 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Automatic Differentiation of Direct Form Digital Filters
Nov 18, 2025We introduce a general formulation for automatic differentiation through direct form filters, yielding a closed-form backpropagation that includes initial condition gradients. The result is a single expression that can represent both the filter and its gradients computation while supporting parallelism. C++/CUDA implementations in PyTorch achieve at least 1000x speedup over naive Python implementations and consistently run fastest on the GPU. For the low-order filters commonly used in practice, exact time-domain filtering with analytical gradients outperforms the frequency-domain method in terms of speed. The source code is available at https://github.com/yoyolicoris/philtorch.
Improving Inference-Time Optimisation for Vocal Effects Style Transfer with a Gaussian Prior
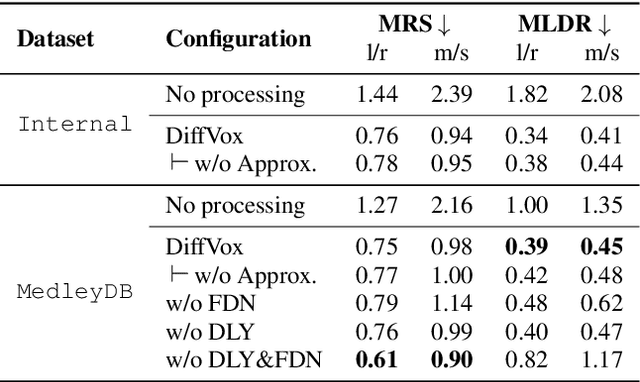
May 16, 2025Style Transfer with Inference-Time Optimisation (ST-ITO) is a recent approach for transferring the applied effects of a reference audio to a raw audio track. It optimises the effect parameters to minimise the distance between the style embeddings of the processed audio and the reference. However, this method treats all possible configurations equally and relies solely on the embedding space, which can lead to unrealistic or biased results. We address this pitfall by introducing a Gaussian prior derived from a vocal preset dataset, DiffVox, over the parameter space. The resulting optimisation is equivalent to maximum-a-posteriori estimation. Evaluations on vocal effects transfer on the MedleyDB dataset show significant improvements across metrics compared to baselines, including a blind audio effects estimator, nearest-neighbour approaches, and uncalibrated ST-ITO. The proposed calibration reduces parameter mean squared error by up to 33% and matches the reference style better. Subjective evaluations with 16 participants confirm our method's superiority, especially in limited data regimes. This work demonstrates how incorporating prior knowledge in inference time enhances audio effects transfer, paving the way for more effective and realistic audio processing systems.
DiffVox: A Differentiable Model for Capturing and Analysing Professional Effects Distributions
Apr 20, 2025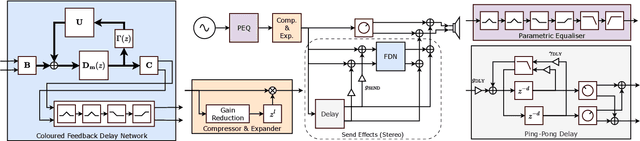

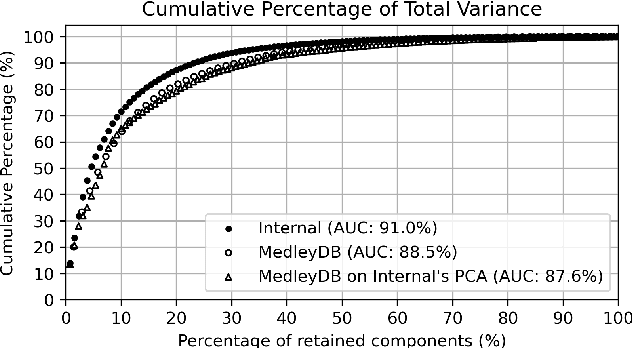
This study introduces a novel and interpretable model, DiffVox, for matching vocal effects in music production. DiffVox, short for ``Differentiable Vocal Fx", integrates parametric equalisation, dynamic range control, delay, and reverb with efficient differentiable implementations to enable gradient-based optimisation for parameter estimation. Vocal presets are retrieved from two datasets, comprising 70 tracks from MedleyDB and 365 tracks from a private collection. Analysis of parameter correlations highlights strong relationships between effects and parameters, such as the high-pass and low-shelf filters often behaving together to shape the low end, and the delay time correlates with the intensity of the delayed signals. Principal component analysis reveals connections to McAdams' timbre dimensions, where the most crucial component modulates the perceived spaciousness while the secondary components influence spectral brightness. Statistical testing confirms the non-Gaussian nature of the parameter distribution, highlighting the complexity of the vocal effects space. These initial findings on the parameter distributions set the foundation for future research in vocal effects modelling and automatic mixing. Our source code and datasets are accessible at https://github.com/SonyResearch/diffvox.
Differentiable Time-Varying Linear Prediction in the Context of End-to-End Analysis-by-Synthesis
Jun 07, 2024



Training the linear prediction (LP) operator end-to-end for audio synthesis in modern deep learning frameworks is slow due to its recursive formulation. In addition, frame-wise approximation as an acceleration method cannot generalise well to test time conditions where the LP is computed sample-wise. Efficient differentiable sample-wise LP for end-to-end training is the key to removing this barrier. We generalise the efficient time-invariant LP implementation from the GOLF vocoder to time-varying cases. Combining this with the classic source-filter model, we show that the improved GOLF learns LP coefficients and reconstructs the voice better than its frame-wise counterparts. Moreover, in our listening test, synthesised outputs from GOLF scored higher in quality ratings than the state-of-the-art differentiable WORLD vocoder.
Time-of-arrival Estimation and Phase Unwrapping of Head-related Transfer Functions With Integer Linear Programming
May 10, 2024In binaural audio synthesis, aligning head-related impulse responses (HRIRs) in time has been an important pre-processing step, enabling accurate spatial interpolation and efficient data compression. The maximum correlation time delay between spatially nearby HRIRs has previously been used to get accurate and smooth alignment by solving a matrix equation in which the solution has the minimum Euclidean distance to the time delay. However, the Euclidean criterion could lead to an over-smoothing solution in practice. In this paper, we solve the smoothing issue by formulating the task as solving an integer linear programming problem equivalent to minimising an $L^1$-norm. Moreover, we incorporate 1) the cross-correlation of inter-aural HRIRs, and 2) HRIRs with their minimum-phase responses to have more reference measurements for optimisation. We show the proposed method can get more accurate alignments than the Euclidean-based method by comparing the spectral reconstruction loss of time-aligned HRIRs using spherical harmonics representation on seven HRIRs consisting of human and dummy heads. The extra correlation features and the $L^1$-norm are also beneficial in extremely noisy conditions. In addition, this method can be applied to phase unwrapping of head-related transfer functions, where the unwrapped phase could be a compact feature for downstream tasks.
Differentiable All-pole Filters for Time-varying Audio Systems
Apr 12, 2024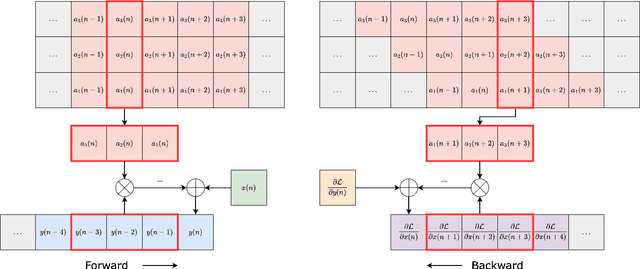

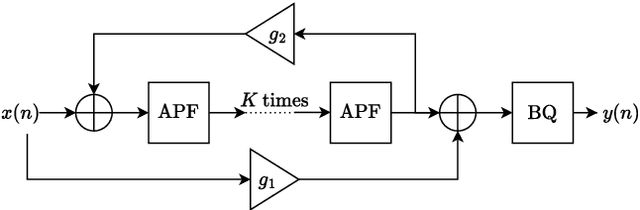

Infinite impulse response filters are an essential building block of many time-varying audio systems, such as audio effects and synthesisers. However, their recursive structure impedes end-to-end training of these systems using automatic differentiation. Although non-recursive filter approximations like frequency sampling and frame-based processing have been proposed and widely used in previous works, they cannot accurately reflect the gradient of the original system. We alleviate this difficulty by re-expressing a time-varying all-pole filter to backpropagate the gradients through itself, so the filter implementation is not bound to the technical limitations of automatic differentiation frameworks. This implementation can be employed within any audio system containing filters with poles for efficient gradient evaluation. We demonstrate its training efficiency and expressive capabilities for modelling real-world dynamic audio systems on a phaser, time-varying subtractive synthesiser, and feed-forward compressor. We make our code available and provide the trained audio effect and synth models in a VST plugin at https://christhetree.github.io/all_pole_filters/.
Zero-Shot Duet Singing Voices Separation with Diffusion Models
Nov 13, 2023In recent studies, diffusion models have shown promise as priors for solving audio inverse problems. These models allow us to sample from the posterior distribution of a target signal given an observed signal by manipulating the diffusion process. However, when separating audio sources of the same type, such as duet singing voices, the prior learned by the diffusion process may not be sufficient to maintain the consistency of the source identity in the separated audio. For example, the singer may change from one to another occasionally. Tackling this problem will be useful for separating sources in a choir, or a mixture of multiple instruments with similar timbre, without acquiring large amounts of paired data. In this paper, we examine this problem in the context of duet singing voices separation, and propose a method to enforce the coherency of singer identity by splitting the mixture into overlapping segments and performing posterior sampling in an auto-regressive manner, conditioning on the previous segment. We evaluate the proposed method on the MedleyVox dataset and show that the proposed method outperforms the naive posterior sampling baseline. Our source code and the pre-trained model are publicly available at https://github.com/yoyololicon/duet-svs-diffusion.
TorchAudio 2.1: Advancing speech recognition, self-supervised learning, and audio processing components for PyTorch
Oct 27, 2023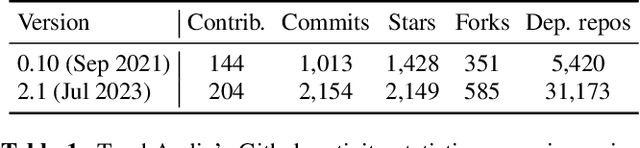


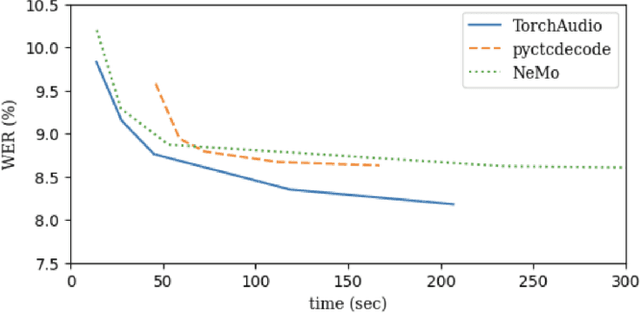
TorchAudio is an open-source audio and speech processing library built for PyTorch. It aims to accelerate the research and development of audio and speech technologies by providing well-designed, easy-to-use, and performant PyTorch components. Its contributors routinely engage with users to understand their needs and fulfill them by developing impactful features. Here, we survey TorchAudio's development principles and contents and highlight key features we include in its latest version (2.1): self-supervised learning pre-trained pipelines and training recipes, high-performance CTC decoders, speech recognition models and training recipes, advanced media I/O capabilities, and tools for performing forced alignment, multi-channel speech enhancement, and reference-less speech assessment. For a selection of these features, through empirical studies, we demonstrate their efficacy and show that they achieve competitive or state-of-the-art performance.
Singing Voice Synthesis Using Differentiable LPC and Glottal-Flow-Inspired Wavetables
Jul 13, 2023



This paper introduces GlOttal-flow LPC Filter (GOLF), a novel method for singing voice synthesis (SVS) that exploits the physical characteristics of the human voice using differentiable digital signal processing. GOLF employs a glottal model as the harmonic source and IIR filters to simulate the vocal tract, resulting in an interpretable and efficient approach. We show it is competitive with state-of-the-art singing voice vocoders, requiring fewer synthesis parameters and less memory to train, and runs an order of magnitude faster for inference. Additionally, we demonstrate that GOLF can model the phase components of the human voice, which has immense potential for rendering and analysing singing voices in a differentiable manner. Our results highlight the effectiveness of incorporating the physical properties of the human voice mechanism into SVS and underscore the advantages of signal-processing-based approaches, which offer greater interpretability and efficiency in synthesis. Audio samples are available at https://yoyololicon.github.io/golf-demo/.
Conditioning and Sampling in Variational Diffusion Models for Speech Super-resolution
Oct 27, 2022



Recently, diffusion models (DMs) have been increasingly used in audio processing tasks, including speech super-resolution (SR), which aims to restore high-frequency content given low-resolution speech utterances. This is commonly achieved by conditioning the network of noise predictor with low-resolution audio. In this paper, we propose a novel sampling algorithm that communicates the information of the low-resolution audio via the reverse sampling process of DMs. The proposed method can be a drop-in replacement for the vanilla sampling process and can significantly improve the performance of the existing works. Moreover, by coupling the proposed sampling method with an unconditional DM, i.e., a DM with no auxiliary inputs to its noise predictor, we can generalize it to a wide range of SR setups. We also attain state-of-the-art results on the VCTK Multi-Speaker benchmark with this novel formulation.