 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Automatic Differentiation of Direct Form Digital Filters
Nov 18, 2025We introduce a general formulation for automatic differentiation through direct form filters, yielding a closed-form backpropagation that includes initial condition gradients. The result is a single expression that can represent both the filter and its gradients computation while supporting parallelism. C++/CUDA implementations in PyTorch achieve at least 1000x speedup over naive Python implementations and consistently run fastest on the GPU. For the low-order filters commonly used in practice, exact time-domain filtering with analytical gradients outperforms the frequency-domain method in terms of speed. The source code is available at https://github.com/yoyolicoris/philtorch.
Audio synthesizer inversion in symmetric parameter spaces with approximately equivariant flow matching
Jun 08, 2025Many audio synthesizers can produce the same signal given different parameter configurations, meaning the inversion from sound to parameters is an inherently ill-posed problem. We show that this is largely due to intrinsic symmetries of the synthesizer, and focus in particular on permutation invariance. First, we demonstrate on a synthetic task that regressing point estimates under permutation symmetry degrades performance, even when using a permutation-invariant loss function or symmetry-breaking heuristics. Then, viewing equivalent solutions as modes of a probability distribution, we show that a conditional generative model substantially improves performance. Further, acknowledging the invariance of the implicit parameter distribution, we find that performance is further improved by using a permutation equivariant continuous normalizing flow. To accommodate intricate symmetries in real synthesizers, we also propose a relaxed equivariance strategy that adaptively discovers relevant symmetries from data. Applying our method to Surge XT, a full-featured open source synthesizer used in real world audio production, we find our method outperforms regression and generative baselines across audio reconstruction metrics.
Improving Inference-Time Optimisation for Vocal Effects Style Transfer with a Gaussian Prior
May 16, 2025Style Transfer with Inference-Time Optimisation (ST-ITO) is a recent approach for transferring the applied effects of a reference audio to a raw audio track. It optimises the effect parameters to minimise the distance between the style embeddings of the processed audio and the reference. However, this method treats all possible configurations equally and relies solely on the embedding space, which can lead to unrealistic or biased results. We address this pitfall by introducing a Gaussian prior derived from a vocal preset dataset, DiffVox, over the parameter space. The resulting optimisation is equivalent to maximum-a-posteriori estimation. Evaluations on vocal effects transfer on the MedleyDB dataset show significant improvements across metrics compared to baselines, including a blind audio effects estimator, nearest-neighbour approaches, and uncalibrated ST-ITO. The proposed calibration reduces parameter mean squared error by up to 33% and matches the reference style better. Subjective evaluations with 16 participants confirm our method's superiority, especially in limited data regimes. This work demonstrates how incorporating prior knowledge in inference time enhances audio effects transfer, paving the way for more effective and realistic audio processing systems.
Mamba-Diffusion Model with Learnable Wavelet for Controllable Symbolic Music Generation
May 06, 2025The recent surge in the popularity of diffusion models for image synthesis has attracted new attention to their potential for generation tasks in other domains. However, their applications to symbolic music generation remain largely under-explored because symbolic music is typically represented as sequences of discrete events and standard diffusion models are not well-suited for discrete data. We represent symbolic music as image-like pianorolls, facilitating the use of diffusion models for the generation of symbolic music. Moreover, this study introduces a novel diffusion model that incorporates our proposed Transformer-Mamba block and learnable wavelet transform. Classifier-free guidance is utilised to generate symbolic music with target chords. Our evaluation shows that our method achieves compelling results in terms of music quality and controllability, outperforming the strong baseline in pianoroll generation. Our code is available at https://github.com/jinchengzhanggg/proffusion.
DiffVox: A Differentiable Model for Capturing and Analysing Professional Effects Distributions
Apr 20, 2025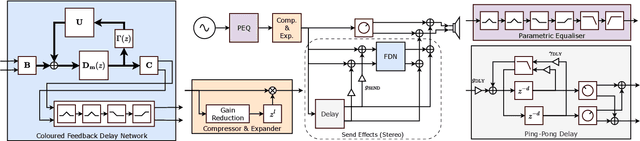

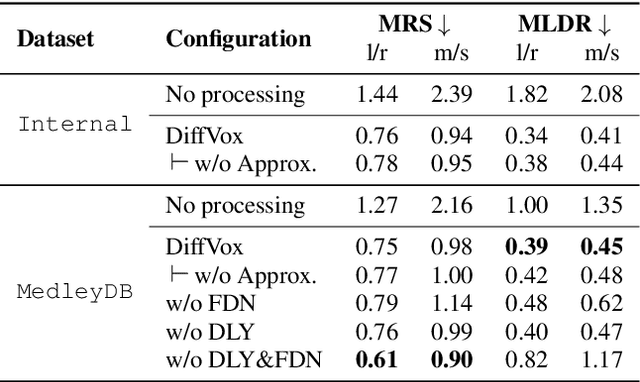
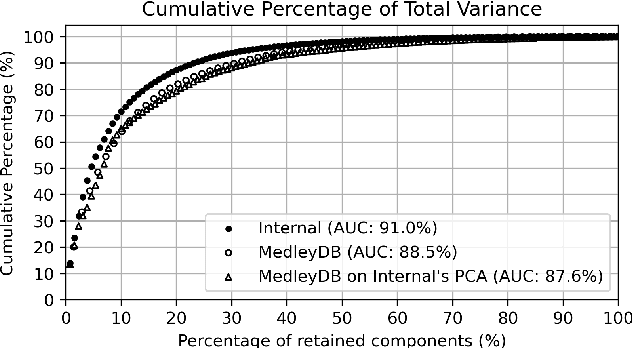
This study introduces a novel and interpretable model, DiffVox, for matching vocal effects in music production. DiffVox, short for ``Differentiable Vocal Fx", integrates parametric equalisation, dynamic range control, delay, and reverb with efficient differentiable implementations to enable gradient-based optimisation for parameter estimation. Vocal presets are retrieved from two datasets, comprising 70 tracks from MedleyDB and 365 tracks from a private collection. Analysis of parameter correlations highlights strong relationships between effects and parameters, such as the high-pass and low-shelf filters often behaving together to shape the low end, and the delay time correlates with the intensity of the delayed signals. Principal component analysis reveals connections to McAdams' timbre dimensions, where the most crucial component modulates the perceived spaciousness while the secondary components influence spectral brightness. Statistical testing confirms the non-Gaussian nature of the parameter distribution, highlighting the complexity of the vocal effects space. These initial findings on the parameter distributions set the foundation for future research in vocal effects modelling and automatic mixing. Our source code and datasets are accessible at https://github.com/SonyResearch/diffvox.
Leave-One-EquiVariant: Alleviating invariance-related information loss in contrastive music representations
Dec 25, 2024



Contrastive learning has proven effective in self-supervised musical representation learning, particularly for Music Information Retrieval (MIR) tasks. However, reliance on augmentation chains for contrastive view generation and the resulting learnt invariances pose challenges when different downstream tasks require sensitivity to certain musical attributes. To address this, we propose the Leave One EquiVariant (LOEV) framework, which introduces a flexible, task-adaptive approach compared to previous work by selectively preserving information about specific augmentations, allowing the model to maintain task-relevant equivariances. We demonstrate that LOEV alleviates information loss related to learned invariances, improving performance on augmentation related tasks and retrieval without sacrificing general representation quality. Furthermore, we introduce a variant of LOEV, LOEV++, which builds a disentangled latent space by design in a self-supervised manner, and enables targeted retrieval based on augmentation related attributes.
Composers' Evaluations of an AI Music Tool: Insights for Human-Centred Design
Dec 14, 2024



We present a study that explores the role of user-centred design in developing Generative AI (GenAI) tools for music composition. Through semi-structured interviews with professional composers, we gathered insights on a novel generative model for creating variations, highlighting concerns around trust, transparency, and ethical design. The findings helped form a feedback loop, guiding improvements to the model that emphasised traceability, transparency and explainability. They also revealed new areas for innovation, including novel features for controllability and research questions on the ethical and practical implementation of GenAI models.
Exploring Transformer-Based Music Overpainting for Jazz Piano Variations
Dec 05, 2024
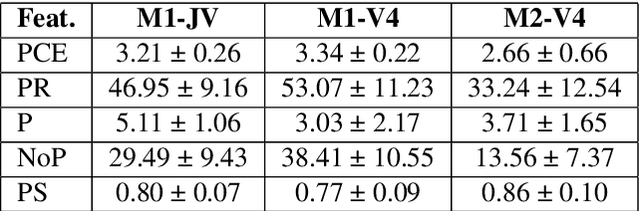
This paper explores transformer-based models for music overpainting, focusing on jazz piano variations. Music overpainting generates new variations while preserving the melodic and harmonic structure of the input. Existing approaches are limited by small datasets, restricting scalability and diversity. We introduce VAR4000, a subset of a larger dataset for jazz piano performances, consisting of 4,352 training pairs. Using a semi-automatic pipeline, we evaluate two transformer configurations on VAR4000, comparing their performance with the smaller JAZZVAR dataset. Preliminary results show promising improvements in generalisation and performance with the larger dataset configuration, highlighting the potential of transformer models to scale effectively for music overpainting on larger and more diverse datasets.
Tidal MerzA: Combining affective modelling and autonomous code generation through Reinforcement Learning
Sep 12, 2024This paper presents Tidal-MerzA, a novel system designed for collaborative performances between humans and a machine agent in the context of live coding, specifically focusing on the generation of musical patterns. Tidal-MerzA fuses two foundational models: ALCAA (Affective Live Coding Autonomous Agent) and Tidal Fuzz, a computational framework. By integrating affective modelling with computational generation, this system leverages reinforcement learning techniques to dynamically adapt music composition parameters within the TidalCycles framework, ensuring both affective qualities to the patterns and syntactical correctness. The development of Tidal-MerzA introduces two distinct agents: one focusing on the generation of mini-notation strings for musical expression, and another on the alignment of music with targeted affective states through reinforcement learning. This approach enhances the adaptability and creative potential of live coding practices and allows exploration of human-machine creative interactions. Tidal-MerzA advances the field of computational music generation, presenting a novel methodology for incorporating artificial intelligence into artistic practices.
Foundation Models for Music: A Survey
Aug 27, 2024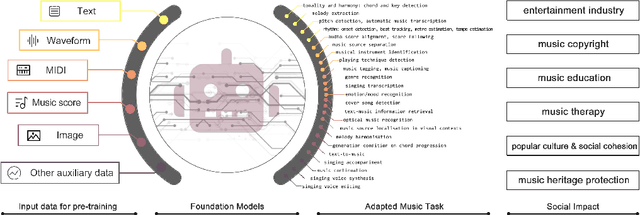

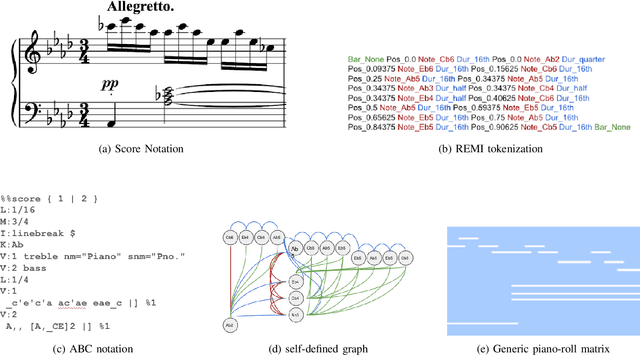
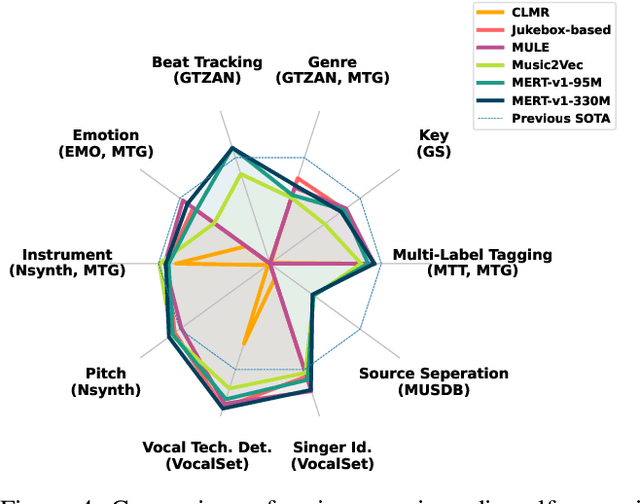
In recent years, foundation models (FMs) such as large language models (LLMs) and latent diffusion models (LDMs) have profoundly impacted diverse sectors, including music. This comprehensive review examines state-of-the-art (SOTA) pre-trained models and foundation models in music, spanning from representation learning, generative learning and multimodal learning. We first contextualise the significance of music in various industries and trace the evolution of AI in music. By delineating the modalities targeted by foundation models, we discover many of the music representations are underexplored in FM development. Then, emphasis is placed on the lack of versatility of previous methods on diverse music applications, along with the potential of FMs in music understanding, generation and medical application. By comprehensively exploring the details of the model pre-training paradigm, architectural choices, tokenisation, finetuning methodologies and controllability, we emphasise the important topics that should have been well explored, like instruction tuning and in-context learning, scaling law and emergent ability, as well as long-sequence modelling etc. A dedicated section presents insights into music agents, accompanied by a thorough analysis of datasets and evaluations essential for pre-training and downstream tasks. Finally, by underscoring the vital importance of ethical considerations, we advocate that following research on FM for music should focus more on such issues as interpretability, transparency, human responsibility, and copyright issues. The paper offers insights into future challenges and trends on FMs for music, aiming to shape the trajectory of human-AI collaboration in the music realm.