 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign, Minimize and Diversify: A Source-Free Unsupervised Domain Adaptation Method for Handwritten Text Recognition
Apr 28, 2024This paper serves to introduce the Align, Minimize and Diversify (AMD) method, a Source-Free Unsupervised Domain Adaptation approach for Handwritten Text Recognition (HTR). This framework decouples the adaptation process from the source data, thus not only sidestepping the resource-intensive retraining process but also making it possible to leverage the wealth of pre-trained knowledge encoded in modern Deep Learning architectures. Our method explicitly eliminates the need to revisit the source data during adaptation by incorporating three distinct regularization terms: the Align term, which reduces the feature distribution discrepancy between source and target data, ensuring the transferability of the pre-trained representation; the Minimize term, which encourages the model to make assertive predictions, pushing the outputs towards one-hot-like distributions in order to minimize prediction uncertainty, and finally, the Diversify term, which safeguards against the degeneracy in predictions by promoting varied and distinctive sequences throughout the target data, preventing informational collapse. Experimental results from several benchmarks demonstrated the effectiveness and robustness of AMD, showing it to be competitive and often outperforming DA methods in HTR.
Late multimodal fusion for image and audio music transcription
Apr 06, 2022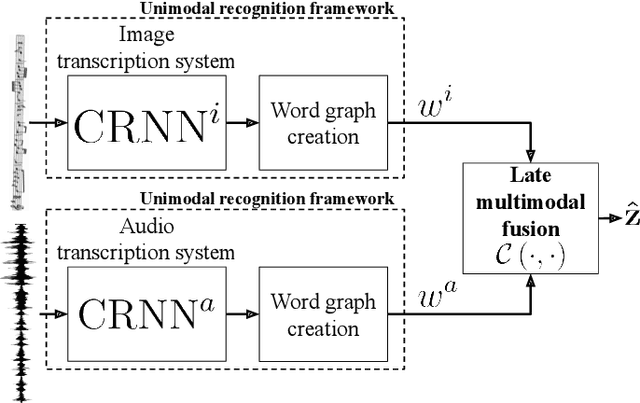
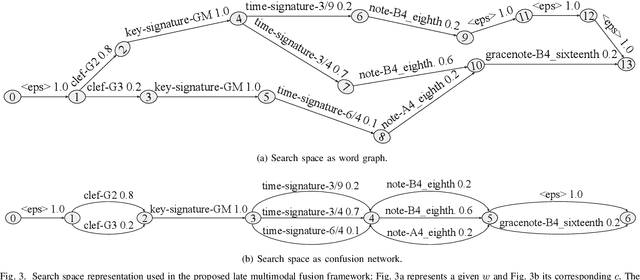
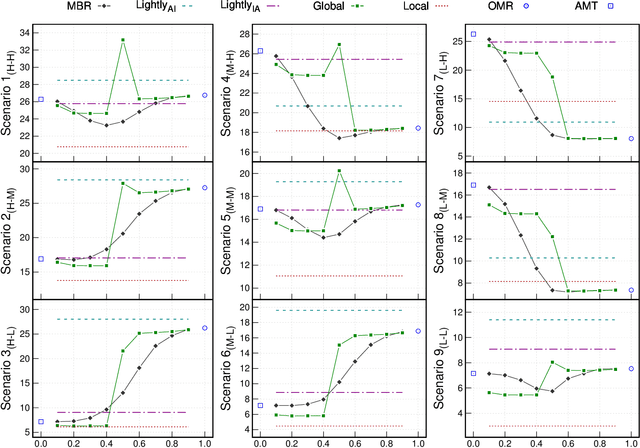

Music transcription, which deals with the conversion of music sources into a structured digital format, is a key problem for Music Information Retrieval (MIR). When addressing this challenge in computational terms, the MIR community follows two lines of research: music documents, which is the case of Optical Music Recognition (OMR), or audio recordings, which is the case of Automatic Music Transcription (AMT). The different nature of the aforementioned input data has conditioned these fields to develop modality-specific frameworks. However, their recent definition in terms of sequence labeling tasks leads to a common output representation, which enables research on a combined paradigm. In this respect, multimodal image and audio music transcription comprises the challenge of effectively combining the information conveyed by image and audio modalities. In this work, we explore this question at a late-fusion level: we study four combination approaches in order to merge, for the first time, the hypotheses regarding end-to-end OMR and AMT systems in a lattice-based search space. The results obtained for a series of performance scenarios -- in which the corresponding single-modality models yield different error rates -- showed interesting benefits of these approaches. In addition, two of the four strategies considered significantly improve the corresponding unimodal standard recognition frameworks.