 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Synthetic-to-Real Handwritten Text Recognition via Task Analogies
Apr 08, 2026Handwritten Text Recognition (HTR) models trained on synthetic handwriting often struggle to generalize to real text, and existing adaptation methods still require real samples from the target domain. In this work, we tackle the fully zero-shot synthetic-to-real generalization setting, where no real data from the target language is available. Our approach learns how model parameters change when moving from synthetic to real handwriting in one or more source languages and transfers this learned correction to new target languages. When using multiple sources, we rely on linguistic similarity to weigh their contrubition when combining them. Experiments across five languages and six architectures show consistent improvements over synthetic-only baselines and reveal that the transferred corrections benefit even languages unrelated to the sources.
Handwritten Text Recognition: A Survey
Feb 12, 2025



Handwritten Text Recognition (HTR) has become an essential field within pattern recognition and machine learning, with applications spanning historical document preservation to modern data entry and accessibility solutions. The complexity of HTR lies in the high variability of handwriting, which makes it challenging to develop robust recognition systems. This survey examines the evolution of HTR models, tracing their progression from early heuristic-based approaches to contemporary state-of-the-art neural models, which leverage deep learning techniques. The scope of the field has also expanded, with models initially capable of recognizing only word-level content progressing to recent end-to-end document-level approaches. Our paper categorizes existing work into two primary levels of recognition: (1) \emph{up to line-level}, encompassing word and line recognition, and (2) \emph{beyond line-level}, addressing paragraph- and document-level challenges. We provide a unified framework that examines research methodologies, recent advances in benchmarking, key datasets in the field, and a discussion of the results reported in the literature. Finally, we identify pressing research challenges and outline promising future directions, aiming to equip researchers and practitioners with a roadmap for advancing the field.
On the Generalization of Handwritten Text Recognition Models
Nov 26, 2024



Recent advances in Handwritten Text Recognition (HTR) have led to significant reductions in transcription errors on standard benchmarks under the i.i.d. assumption, thus focusing on minimizing in-distribution (ID) errors. However, this assumption does not hold in real-world applications, which has motivated HTR research to explore Transfer Learning and Domain Adaptation techniques. In this work, we investigate the unaddressed limitations of HTR models in generalizing to out-of-distribution (OOD) data. We adopt the challenging setting of Domain Generalization, where models are expected to generalize to OOD data without any prior access. To this end, we analyze 336 OOD cases from eight state-of-the-art HTR models across seven widely used datasets, spanning five languages. Additionally, we study how HTR models leverage synthetic data to generalize. We reveal that the most significant factor for generalization lies in the textual divergence between domains, followed by visual divergence. We demonstrate that the error of HTR models in OOD scenarios can be reliably estimated, with discrepancies falling below 10 points in 70\% of cases. We identify the underlying limitations of HTR models, laying the foundation for future research to address this challenge.
Spatial Context-based Self-Supervised Learning for Handwritten Text Recognition
Apr 17, 2024



Handwritten Text Recognition (HTR) is a relevant problem in computer vision, and implies unique challenges owing to its inherent variability and the rich contextualization required for its interpretation. Despite the success of Self-Supervised Learning (SSL) in computer vision, its application to HTR has been rather scattered, leaving key SSL methodologies unexplored. This work focuses on one of them, namely Spatial Context-based SSL. We investigate how this family of approaches can be adapted and optimized for HTR and propose new workflows that leverage the unique features of handwritten text. Our experiments demonstrate that the methods considered lead to advancements in the state-of-the-art of SSL for HTR in a number of benchmark cases.
Region-based Layout Analysis of Music Score Images
Jan 11, 2022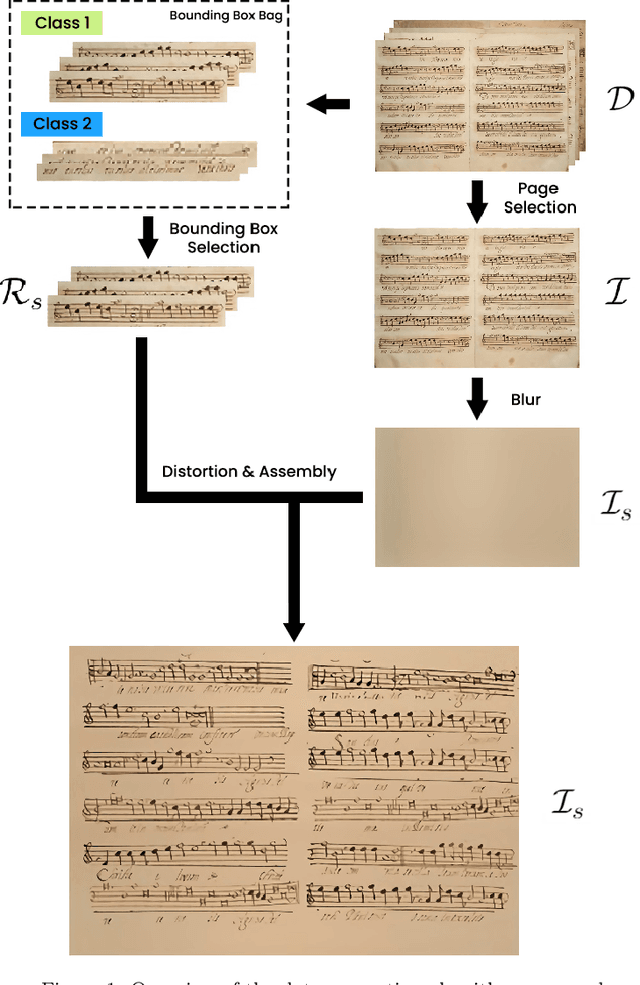
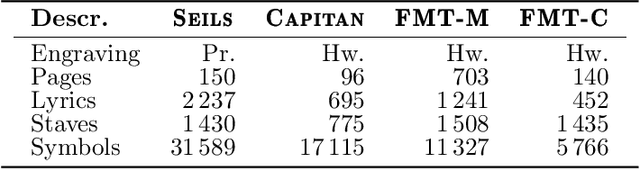

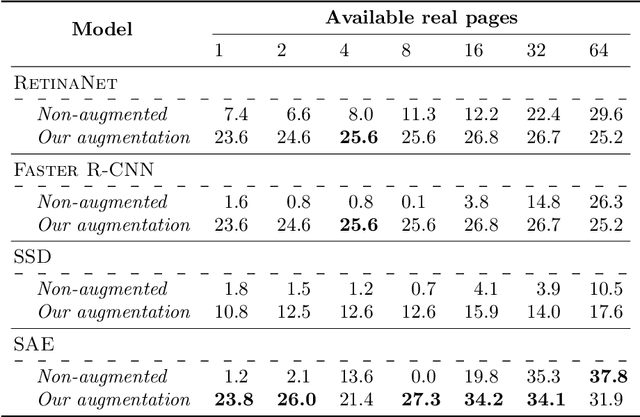
The Layout Analysis (LA) stage is of vital importance to the correct performance of an Optical Music Recognition (OMR) system. It identifies the regions of interest, such as staves or lyrics, which must then be processed in order to transcribe their content. Despite the existence of modern approaches based on deep learning, an exhaustive study of LA in OMR has not yet been carried out with regard to the precision of different models, their generalization to different domains or, more importantly, their impact on subsequent stages of the pipeline. This work focuses on filling this gap in literature by means of an experimental study of different neural architectures, music document types and evaluation scenarios. The need for training data has also led to a proposal for a new semi-synthetic data generation technique that enables the efficient applicability of LA approaches in real scenarios. Our results show that: (i) the choice of the model and its performance are crucial for the entire transcription process; (ii) the metrics commonly used to evaluate the LA stage do not always correlate with the final performance of the OMR system, and (iii) the proposed data-generation technique enables state-of-the-art results to be achieved with a limited set of labeled data.