted methods, to more recent approaches based on machine learning. The latter techniques require a large amount of training data in order to obtain good results; however, labeling a portion of each existing collection of documents is not feasible in practice. This is a common problem in supervised learning, which can be addressed by using the so-called Domain Adaptation (DA) techniques. These techniques take advantage of the knowledge learned in one domain, for which labeled data are available, to apply it to other domains for which there are no labeled data. This paper proposes a method that combines neural networks and DA in order to carry out unsupervised document binarization. However, when both the source and target domains are very similar, this adaptation could be detrimental. Our methodology, therefore, first measures the similarity between domains in an innovative manner in order to determine whether or not it is appropriate to apply the adaptation process. The results reported in the experimentation, when evaluating up to 20 possible combinations among five different domains, show that our proposal successfully deals with the binarization of new document domains without the need for labeled data.
Incremental Unsupervised Domain-Adversarial Training of Neural Networks
Jan 13, 2020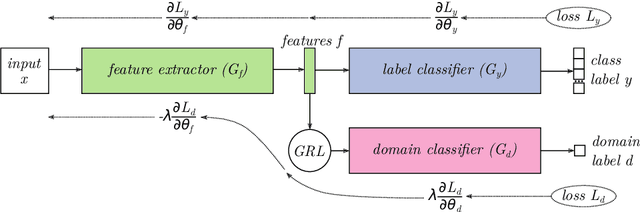
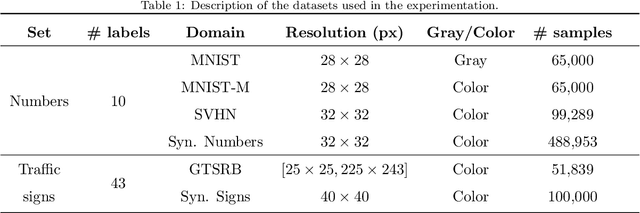
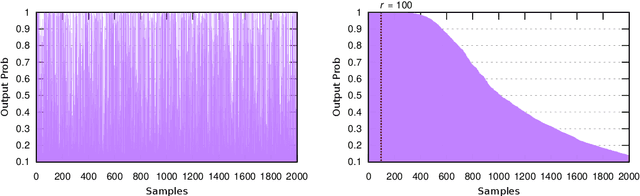

In the context of supervised statistical learning, it is typically assumed that the training set comes from the same distribution that draws the test samples. When this is not the case, the behavior of the learned model is unpredictable and becomes dependent upon the degree of similarity between the distribution of the training set and the distribution of the test set. One of the research topics that investigates this scenario is referred to as domain adaptation. Deep neural networks brought dramatic advances in pattern recognition and that is why there have been many attempts to provide good domain adaptation algorithms for these models. Here we take a different avenue and approach the problem from an incremental point of view, where the model is adapted to the new domain iteratively. We make use of an existing unsupervised domain-adaptation algorithm to identify the target samples on which there is greater confidence about their true label. The output of the model is analyzed in different ways to determine the candidate samples. The selected set is then added to the source training set by considering the labels provided by the network as ground truth, and the process is repeated until all target samples are labelled. Our results report a clear improvement with respect to the non-incremental case in several datasets, also outperforming other state-of-the-art domain adaptation algorithms.
A selectional auto-encoder approach for document image binarization
Sep 06, 2018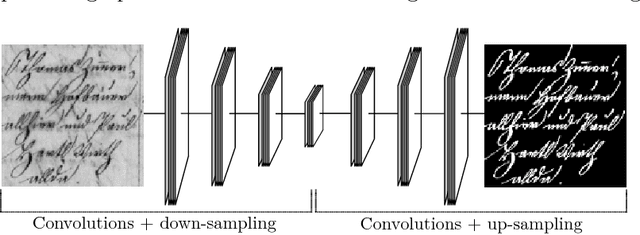
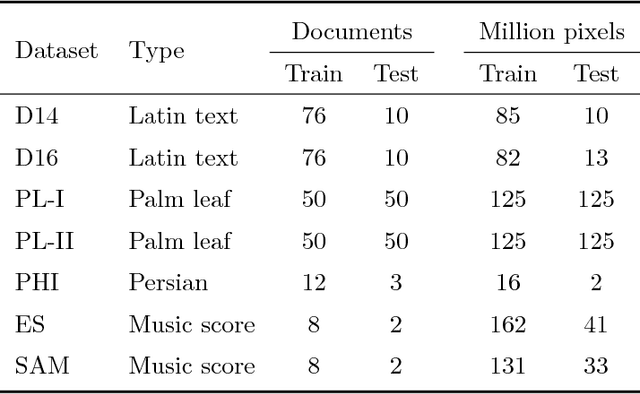

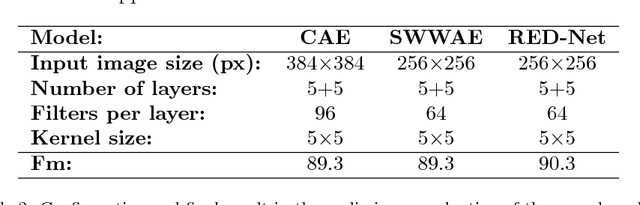
Binarization plays a key role in the automatic information retrieval from document images. This process is usually performed in the first stages of documents analysis systems, and serves as a basis for subsequent steps. Hence it has to be robust in order to allow the full analysis workflow to be successful. Several methods for document image binarization have been proposed so far, most of which are based on hand-crafted image processing strategies. Recently, Convolutional Neural Networks have shown an amazing performance in many disparate duties related to computer vision. In this paper we discuss the use of convolutional auto-encoders devoted to learning an end-to-end map from an input image to its selectional output, in which activations indicate the likelihood of pixels to be either foreground or background. Once trained, documents can therefore be binarized by parsing them through the model and applying a threshold. This approach has proven to outperform existing binarization strategies in a number of document domains.
MirBot: A collaborative object recognition system for smartphones using convolutional neural networks
Mar 24, 2018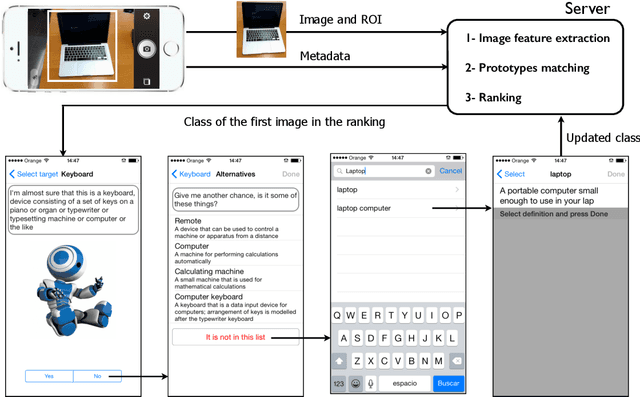
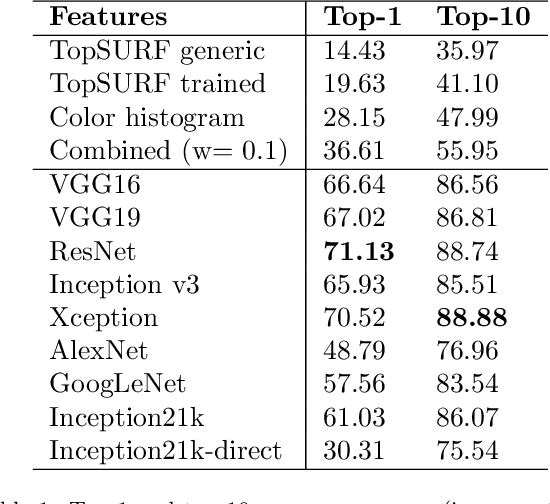
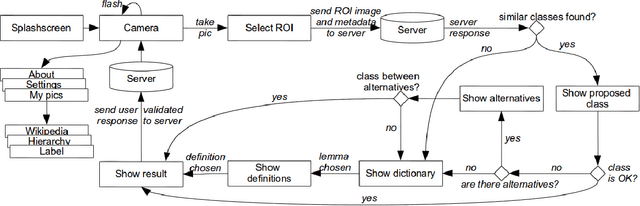
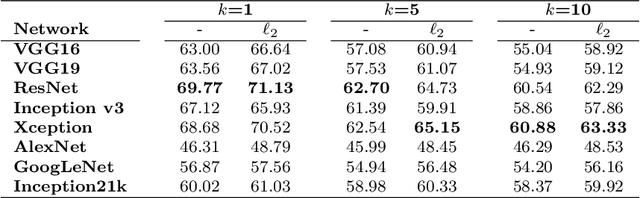
MirBot is a collaborative application for smartphones that allows users to perform object recognition. This app can be used to take a photograph of an object, select the region of interest and obtain the most likely class (dog, chair, etc.) by means of similarity search using features extracted from a convolutional neural network (CNN). The answers provided by the system can be validated by the user so as to improve the results for future queries. All the images are stored together with a series of metadata, thus enabling a multimodal incremental dataset labeled with synset identifiers from the WordNet ontology. This dataset grows continuously thanks to the users' feedback, and is publicly available for research. This work details the MirBot object recognition system, analyzes the statistics gathered after more than four years of usage, describes the image classification methodology, and performs an exhaustive evaluation using handcrafted features, convolutional neural codes and different transfer learning techniques. After comparing various models and transformation methods, the results show that the CNN features maintain the accuracy of MirBot constant over time, despite the increasing number of new classes. The app is freely available at the Apple and Google Play stores.