 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesising Handwritten Music with GANs: A Comprehensive Evaluation of CycleWGAN, ProGAN, and DCGAN
Nov 25, 2024
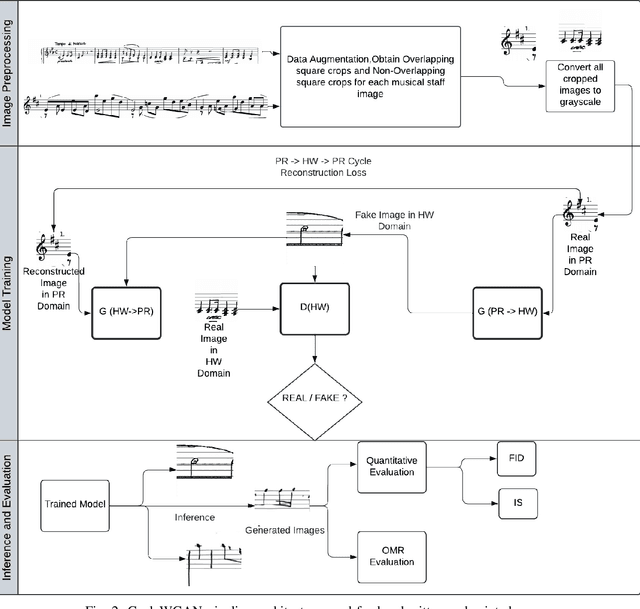
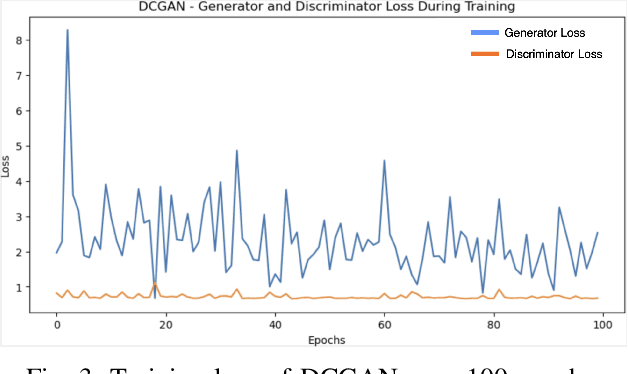
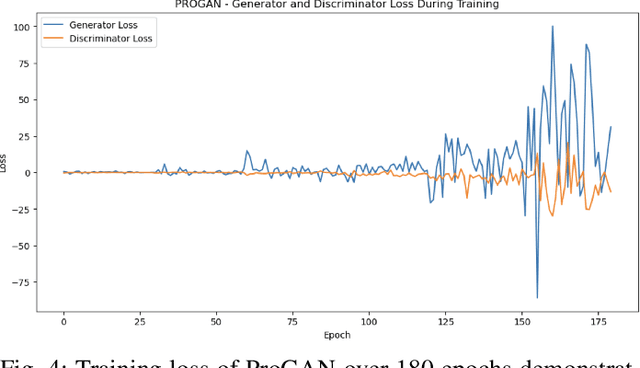
The generation of handwritten music sheets is a crucial step toward enhancing Optical Music Recognition (OMR) systems, which rely on large and diverse datasets for optimal performance. However, handwritten music sheets, often found in archives, present challenges for digitisation due to their fragility, varied handwriting styles, and image quality. This paper addresses the data scarcity problem by applying Generative Adversarial Networks (GANs) to synthesise realistic handwritten music sheets. We provide a comprehensive evaluation of three GAN models - DCGAN, ProGAN, and CycleWGAN - comparing their ability to generate diverse and high-quality handwritten music images. The proposed CycleWGAN model, which enhances style transfer and training stability, significantly outperforms DCGAN and ProGAN in both qualitative and quantitative evaluations. CycleWGAN achieves superior performance, with an FID score of 41.87, an IS of 2.29, and a KID of 0.05, making it a promising solution for improving OMR systems.
Low-Data Classification of Historical Music Manuscripts: A Few-Shot Learning Approach
Nov 25, 2024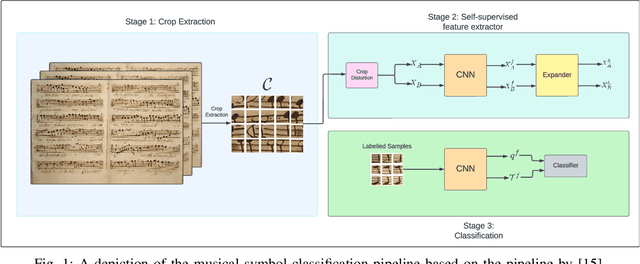

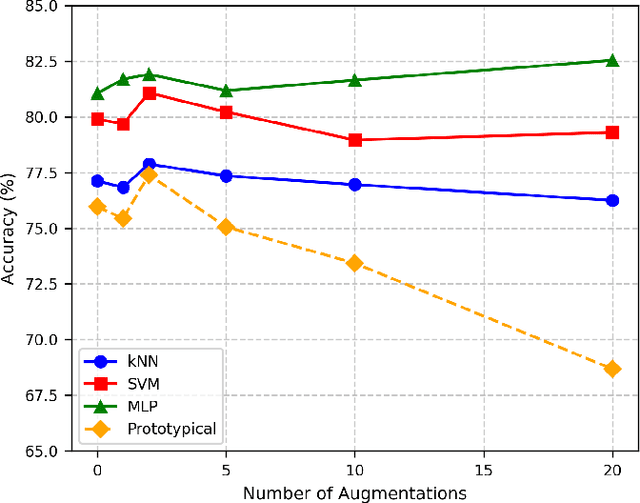
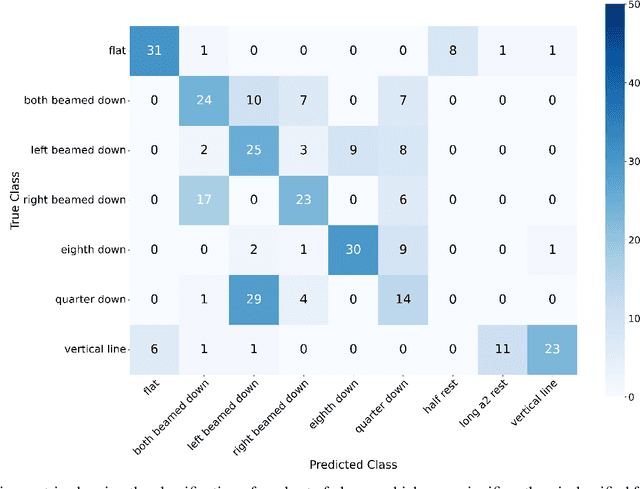
In this paper, we explore the intersection of technology and cultural preservation by developing a self-supervised learning framework for the classification of musical symbols in historical manuscripts. Optical Music Recognition (OMR) plays a vital role in digitising and preserving musical heritage, but historical documents often lack the labelled data required by traditional methods. We overcome this challenge by training a neural-based feature extractor on unlabelled data, enabling effective classification with minimal samples. Key contributions include optimising crop preprocessing for a self-supervised Convolutional Neural Network and evaluating classification methods, including SVM, multilayer perceptrons, and prototypical networks. Our experiments yield an accuracy of 87.66\%, showcasing the potential of AI-driven methods to ensure the survival of historical music for future generations through advanced digital archiving techniques.
Proceedings of the 6th International Workshop on Reading Music Systems
Nov 24, 2024The International Workshop on Reading Music Systems (WoRMS) is a workshop that tries to connect researchers who develop systems for reading music, such as in the field of Optical Music Recognition, with other researchers and practitioners that could benefit from such systems, like librarians or musicologists. The relevant topics of interest for the workshop include, but are not limited to: Music reading systems; Optical music recognition; Datasets and performance evaluation; Image processing on music scores; Writer identification; Authoring, editing, storing and presentation systems for music scores; Multi-modal systems; Novel input-methods for music to produce written music; Web-based Music Information Retrieval services; Applications and projects; Use-cases related to written music. These are the proceedings of the 6th International Workshop on Reading Music Systems, held Online on November 22nd 2024.
Foundation Models for Music: A Survey
Aug 27, 2024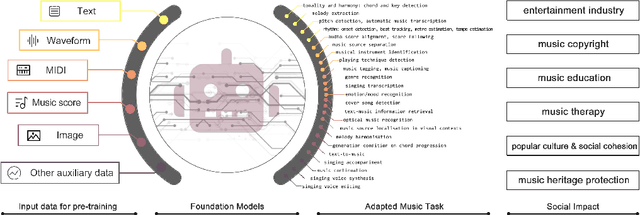

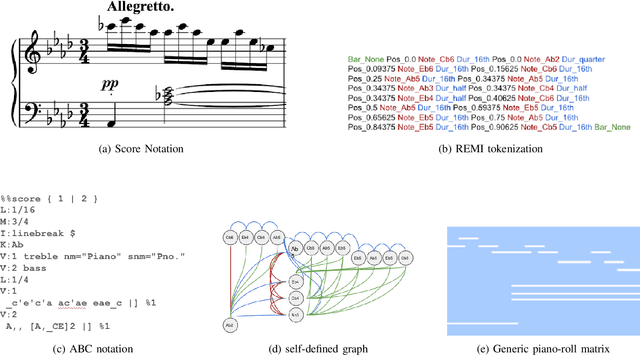
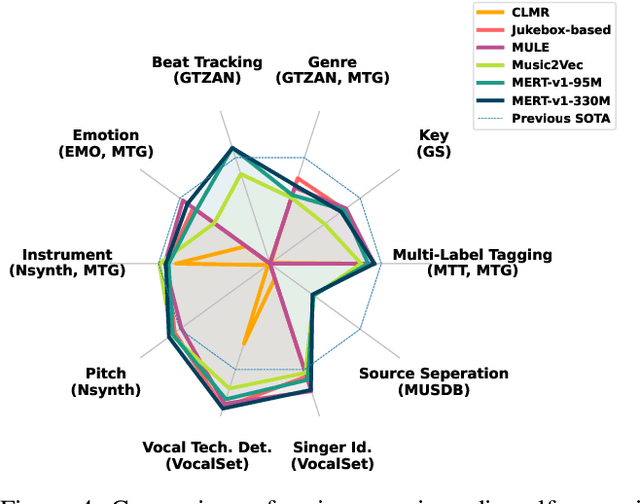
In recent years, foundation models (FMs) such as large language models (LLMs) and latent diffusion models (LDMs) have profoundly impacted diverse sectors, including music. This comprehensive review examines state-of-the-art (SOTA) pre-trained models and foundation models in music, spanning from representation learning, generative learning and multimodal learning. We first contextualise the significance of music in various industries and trace the evolution of AI in music. By delineating the modalities targeted by foundation models, we discover many of the music representations are underexplored in FM development. Then, emphasis is placed on the lack of versatility of previous methods on diverse music applications, along with the potential of FMs in music understanding, generation and medical application. By comprehensively exploring the details of the model pre-training paradigm, architectural choices, tokenisation, finetuning methodologies and controllability, we emphasise the important topics that should have been well explored, like instruction tuning and in-context learning, scaling law and emergent ability, as well as long-sequence modelling etc. A dedicated section presents insights into music agents, accompanied by a thorough analysis of datasets and evaluations essential for pre-training and downstream tasks. Finally, by underscoring the vital importance of ethical considerations, we advocate that following research on FM for music should focus more on such issues as interpretability, transparency, human responsibility, and copyright issues. The paper offers insights into future challenges and trends on FMs for music, aiming to shape the trajectory of human-AI collaboration in the music realm.
Knowledge Discovery in Optical Music Recognition: Enhancing Information Retrieval with Instance Segmentation
Aug 27, 2024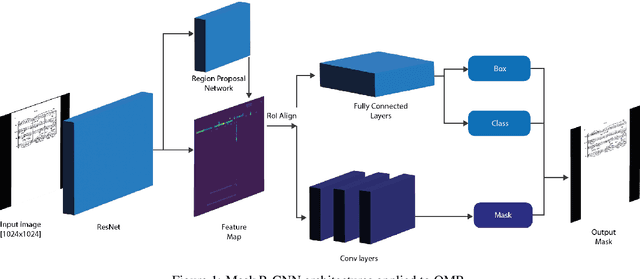
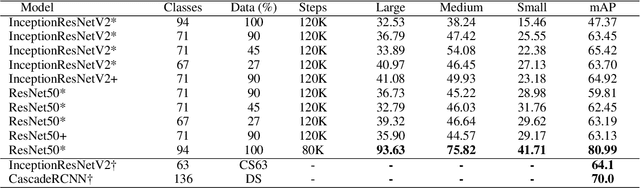
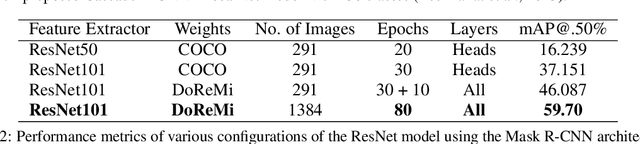
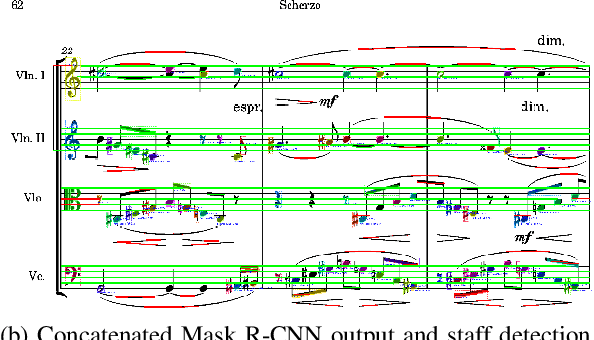
Optical Music Recognition (OMR) automates the transcription of musical notation from images into machine-readable formats like MusicXML, MEI, or MIDI, significantly reducing the costs and time of manual transcription. This study explores knowledge discovery in OMR by applying instance segmentation using Mask R-CNN to enhance the detection and delineation of musical symbols in sheet music. Unlike Optical Character Recognition (OCR), OMR must handle the intricate semantics of Common Western Music Notation (CWMN), where symbol meanings depend on shape, position, and context. Our approach leverages instance segmentation to manage the density and overlap of musical symbols, facilitating more precise information retrieval from music scores. Evaluations on the DoReMi and MUSCIMA++ datasets demonstrate substantial improvements, with our method achieving a mean Average Precision (mAP) of up to 59.70\% in dense symbol environments, achieving comparable results to object detection. Furthermore, using traditional computer vision techniques, we add a parallel step for staff detection to infer the pitch for the recognised symbols. This study emphasises the role of pixel-wise segmentation in advancing accurate music symbol recognition, contributing to knowledge discovery in OMR. Our findings indicate that instance segmentation provides more precise representations of musical symbols, particularly in densely populated scores, advancing OMR technology. We make our implementation, pre-processing scripts, trained models, and evaluation results publicly available to support further research and development.
Proceedings of the 5th International Workshop on Reading Music Systems
Nov 07, 2023The International Workshop on Reading Music Systems (WoRMS) is a workshop that tries to connect researchers who develop systems for reading music, such as in the field of Optical Music Recognition, with other researchers and practitioners that could benefit from such systems, like librarians or musicologists. The relevant topics of interest for the workshop include, but are not limited to: Music reading systems; Optical music recognition; Datasets and performance evaluation; Image processing on music scores; Writer identification; Authoring, editing, storing and presentation systems for music scores; Multi-modal systems; Novel input-methods for music to produce written music; Web-based Music Information Retrieval services; Applications and projects; Use-cases related to written music. These are the proceedings of the 5th International Workshop on Reading Music Systems, held in Milan, Italy on Nov. 4th 2023.
Proceedings of the 4th International Workshop on Reading Music Systems
Nov 23, 2022The International Workshop on Reading Music Systems (WoRMS) is a workshop that tries to connect researchers who develop systems for reading music, such as in the field of Optical Music Recognition, with other researchers and practitioners that could benefit from such systems, like librarians or musicologists. The relevant topics of interest for the workshop include, but are not limited to: Music reading systems; Optical music recognition; Datasets and performance evaluation; Image processing on music scores; Writer identification; Authoring, editing, storing and presentation systems for music scores; Multi-modal systems; Novel input-methods for music to produce written music; Web-based Music Information Retrieval services; Applications and projects; Use-cases related to written music. These are the proceedings of the 4th International Workshop on Reading Music Systems, held online on Nov. 18th 2022.
DoReMi: First glance at a universal OMR dataset
Jul 16, 2021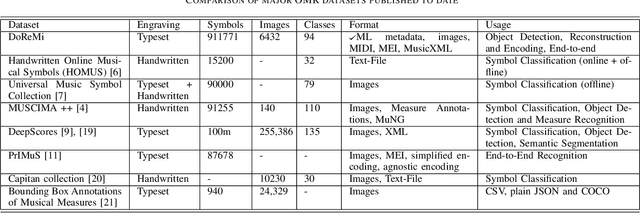
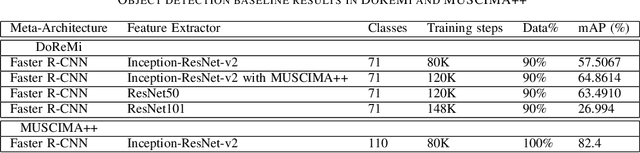
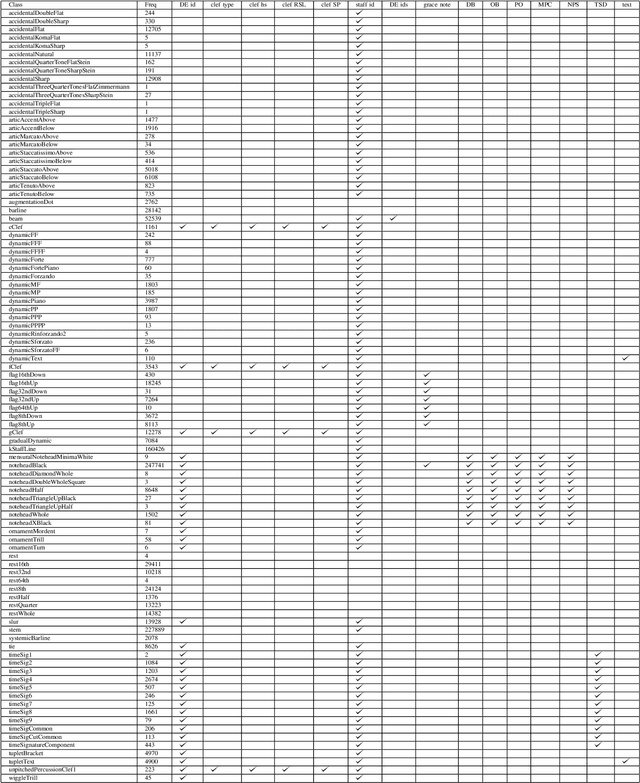
The main challenges of Optical Music Recognition (OMR) come from the nature of written music, its complexity and the difficulty of finding an appropriate data representation. This paper provides a first look at DoReMi, an OMR dataset that addresses these challenges, and a baseline object detection model to assess its utility. Researchers often approach OMR following a set of small stages, given that existing data often do not satisfy broader research. We examine the possibility of changing this tendency by presenting more metadata. Our approach complements existing research; hence DoReMi allows harmonisation with two existing datasets, DeepScores and MUSCIMA++. DoReMi was generated using a music notation software and includes over 6400 printed sheet music images with accompanying metadata useful in OMR research. Our dataset provides OMR metadata, MIDI, MEI, MusicXML and PNG files, each aiding a different stage of OMR. We obtain 64% mean average precision (mAP) in object detection using half of the data. Further work includes re-iterating through the creation process to satisfy custom OMR models. While we do not assume to have solved the main challenges in OMR, this dataset opens a new course of discussions that would ultimately aid that goal.
Optical Music Recognition: State of the Art and Major Challenges
Jun 22, 2020

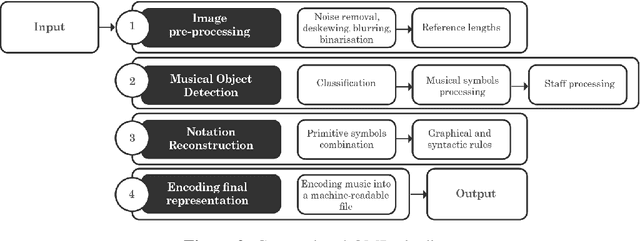
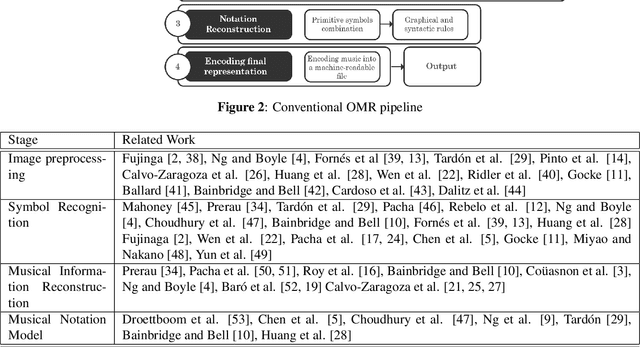
Optical Music Recognition (OMR) is concerned with transcribing sheet music into a machine-readable format. The transcribed copy should allow musicians to compose, play and edit music by taking a picture of a music sheet. Complete transcription of sheet music would also enable more efficient archival. OMR facilitates examining sheet music statistically or searching for patterns of notations, thus helping use cases in digital musicology too. Recently, there has been a shift in OMR from using conventional computer vision techniques towards a deep learning approach. In this paper, we review relevant works in OMR, including fundamental methods and significant outcomes, and highlight different stages of the OMR pipeline. These stages often lack standard input and output representation and standardised evaluation. Therefore, comparing different approaches and evaluating the impact of different processing methods can become rather complex. This paper provides recommendations for future work, addressing some of the highlighted issues and represents a position in furthering this important field of research.