 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect content-based retrieval from music scores images
May 21, 2026The digitization of musical scores plays a crucial role in their preservation and accessibility, yet information retrieval still depends mainly on metadata searches, such as by title or composer. Content based search in music score images remains underexplored compared to text documents, despite its potential value for musicians, musicologists, and educators. This work contributes to the field by first studying which characteristics of a score are most relevant for search and by defining a systematic method to build query datasets from any annotated corpus. We also consider diverse methods for content-based search on music score images, ranging from transcription-based approaches relying on Optical Music Recognition (OMR), to a transcription-free Transformer model trained to recognize queries directly from score images, and a text-prompted Large Language Model. Our experiments evaluate these models on four corpora exhibiting diverse characteristics in terms of dataset size, image quality, and typesetting mechanisms. Overall, each method excels under different conditions: OMR-based pipelines achieve higher in-domain retrieval, whereas transcription-free models handle domain variability more effectively.
Zero-Shot Synthetic-to-Real Handwritten Text Recognition via Task Analogies
Apr 08, 2026Handwritten Text Recognition (HTR) models trained on synthetic handwriting often struggle to generalize to real text, and existing adaptation methods still require real samples from the target domain. In this work, we tackle the fully zero-shot synthetic-to-real generalization setting, where no real data from the target language is available. Our approach learns how model parameters change when moving from synthetic to real handwriting in one or more source languages and transfers this learned correction to new target languages. When using multiple sources, we rely on linguistic similarity to weigh their contrubition when combining them. Experiments across five languages and six architectures show consistent improvements over synthetic-only baselines and reveal that the transferred corrections benefit even languages unrelated to the sources.
Sheet Music Benchmark: Standardized Optical Music Recognition Evaluation
Jun 12, 2025



In this work, we introduce the Sheet Music Benchmark (SMB), a dataset of six hundred and eighty-five pages specifically designed to benchmark Optical Music Recognition (OMR) research. SMB encompasses a diverse array of musical textures, including monophony, pianoform, quartet, and others, all encoded in Common Western Modern Notation using the Humdrum **kern format. Alongside SMB, we introduce the OMR Normalized Edit Distance (OMR-NED), a new metric tailored explicitly for evaluating OMR performance. OMR-NED builds upon the widely-used Symbol Error Rate (SER), offering a fine-grained and detailed error analysis that covers individual musical elements such as note heads, beams, pitches, accidentals, and other critical notation features. The resulting numeric score provided by OMR-NED facilitates clear comparisons, enabling researchers and end-users alike to identify optimal OMR approaches. Our work thus addresses a long-standing gap in OMR evaluation, and we support our contributions with baseline experiments using standardized SMB dataset splits for training and assessing state-of-the-art methods.
Handwritten Text Recognition: A Survey
Feb 12, 2025



Handwritten Text Recognition (HTR) has become an essential field within pattern recognition and machine learning, with applications spanning historical document preservation to modern data entry and accessibility solutions. The complexity of HTR lies in the high variability of handwriting, which makes it challenging to develop robust recognition systems. This survey examines the evolution of HTR models, tracing their progression from early heuristic-based approaches to contemporary state-of-the-art neural models, which leverage deep learning techniques. The scope of the field has also expanded, with models initially capable of recognizing only word-level content progressing to recent end-to-end document-level approaches. Our paper categorizes existing work into two primary levels of recognition: (1) \emph{up to line-level}, encompassing word and line recognition, and (2) \emph{beyond line-level}, addressing paragraph- and document-level challenges. We provide a unified framework that examines research methodologies, recent advances in benchmarking, key datasets in the field, and a discussion of the results reported in the literature. Finally, we identify pressing research challenges and outline promising future directions, aiming to equip researchers and practitioners with a roadmap for advancing the field.
Aligned Music Notation and Lyrics Transcription
Dec 05, 2024The digitization of vocal music scores presents unique challenges that go beyond traditional Optical Music Recognition (OMR) and Optical Character Recognition (OCR), as it necessitates preserving the critical alignment between music notation and lyrics. This alignment is essential for proper interpretation and processing in practical applications. This paper introduces and formalizes, for the first time, the Aligned Music Notation and Lyrics Transcription (AMNLT) challenge, which addresses the complete transcription of vocal scores by jointly considering music symbols, lyrics, and their synchronization. We analyze different approaches to address this challenge, ranging from traditional divide-and-conquer methods that handle music and lyrics separately, to novel end-to-end solutions including direct transcription, unfolding mechanisms, and language modeling. To evaluate these methods, we introduce four datasets of Gregorian chants, comprising both real and synthetic sources, along with custom metrics specifically designed to assess both transcription and alignment accuracy. Our experimental results demonstrate that end-to-end approaches generally outperform heuristic methods in the alignment challenge, with language models showing particular promise in scenarios where sufficient training data is available. This work establishes the first comprehensive framework for AMNLT, providing both theoretical foundations and practical solutions for preserving and digitizing vocal music heritage.
On the Generalization of Handwritten Text Recognition Models
Nov 26, 2024



Recent advances in Handwritten Text Recognition (HTR) have led to significant reductions in transcription errors on standard benchmarks under the i.i.d. assumption, thus focusing on minimizing in-distribution (ID) errors. However, this assumption does not hold in real-world applications, which has motivated HTR research to explore Transfer Learning and Domain Adaptation techniques. In this work, we investigate the unaddressed limitations of HTR models in generalizing to out-of-distribution (OOD) data. We adopt the challenging setting of Domain Generalization, where models are expected to generalize to OOD data without any prior access. To this end, we analyze 336 OOD cases from eight state-of-the-art HTR models across seven widely used datasets, spanning five languages. Additionally, we study how HTR models leverage synthetic data to generalize. We reveal that the most significant factor for generalization lies in the textual divergence between domains, followed by visual divergence. We demonstrate that the error of HTR models in OOD scenarios can be reliably estimated, with discrepancies falling below 10 points in 70\% of cases. We identify the underlying limitations of HTR models, laying the foundation for future research to address this challenge.
Proceedings of the 6th International Workshop on Reading Music Systems
Nov 24, 2024The International Workshop on Reading Music Systems (WoRMS) is a workshop that tries to connect researchers who develop systems for reading music, such as in the field of Optical Music Recognition, with other researchers and practitioners that could benefit from such systems, like librarians or musicologists. The relevant topics of interest for the workshop include, but are not limited to: Music reading systems; Optical music recognition; Datasets and performance evaluation; Image processing on music scores; Writer identification; Authoring, editing, storing and presentation systems for music scores; Multi-modal systems; Novel input-methods for music to produce written music; Web-based Music Information Retrieval services; Applications and projects; Use-cases related to written music. These are the proceedings of the 6th International Workshop on Reading Music Systems, held Online on November 22nd 2024.
Maritime Search and Rescue Missions with Aerial Images: A Survey
Nov 12, 2024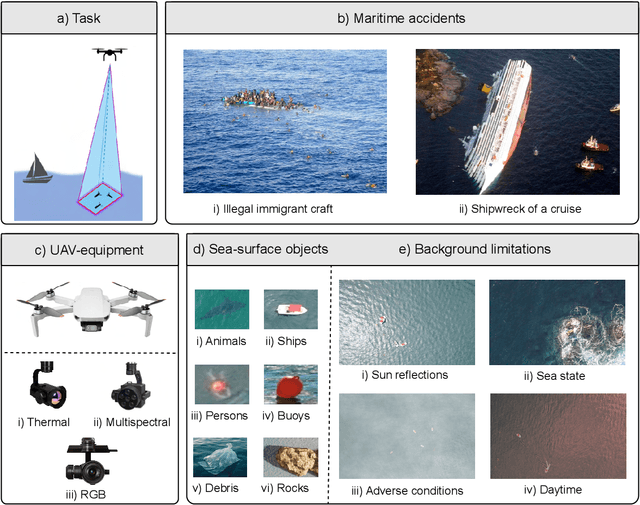
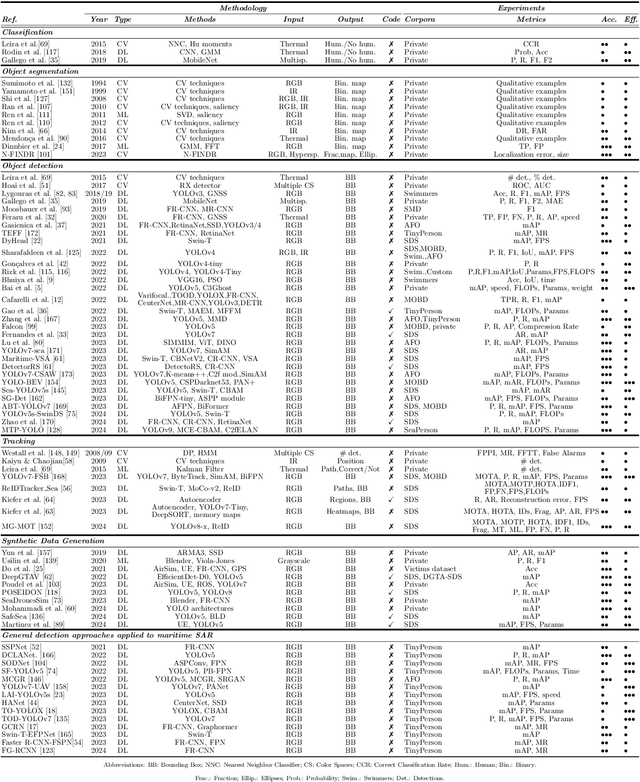
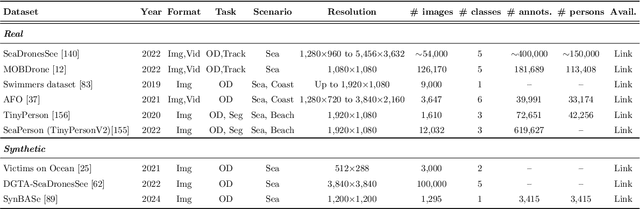
The speed of response by search and rescue teams at sea is of vital importance, as survival may depend on it. Recent technological advancements have led to the development of more efficient systems for locating individuals involved in a maritime incident, such as the use of Unmanned Aerial Vehicles (UAVs) equipped with cameras and other integrated sensors. Over the past decade, several researchers have contributed to the development of automatic systems capable of detecting people using aerial images, particularly by leveraging the advantages of deep learning. In this article, we provide a comprehensive review of the existing literature on this topic. We analyze the methods proposed to date, including both traditional techniques and more advanced approaches based on machine learning and neural networks. Additionally, we take into account the use of synthetic data to cover a wider range of scenarios without the need to deploy a team to collect data, which is one of the major obstacles for these systems. Overall, this paper situates the reader in the field of detecting people at sea using aerial images by quickly identifying the most suitable methodology for each scenario, as well as providing an in-depth discussion and direction for future trends.
Self-Supervised Learning for Text Recognition: A Critical Survey
Jul 29, 2024Text Recognition (TR) refers to the research area that focuses on retrieving textual information from images, a topic that has seen significant advancements in the last decade due to the use of Deep Neural Networks (DNN). However, these solutions often necessitate vast amounts of manually labeled or synthetic data. Addressing this challenge, Self-Supervised Learning (SSL) has gained attention by utilizing large datasets of unlabeled data to train DNN, thereby generating meaningful and robust representations. Although SSL was initially overlooked in TR because of its unique characteristics, recent years have witnessed a surge in the development of SSL methods specifically for this field. This rapid development, however, has led to many methods being explored independently, without taking previous efforts in methodology or comparison into account, thereby hindering progress in the field of research. This paper, therefore, seeks to consolidate the use of SSL in the field of TR, offering a critical and comprehensive overview of the current state of the art. We will review and analyze the existing methods, compare their results, and highlight inconsistencies in the current literature. This thorough analysis aims to provide general insights into the field, propose standardizations, identify new research directions, and foster its proper development.
Align, Minimize and Diversify: A Source-Free Unsupervised Domain Adaptation Method for Handwritten Text Recognition
Apr 28, 2024This paper serves to introduce the Align, Minimize and Diversify (AMD) method, a Source-Free Unsupervised Domain Adaptation approach for Handwritten Text Recognition (HTR). This framework decouples the adaptation process from the source data, thus not only sidestepping the resource-intensive retraining process but also making it possible to leverage the wealth of pre-trained knowledge encoded in modern Deep Learning architectures. Our method explicitly eliminates the need to revisit the source data during adaptation by incorporating three distinct regularization terms: the Align term, which reduces the feature distribution discrepancy between source and target data, ensuring the transferability of the pre-trained representation; the Minimize term, which encourages the model to make assertive predictions, pushing the outputs towards one-hot-like distributions in order to minimize prediction uncertainty, and finally, the Diversify term, which safeguards against the degeneracy in predictions by promoting varied and distinctive sequences throughout the target data, preventing informational collapse. Experimental results from several benchmarks demonstrated the effectiveness and robustness of AMD, showing it to be competitive and often outperforming DA methods in HTR.