 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Training for Models of Information Cascades
Dec 11, 2018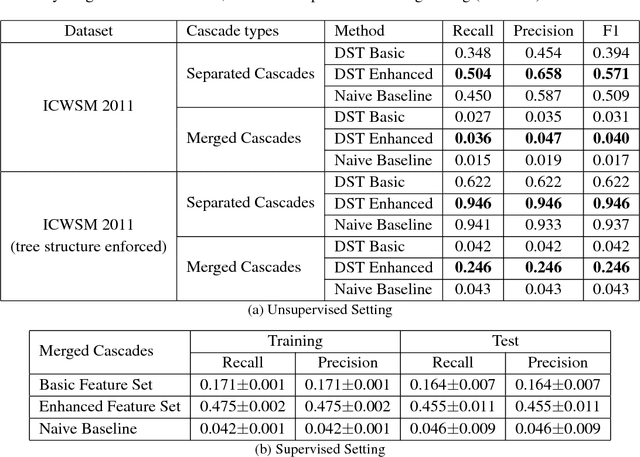
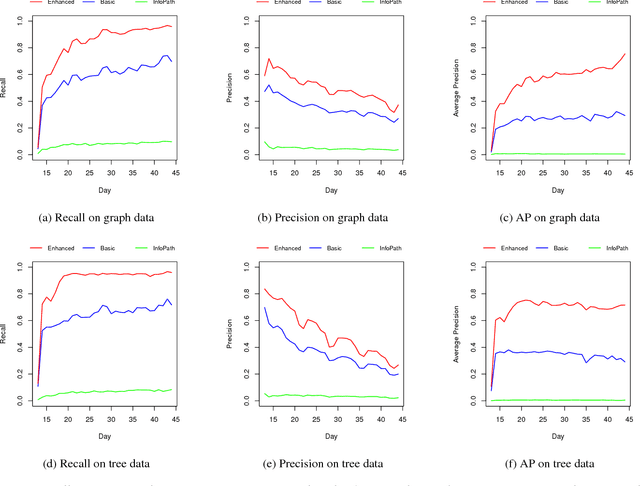
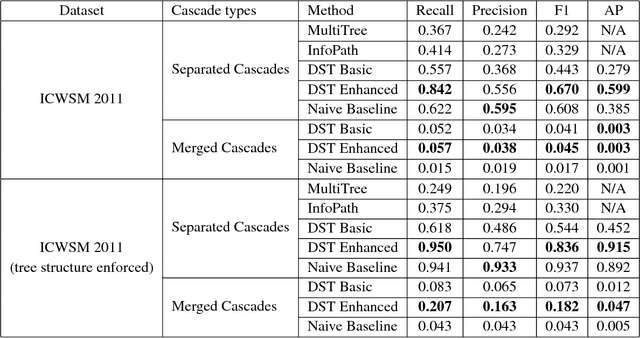
This paper proposes a model of information cascades as directed spanning trees (DSTs) over observed documents. In addition, we propose a contrastive training procedure that exploits partial temporal ordering of node infections in lieu of labeled training links. This combination of model and unsupervised training makes it possible to improve on models that use infection times alone and to exploit arbitrary features of the nodes and of the text content of messages in information cascades. With only basic node and time lag features similar to previous models, the DST model achieves performance with unsupervised training comparable to strong baselines on a blog network inference task. Unsupervised training with additional content features achieves significantly better results, reaching half the accuracy of a fully supervised model.