 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio synthesizer inversion in symmetric parameter spaces with approximately equivariant flow matching
Jun 08, 2025Many audio synthesizers can produce the same signal given different parameter configurations, meaning the inversion from sound to parameters is an inherently ill-posed problem. We show that this is largely due to intrinsic symmetries of the synthesizer, and focus in particular on permutation invariance. First, we demonstrate on a synthetic task that regressing point estimates under permutation symmetry degrades performance, even when using a permutation-invariant loss function or symmetry-breaking heuristics. Then, viewing equivalent solutions as modes of a probability distribution, we show that a conditional generative model substantially improves performance. Further, acknowledging the invariance of the implicit parameter distribution, we find that performance is further improved by using a permutation equivariant continuous normalizing flow. To accommodate intricate symmetries in real synthesizers, we also propose a relaxed equivariance strategy that adaptively discovers relevant symmetries from data. Applying our method to Surge XT, a full-featured open source synthesizer used in real world audio production, we find our method outperforms regression and generative baselines across audio reconstruction metrics.
DiffVox: A Differentiable Model for Capturing and Analysing Professional Effects Distributions
Apr 20, 2025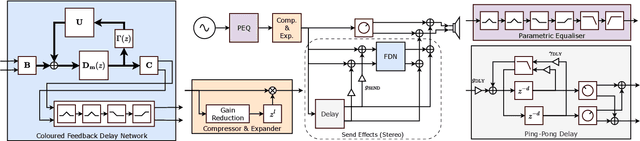

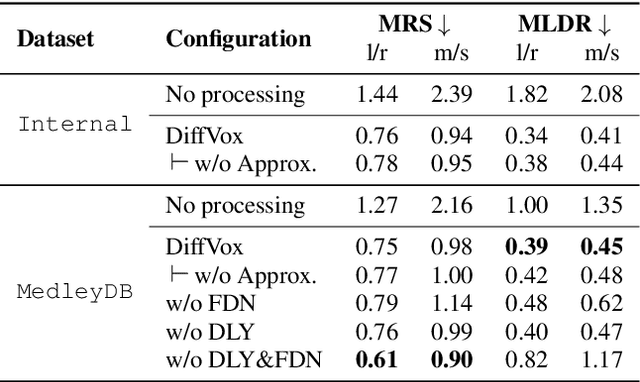
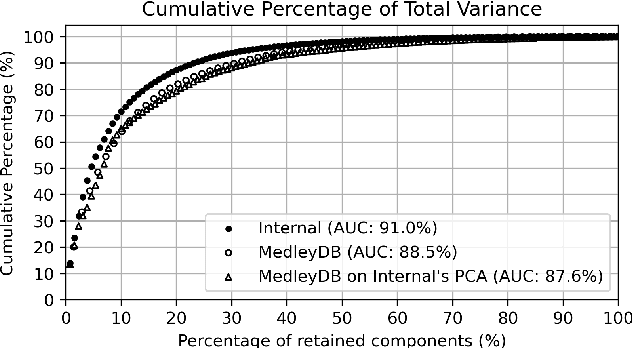
This study introduces a novel and interpretable model, DiffVox, for matching vocal effects in music production. DiffVox, short for ``Differentiable Vocal Fx", integrates parametric equalisation, dynamic range control, delay, and reverb with efficient differentiable implementations to enable gradient-based optimisation for parameter estimation. Vocal presets are retrieved from two datasets, comprising 70 tracks from MedleyDB and 365 tracks from a private collection. Analysis of parameter correlations highlights strong relationships between effects and parameters, such as the high-pass and low-shelf filters often behaving together to shape the low end, and the delay time correlates with the intensity of the delayed signals. Principal component analysis reveals connections to McAdams' timbre dimensions, where the most crucial component modulates the perceived spaciousness while the secondary components influence spectral brightness. Statistical testing confirms the non-Gaussian nature of the parameter distribution, highlighting the complexity of the vocal effects space. These initial findings on the parameter distributions set the foundation for future research in vocal effects modelling and automatic mixing. Our source code and datasets are accessible at https://github.com/SonyResearch/diffvox.
A Review of Differentiable Digital Signal Processing for Music & Speech Synthesis
Aug 29, 2023The term "differentiable digital signal processing" describes a family of techniques in which loss function gradients are backpropagated through digital signal processors, facilitating their integration into neural networks. This article surveys the literature on differentiable audio signal processing, focusing on its use in music & speech synthesis. We catalogue applications to tasks including music performance rendering, sound matching, and voice transformation, discussing the motivations for and implications of the use of this methodology. This is accompanied by an overview of digital signal processing operations that have been implemented differentiably. Finally, we highlight open challenges, including optimisation pathologies, robustness to real-world conditions, and design trade-offs, and discuss directions for future research.
The Responsibility Problem in Neural Networks with Unordered Targets
Apr 19, 2023We discuss the discontinuities that arise when mapping unordered objects to neural network outputs of fixed permutation, referred to as the responsibility problem. Prior work has proved the existence of the issue by identifying a single discontinuity. Here, we show that discontinuities under such models are uncountably infinite, motivating further research into neural networks for unordered data.
Rigid-Body Sound Synthesis with Differentiable Modal Resonators
Oct 28, 2022



Physical models of rigid bodies are used for sound synthesis in applications from virtual environments to music production. Traditional methods such as modal synthesis often rely on computationally expensive numerical solvers, while recent deep learning approaches are limited by post-processing of their results. In this work we present a novel end-to-end framework for training a deep neural network to generate modal resonators for a given 2D shape and material, using a bank of differentiable IIR filters. We demonstrate our method on a dataset of synthetic objects, but train our model using an audio-domain objective, paving the way for physically-informed synthesisers to be learned directly from recordings of real-world objects.
Sinusoidal Frequency Estimation by Gradient Descent
Oct 26, 2022
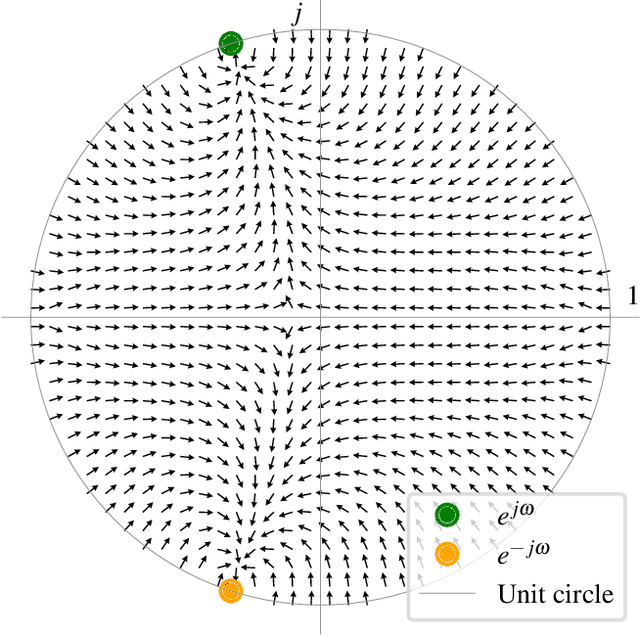
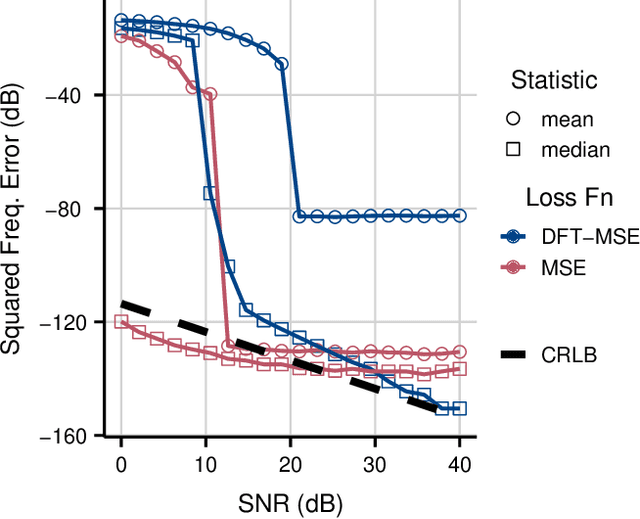
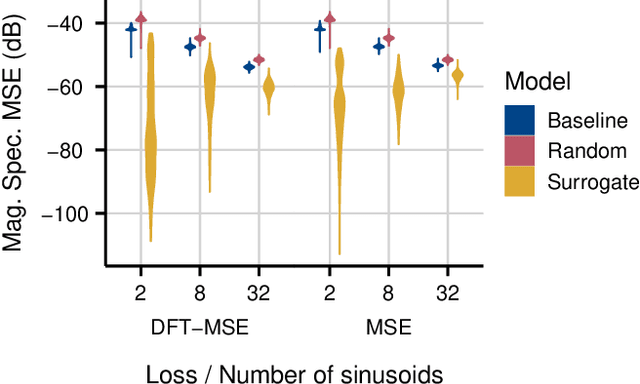
Sinusoidal parameter estimation is a fundamental task in applications from spectral analysis to time-series forecasting. Estimating the sinusoidal frequency parameter by gradient descent is, however, often impossible as the error function is non-convex and densely populated with local minima. The growing family of differentiable signal processing methods has therefore been unable to tune the frequency of oscillatory components, preventing their use in a broad range of applications. This work presents a technique for joint sinusoidal frequency and amplitude estimation using the Wirtinger derivatives of a complex exponential surrogate and any first order gradient-based optimizer, enabling end to-end training of neural network controllers for unconstrained sinusoidal models.
Neural Waveshaping Synthesis
Jul 27, 2021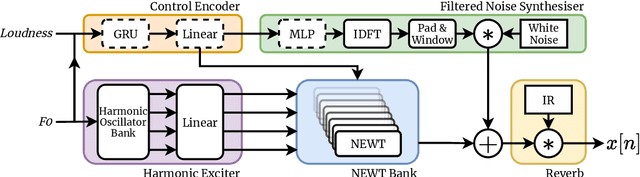
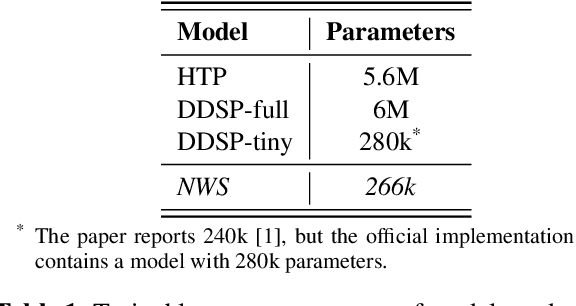
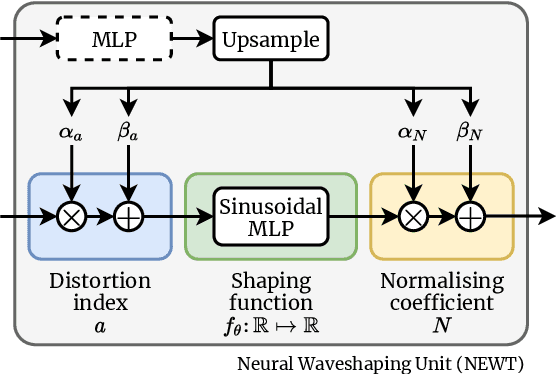
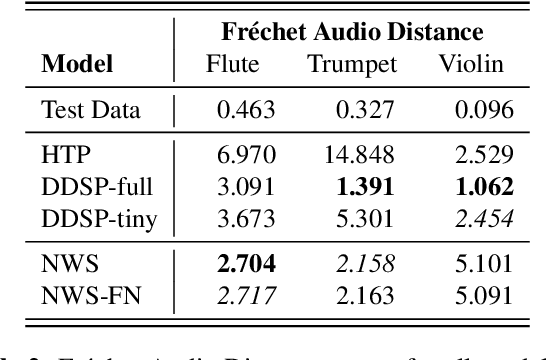
We present the Neural Waveshaping Unit (NEWT): a novel, lightweight, fully causal approach to neural audio synthesis which operates directly in the waveform domain, with an accompanying optimisation (FastNEWT) for efficient CPU inference. The NEWT uses time-distributed multilayer perceptrons with periodic activations to implicitly learn nonlinear transfer functions that encode the characteristics of a target timbre. Once trained, a NEWT can produce complex timbral evolutions by simple affine transformations of its input and output signals. We paired the NEWT with a differentiable noise synthesiser and reverb and found it capable of generating realistic musical instrument performances with only 260k total model parameters, conditioned on F0 and loudness features. We compared our method to state-of-the-art benchmarks with a multi-stimulus listening test and the Fr\'echet Audio Distance and found it performed competitively across the tested timbral domains. Our method significantly outperformed the benchmarks in terms of generation speed, and achieved real-time performance on a consumer CPU, both with and without FastNEWT, suggesting it is a viable basis for future creative sound design tools.