 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCRAPL: Scattering Transform with Random Paths for Machine Learning
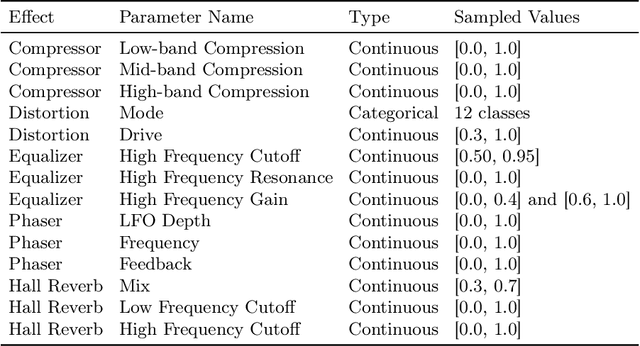
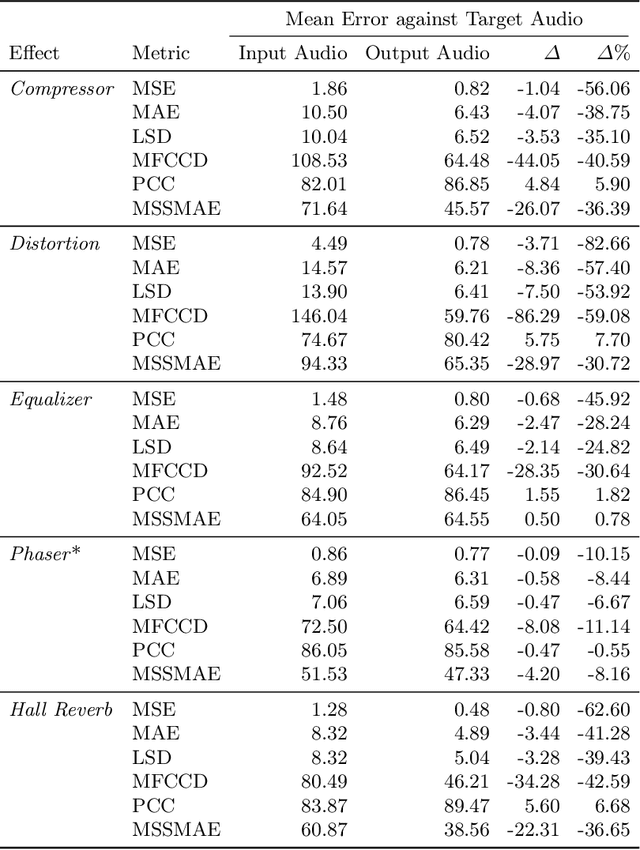
Feb 11, 2026The Euclidean distance between wavelet scattering transform coefficients (known as paths) provides informative gradients for perceptual quality assessment of deep inverse problems in computer vision, speech, and audio processing. However, these transforms are computationally expensive when employed as differentiable loss functions for stochastic gradient descent due to their numerous paths, which significantly limits their use in neural network training. Against this problem, we propose "Scattering transform with Random Paths for machine Learning" (SCRAPL): a stochastic optimization scheme for efficient evaluation of multivariable scattering transforms. We implement SCRAPL for the joint time-frequency scattering transform (JTFS) which demodulates spectrotemporal patterns at multiple scales and rates, allowing a fine characterization of intermittent auditory textures. We apply SCRAPL to differentiable digital signal processing (DDSP), specifically, unsupervised sound matching of a granular synthesizer and the Roland TR-808 drum machine. We also propose an initialization heuristic based on importance sampling, which adapts SCRAPL to the perceptual content of the dataset, improving neural network convergence and evaluation performance. We make our code and audio samples available and provide SCRAPL as a Python package.
Neutone SDK: An Open Source Framework for Neural Audio Processing
Aug 12, 2025


Neural audio processing has unlocked novel methods of sound transformation and synthesis, yet integrating deep learning models into digital audio workstations (DAWs) remains challenging due to real-time / neural network inference constraints and the complexities of plugin development. In this paper, we introduce the Neutone SDK: an open source framework that streamlines the deployment of PyTorch-based neural audio models for both real-time and offline applications. By encapsulating common challenges such as variable buffer sizes, sample rate conversion, delay compensation, and control parameter handling within a unified, model-agnostic interface, our framework enables seamless interoperability between neural models and host plugins while allowing users to work entirely in Python. We provide a technical overview of the interfaces needed to accomplish this, as well as the corresponding SDK implementations. We also demonstrate the SDK's versatility across applications such as audio effect emulation, timbre transfer, and sample generation, as well as its adoption by researchers, educators, companies, and artists alike. The Neutone SDK is available at https://github.com/Neutone/neutone_sdk
Differentiable All-pole Filters for Time-varying Audio Systems
Apr 12, 2024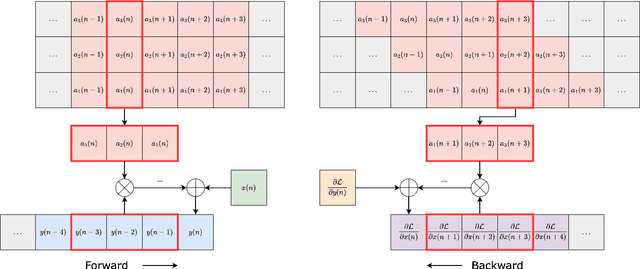

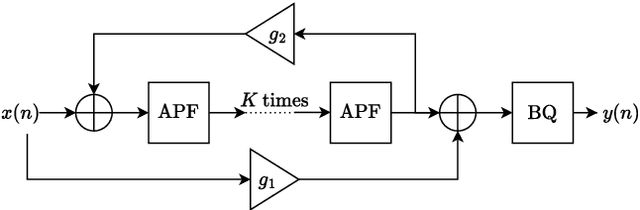

Infinite impulse response filters are an essential building block of many time-varying audio systems, such as audio effects and synthesisers. However, their recursive structure impedes end-to-end training of these systems using automatic differentiation. Although non-recursive filter approximations like frequency sampling and frame-based processing have been proposed and widely used in previous works, they cannot accurately reflect the gradient of the original system. We alleviate this difficulty by re-expressing a time-varying all-pole filter to backpropagate the gradients through itself, so the filter implementation is not bound to the technical limitations of automatic differentiation frameworks. This implementation can be employed within any audio system containing filters with poles for efficient gradient evaluation. We demonstrate its training efficiency and expressive capabilities for modelling real-world dynamic audio systems on a phaser, time-varying subtractive synthesiser, and feed-forward compressor. We make our code available and provide the trained audio effect and synth models in a VST plugin at https://christhetree.github.io/all_pole_filters/.
Modulation Extraction for LFO-driven Audio Effects
May 22, 2023



Low frequency oscillator (LFO) driven audio effects such as phaser, flanger, and chorus, modify an input signal using time-varying filters and delays, resulting in characteristic sweeping or widening effects. It has been shown that these effects can be modeled using neural networks when conditioned with the ground truth LFO signal. However, in most cases, the LFO signal is not accessible and measurement from the audio signal is nontrivial, hindering the modeling process. To address this, we propose a framework capable of extracting arbitrary LFO signals from processed audio across multiple digital audio effects, parameter settings, and instrument configurations. Since our system imposes no restrictions on the LFO signal shape, we demonstrate its ability to extract quasiperiodic, combined, and distorted modulation signals that are relevant to effect modeling. Furthermore, we show how coupling the extraction model with a simple processing network enables training of end-to-end black-box models of unseen analog or digital LFO-driven audio effects using only dry and wet audio pairs, overcoming the need to access the audio effect or internal LFO signal. We make our code available and provide the trained audio effect models in a real-time VST plugin.
SerumRNN: Step by Step Audio VST Effect Programming
Apr 08, 2021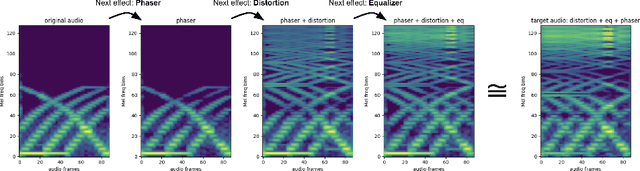

Learning to program an audio production VST synthesizer is a time consuming process, usually obtained through inefficient trial and error and only mastered after years of experience. As an educational and creative tool for sound designers, we propose SerumRNN: a system that provides step-by-step instructions for applying audio effects to change a user's input audio towards a desired sound. We apply our system to Xfer Records Serum: currently one of the most popular and complex VST synthesizers used by the audio production community. Our results indicate that SerumRNN is consistently able to provide useful feedback for a variety of different audio effects and synthesizer presets. We demonstrate the benefits of using an iterative system and show that SerumRNN learns to prioritize effects and can discover more efficient effect order sequences than a variety of baselines.
* Audio samples of the system can be listened to at bit.ly/serum_rnn
White-box Audio VST Effect Programming
Feb 05, 2021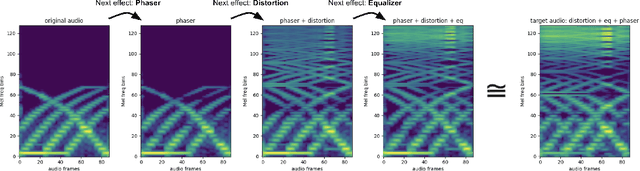
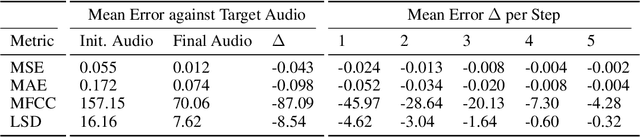
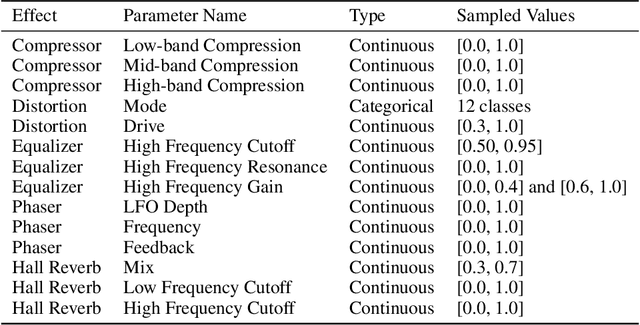
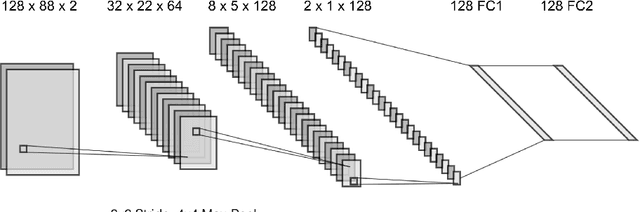
Learning to program an audio production VST plugin is a time consuming process, usually obtained through inefficient trial and error and only mastered after extensive user experience. We propose a white-box, iterative system that provides step-by-step instructions for applying audio effects to change a user's audio signal towards a desired sound. We apply our system to Xfer Records Serum: currently one of the most popular and complex VST synthesizers used by the audio production community. Our results indicate that our system is consistently able to provide useful feedback for a variety of different audio effects and synthesizer presets.
* The latest version of the system is to appear at EvoMUSART 2021 as a full paper. Audio samples of the latest system can be listened to at https://bit.ly/serum_rnn
Using Aspect Extraction Approaches to Generate Review Summaries and User Profiles
Apr 23, 2018
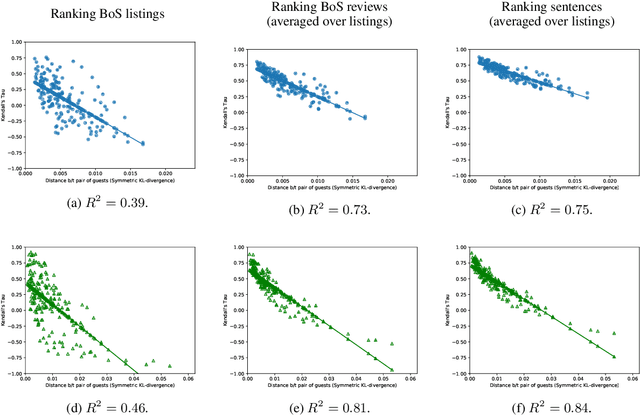


Reviews of products or services on Internet marketplace websites contain a rich amount of information. Users often wish to survey reviews or review snippets from the perspective of a certain aspect, which has resulted in a large body of work on aspect identification and extraction from such corpora. In this work, we evaluate a newly-proposed neural model for aspect extraction on two practical tasks. The first is to extract canonical sentences of various aspects from reviews, and is judged by human evaluators against alternatives. A $k$-means baseline does remarkably well in this setting. The second experiment focuses on the suitability of the recovered aspect distributions to represent users by the reviews they have written. Through a set of review reranking experiments, we find that aspect-based profiles can largely capture notions of user preferences, by showing that divergent users generate markedly different review rankings.
Classification and Retrieval of Digital Pathology Scans: A New Dataset
May 22, 2017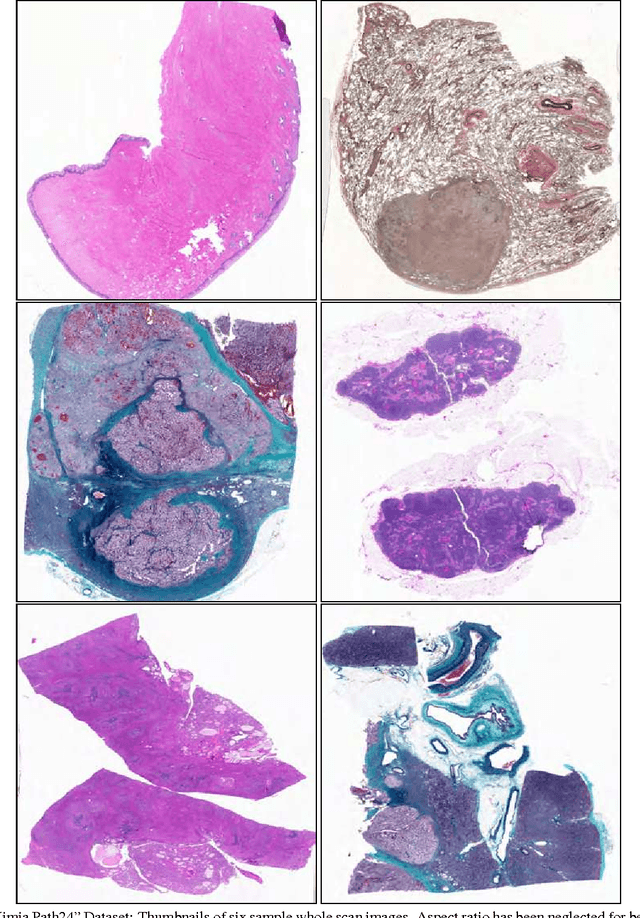


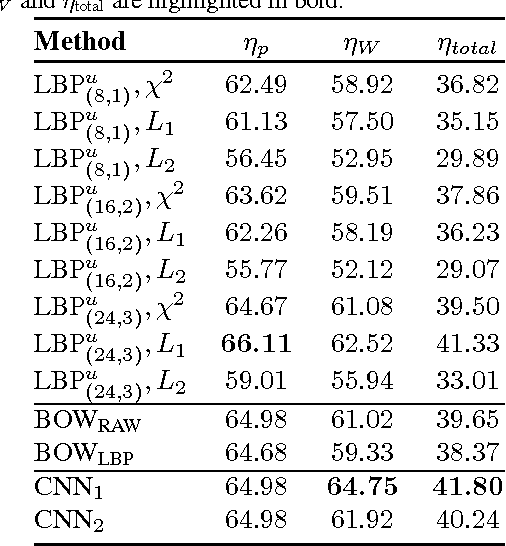
In this paper, we introduce a new dataset, \textbf{Kimia Path24}, for image classification and retrieval in digital pathology. We use the whole scan images of 24 different tissue textures to generate 1,325 test patches of size 1000$\times$1000 (0.5mm$\times$0.5mm). Training data can be generated according to preferences of algorithm designer and can range from approximately 27,000 to over 50,000 patches if the preset parameters are adopted. We propose a compound patch-and-scan accuracy measurement that makes achieving high accuracies quite challenging. In addition, we set the benchmarking line by applying LBP, dictionary approach and convolutional neural nets (CNNs) and report their results. The highest accuracy was 41.80\% for CNN.
Barcodes for Medical Image Retrieval Using Autoencoded Radon Transform
Sep 16, 2016
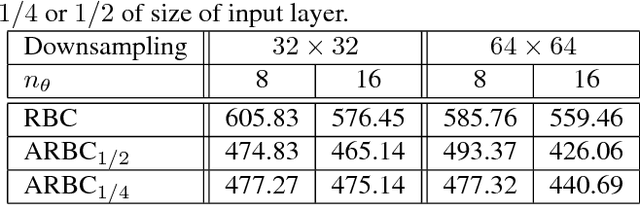
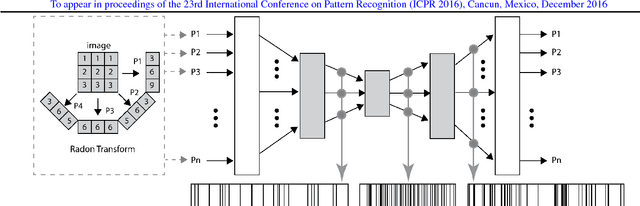

Using content-based binary codes to tag digital images has emerged as a promising retrieval technology. Recently, Radon barcodes (RBCs) have been introduced as a new binary descriptor for image search. RBCs are generated by binarization of Radon projections and by assembling them into a vector, namely the barcode. A simple local thresholding has been suggested for binarization. In this paper, we put forward the idea of "autoencoded Radon barcodes". Using images in a training dataset, we autoencode Radon projections to perform binarization on outputs of hidden layers. We employed the mini-batch stochastic gradient descent approach for the training. Each hidden layer of the autoencoder can produce a barcode using a threshold determined based on the range of the logistic function used. The compressing capability of autoencoders apparently reduces the redundancies inherent in Radon projections leading to more accurate retrieval results. The IRMA dataset with 14,410 x-ray images is used to validate the performance of the proposed method. The experimental results, containing comparison with RBCs, SURF and BRISK, show that autoencoded Radon barcode (ARBC) has the capacity to capture important information and to learn richer representations resulting in lower retrieval errors for image retrieval measured with the accuracy of the first hit only.